开窗函数的应用场景
请看下面的例子,姑且叫这个表为dw.fct_sales,它有三个字段如下。我们只取里面三个字段月份、门店、销量。

好多时候,当我们计算完每月每个门店的单量,还希望加一列,各个月份的汇总,如果我们能根据月份把数据分成两组,把每组的销量累计起来,放到最后一行,我们的需求不就实现了嘛!幸运的是个大 sql 平台都实现了这种功能。
开窗,开窗,先让我们搞清楚什么是窗口。窗口就是一个字段的数据范围,例如:
 我们上面的例子中,因为月份字段中只有两个不同的值,所以只能分成两个窗口(感觉还挺像两个个窗户的)了,如果按照
我们上面的例子中,因为月份字段中只有两个不同的值,所以只能分成两个窗口(感觉还挺像两个个窗户的)了,如果按照月份+门店呢?那只能是 16 个 窗口了。
有了窗口,实际上我们可以在一个细粒度上的结果集上,进行分组。让后再对分组中的值进行 sum 、avg、count、first_value、last_value、lag、lead、row_number、dense_rank、rank 等操作。所以分组不仅仅是 group by 的专属,开窗函数也可以的。
下面就让我们进入具体的语法吧!
开窗函数的语法
先看一个基本的:
select year_mon
,dimShopID
,amt
,sum(amt) over(partition by year_mon ) as mon_amt
from (
select
left(concat(dimDateID,''),6) as year_mon
, dimShopID
,sum(AMT) as amt
from dw.fct_sales
where dimShopID in (33 , 34)
and left(concat(dimDateID,''),6) in ( '201706','201707')
group by left(concat(dimDateID,''),6)
,dimShopID
) as q1
q1 这个子查询是为了把上面提到的数据实例拼凑起来,关键是看sum(amt) over(partition by year_mon ) 这一句。让我们分解来看看。
sum(amt) 这个相信大家知道是聚合函数,重点是看后面的over(partition by year_mon ),当 sum 遇到 over 以后,sum 就进化了,由聚合函数进化成开窗函数。over 这个单词,从语义上有“跨越”的意思,聪明的你,一定猜到了,它是想说明要跨越的窗口大小,接下来问题来了,窗口的大小怎么定义呢?
其实,窗口的定义就是 over 里面的内容了,partition 从单词语义上解释是分区的意思,其实就是分组。partition by 就是根据哪个字段作为分组。所以把over(partition by year_mon ) ,翻译成人话就是,根据 year_mon 分组,并且把每个窗口里面的字段 amt 进行求和操作。
窗口定义
上面我们讲了分区,下面让我讲讲真正的窗口吧。请看下面的例子:
select ID_1 ,
SUM(ID_1) over(ORDER BY ID_2) default_sum,
SUM(ID_1) over(ORDER BY ID_2 RANGE BETWEEN unbounded preceding AND CURRENT ROW) range_unbound_sum,
SUM(ID_1) over(ORDER BY ID_2 ROWS BETWEEN unbounded preceding AND CURRENT ROW) rows_unbound_sum,
SUM(ID_1) over(ORDER BY ID_2 RANGE BETWEEN 1 preceding AND 2 following) range_sum,
SUM(ID_1) over(ORDER BY ID_2 ROWS BETWEEN 1 preceding AND 2 following) rows_sum
from (
SELECT (CASE
WHEN id IN (1, 2) THEN
1
WHEN id IN (4, 5) THEN
6
ELSE
id
END) as ID_1,
(CASE
WHEN id IN (1, 2) THEN
1
WHEN id IN (4, 5) THEN
6
ELSE
id
END) as ID_2
FROM (
select 1 as id
union all
select 2 as id
union all
select 3 as id
union all
select 4 as id
union all
select 5 as id
union all
select 6 as id
union all
select 7 as id
union all
select 8 as id
union all
select 9 as id
union all
select 10 as id
) as a
) as b
哈哈,看着挺多的,但是其实比较简单。简单讲一下:
- 首先,使用 union all 的方法,早一些测试数据(1-10 的列表),也就是 a 表。
- 然后,使用 case when 将 1、2 转换成 1 , 然后将 4、5 转成 6 。
- 然后,我写了 5 种 开窗。
我们得到下面的结果:
 我们可以得到一下结论:
我们可以得到一下结论:
从上面的例子可知:
1、窗口子句必须和order by 子句同时使用,且如果指定了order by 子句未指定窗口子句,则默认为RANGE BETWEEN unbounded preceding AND CURRENT ROW,如上例结果集中的defult_sum等于range_unbound_sum;
2、如果分析函数没有指定ORDER BY子句,也就不存在ROWS/RANGE窗口的计算;
3、range是逻辑窗口,是指定当前行对应值的范围取值,列数不固定,只要行值在范围内,对应列都包含在内,如上例中range_sum(即range 1 preceing and 2 following)例的分析结果:
当id=1时,是sum为1-1<=id<=1+2 的和,即sum=1+1+3=5(取id为1,1,3);
当id=3时,是sum为3-1<=id<=3+2 的和,即sum=3(取id为3);
当id=6时,是sum为6-1<=id<=6+2 的和,即sum=6+6+6+7+8=33(取id为6,6,6,7,8);
以此类推下去,结果如上例中所示。
4、rows是物理窗口,即根据order by 子句排序后,取的前N行及后N行的数据计算(与当前行的值无关,只与排序后的行号相关),如上例中rows_sum例结果,是取前1行和后2行数据的求和,分析上例rows_sum的结果:
当id=1(第一个1时)时,前一行没数,后二行分别是1和3,sum=1+1+3=5;
当id=3时,前一行id=1,后二行id都为6,则sum=1+3+6+6=16;
sum 、avg、count
上面的篇幅,我使用了 sum 对分组、排序、窗口进行讲解,那么 avg、count 和 over组合使用,原理上差不多,即在窗口里面进行求平均、计数。
select year_mon
,dimShopID
,amt
,count(dimShopID) over(partition by year_mon order by year_mon ) as shop_cnt
,avg(amt) over(partition by year_mon order by year_mon ) as avg_shop
from (
select
left(concat(dimDateID,''),6) as year_mon
, dimShopID
,sum(AMT) as amt
from dw.fct_sales
where dimShopID in (33 , 34)
and left(concat(dimDateID,''),6) in ( '201706','201707')
group by left(concat(dimDateID,''),6)
,dimShopID
) as q1
结果如下所示:

