前言
决策树(Decision tress)是继朴素贝叶斯(NB),向量机(SVM)之后的另一种监督分类算法(supervised classification algorithm)。
决策树已经有几十年的历史,稳定性非常好。
和支持向量机类似,决策树也可以使用核技巧,将线性决策面转换为非线性的决策面。
文章目录如下:
- 前置知识
- 可线性分离的数据
- 多元线性问题
- 决策树 sklearn
- 自动驾驶集示例
- 决策树参数
- 熵(entropy)和信息增益(information gain)
- 数据杂质与熵
- 熵公式
- 信息增益
- 调整标准参数
- 偏差-方差困境
- DT的优缺点
前置知识
可线性分离的数据
有一个人喜欢冲浪,帆板冲浪需要满足两个条件,要有风,要有太阳,因为阴雨天并不是冲浪的好天气。下图列出去年每天的天气作为数据点,以风力(wind)为横轴,晴朗度(sun)为纵轴。红色数据点代表他不会在天气不够晴朗时冲浪,也不会在风力较弱时冲浪。蓝色数据点代表有风且天气晴朗,可以冲浪。
问题即:这份数据线性可分吗?
我们无法在下图中找到可以分隔这些数据的直线,因此它不是可线性分离的数据。

多元线性问题
我们可以用决策树一个接一个的处理上述的多元线性问题。
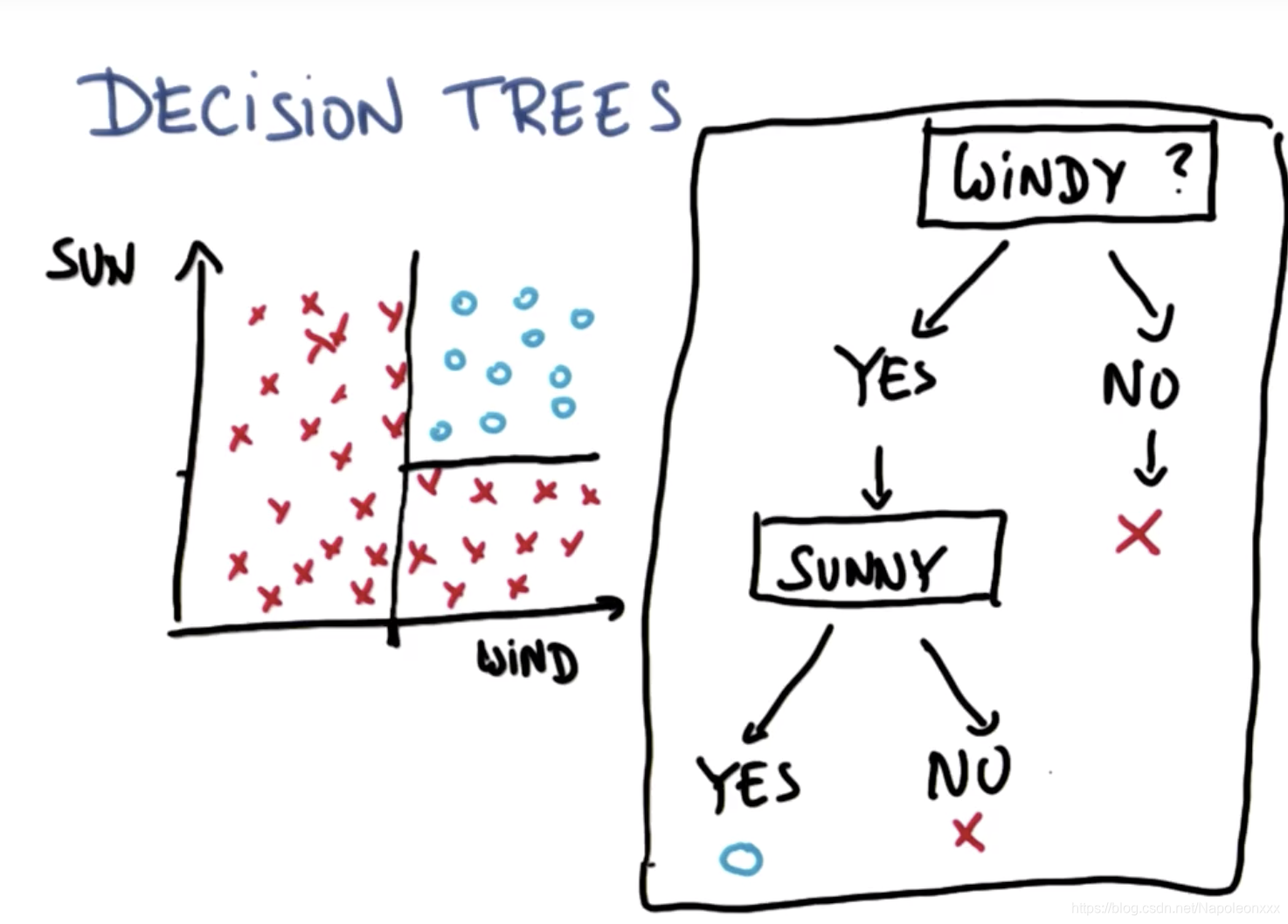
如上图所示,机器学习中的决策树学习就是通过树这种简单的数据结构对新数据进行分类。
决策树 sklearn
sklearn 代码举例
### ClassifyDecisionTree.py
def classify(features_train, labels_train):
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(random_state=0)
### fit the classifier on the training features and labels
clf.fit(features_train, labels_train)
### return the fit classifier
return clf
### DecisionTreeMain.py
from prep_terrain_data import makeTerrainData
from class_vis import prettyPicture, output_image
from ClassifyDecisionTree import classify
import numpy as np
import pylab as pl
features_train, labels_train, features_test, labels_test = makeTerrainData()
### the training data (features_train, labels_train) have both "fast" and "slow" points mixed
### in together--separate them so we can give them different colors in the scatterplot,
### and visually identify them
grade_fast = [features_train[ii][0] for ii in range(0, len(features_train)) if labels_train[ii] == 0]
bumpy_fast = [features_train[ii][1] for ii in range(0, len(features_train)) if labels_train[ii] == 0]
grade_slow = [features_train[ii][0] for ii in range(0, len(features_train)) if labels_train[ii] == 1]
bumpy_slow = [features_train[ii][1] for ii in range(0, len(features_train)) if labels_train[ii] == 1]
