版权声明:本文为博主原创文章,转载请声明本博主原创 https://blog.csdn.net/weixin_39381833/article/details/86772669
简介

快如闪电的集群计算
快速和通用的大规模数据处理技术
再HDFS之上做数据处理,没有数据存储功能
Speed
执行mr作业程序在内存中比Hadoop快100倍,磁盘上快10倍
Spark有着DAG(有向无环图)执行引擎,支持离散数据流和内存计算
Easy of use
java
scala
python
R
提供80多种高级操作用于并行操作App,可以使用scala等脚本语言进行交互式编程
Generality常规性
合成SQL 合成计算 复杂分析
Spark有自己的集群管理
有自己的集群计算技术
扩展了Hadoop的存储技术
包括交互式查询和流计算
主要内存的集群计算 提高计算速度
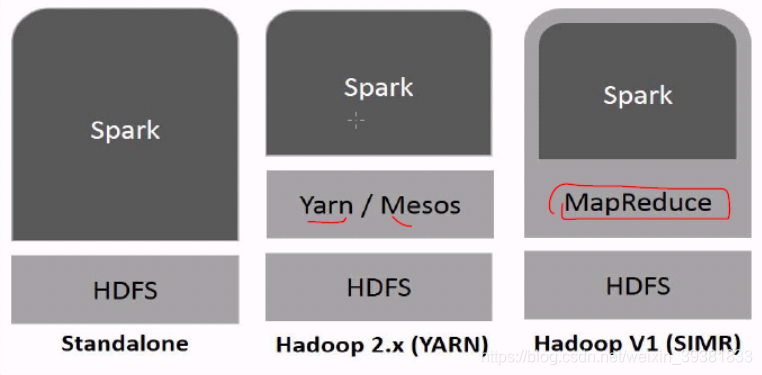
Spark三种部署模式
- Standalone
在HDFS之上,Spark和mr可以同时运行 覆盖到所有的job
- Hadoop yarn
在yarn之上运行,不需要预先安装或者要求root访问
有助于Spark和hadoop生态系统整合和集成 也允许其他组建在栈上运行
- Spark in MapReduce
Spark组建
- Spark Core(内核)
内核位于执行引擎之上,所有功能都在其上构建,提供了内存计算和外部存储系统的数据集饮用
- Spark SQL
在Spark core之上引入的一个新的数据集抽象(SchemaRDD),支持结构和半结构数据
- Spark Streaming
平衡Spark的内核的快速调度功能流分析
- ML lib
ML lib
Spark之上的机器学习框架
比基于磁盘技术的机器学习框架mahout快9倍
- GraphX
Spark之上的分布式图处理框架,提供了抽象运行时优化的API

Spark环境配置
通过Spark源代码使用maven进行编译安装
1.下载Spark源码
2.使用maven命令
a.启动maven本地仓库
b.使用maven编译时,需要扩大相应内存区的大小,否则出现内存溢出,编译失败
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"
c.使用如下命令进行编译
$>build/mvn -Pyarn -Phadoop-2.6 -Dhadoop.version=2.7.2 -DskipTests clean package
使用spark-2.4.0-bin-without-hadoop.tgz配置Spark环境变量