请看,在 06 月份 shop_cnt 字段对对 dimShopId 进行计数,结果为 2 ,确实我们只有两个门店编号,avg_shop 是对 06 月份的销售额取平均值,(2500766.9+2526779.1)= 5027546 ,5027546/2 = 2513773 。
first_value、last_value、lag、lead
- first_value:是在窗口里面取到第一个值
- last_value:是在窗口里面取到最后一个值
- lag 是取当前行的下 N 条数据,并且可以设置默认值
- lead 是取当前行的上 N 条数据,并且可以设置默认值
先来看看 first_value 和 last_value 吧。
select year_mon
,dimShopID
,amt
,first_value(amt) over(partition by dimShopID ) as first_amt
,last_value(amt) over(partition by dimShopID ) as last_amt
from (
select
left(concat(dimDateID,''),6) as year_mon
, dimShopID
,sum(AMT) as amt
from dw.fct_sales
where dimShopID in (33 , 34,35)
and left(concat(dimDateID,''),6) in ( '201706','201707','201708')
group by left(concat(dimDateID,''),6)
,dimShopID
) as q1
结果如下所示:
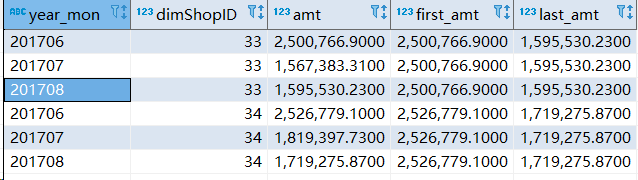
以 dimShopId = 33 为例,排在第一个的 amt 是 2500766.9 ,所以 first_amt 的值都为 2500766.9。相同的道理,last_amt 的值都是 1595530.23
下面看看看 lag/lead 怎么玩的。
select year_mon
,dimShopID
,amt
,lag(amt,1,0) over(partition by dimShopID ) as lag_amt
,lead(amt,1,0) over(partition by dimShopID ) as lead_amt
from (
select
left(concat(dimDateID,''),6) as year_mon
, dimShopID
,sum(AMT) as amt
from dw.fct_sales
where dimShopID in (33 , 34,35)
and left(concat(dimDateID,''),6) in ( '201706','201707','201708')
group by left(concat(dimDateID,''),6)
,dimShopID
) as q1
结果如下所示:
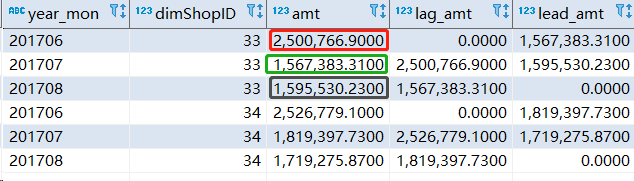
还是以 dimShopID=33 为例子,我们看到,lag_amt 的红色是第一行,他所对应的上一行的数据没有,我们设置了默认值为 0 。绿色是第二行,他的上一行数据是红色的数字。lead 的逻辑和 lag 的逻辑正好相反,聪明的你,肯定可以想到的。
row_number、dense_rank、rank
这是另外一个非常重要的部分——“序列”。序列一般使用在排名上,比如说,展示销售 TOP5 的商品。请看下面的例子。
select year_mon
,dimShopID
,amt
,row_number() over(order by amt desc ) as row_number_col
,rank() over( order by amt desc) as rank_col
,dense_rank() over(order by amt desc) as dense_rank_col
from (
select '201706' as year_mon
, '33' as dimShopID
, 2500766.9 as amt
union all
select '201706' as year_mon
, '33' as dimShopID
, 2500766.9 as amt
union all
select '201706' as year_mon
, '33' as dimShopID
, 1500766.9 as amt
union all
select '201706' as year_mon
, '33' as dimShopID
, 2100766.9 as amt
) as q1
结果如下所示:

还是以 dimShopID=33 为例,我们在结果中可以看到,我们已经按照 amt
对数据进行了排序, 我们可以总结一下知识点:
- row_number 的功能是为从第一行开始为每一行设置一个递增的数字
- rank 是排名,我们从例子中看到,相同的是相同的数字,而且到了第三行,变成了 3
- dense_rank 和 rank 的区别是序号不递增,大家可以看到 1 下面是 2 。
这样给大家抛砖引玉,学无止境,希望在实践中帮助大家。