# You will need to complete this function imported from the ClassifyNB script.
# Be sure to change to that code tab to complete this quiz.
clf = classify(features_train, labels_train)
### print accuracy 准确率
pred = clf.predict(features_test)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(pred, labels_test)
print accuracy ### 准确率:0.908
### draw the decision boundary with the text points overlaid
prettyPicture(clf, features_test, labels_test)
output_image("test.png", "png", open("test.png", "rb").read())
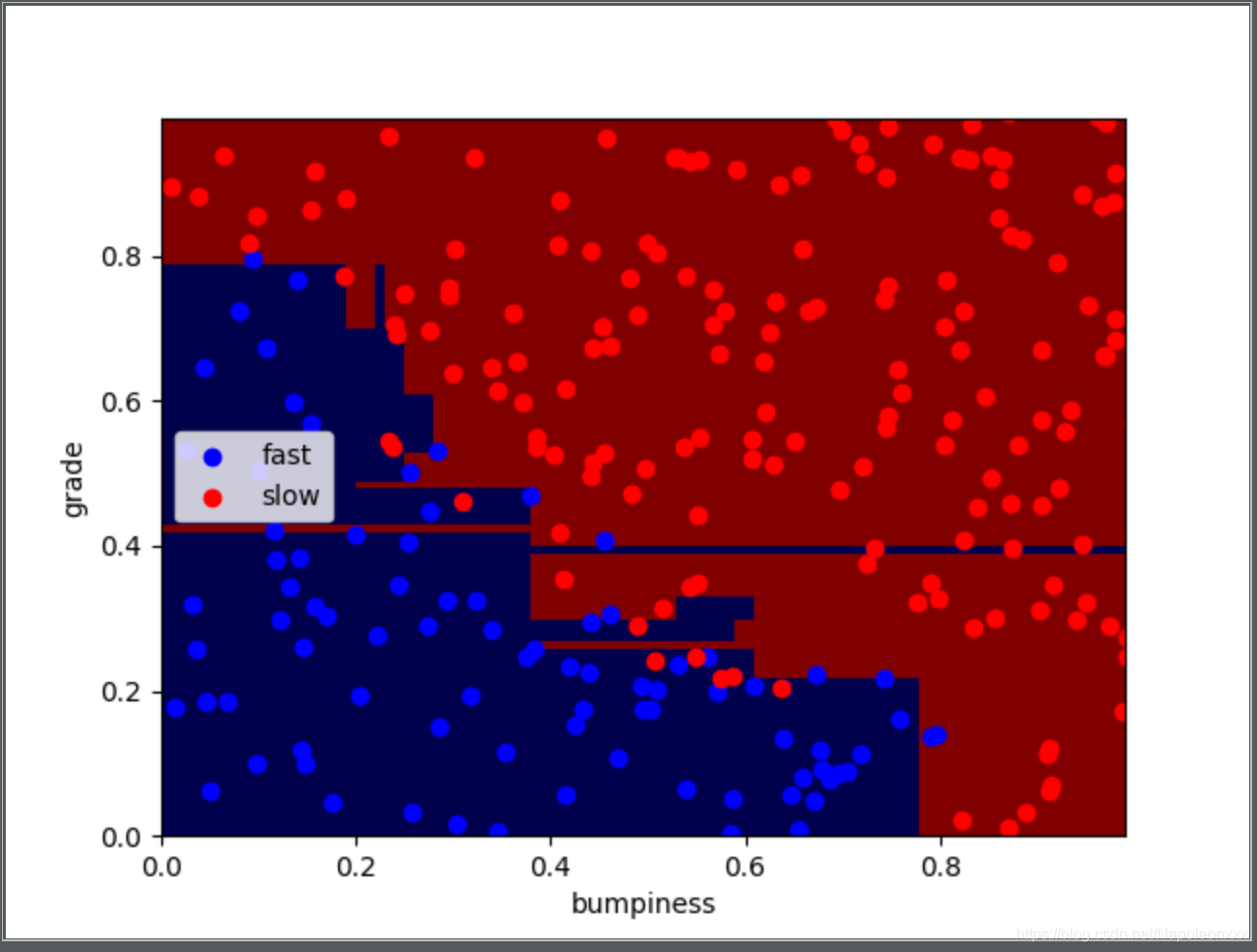
我们还是用朴素贝叶斯和线性SVM中使用的自动驾驶数据集。运行结果如下:
决策树参数
从结果图可以看出,这个决策树可能存在过拟合(overfitting)。我们可以通过调整某些参数,以提高准确率。
从文档中我们可以发现如下参数:
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’,
splitter=’best’, max_depth=None, min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None,
random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, class_weight=None, presort=False)
我们先试着调整min_samples_split这个参数。
min_samples_split决定了能够继续进行分隔的最少分割样本。即是否有足够的样本数来继续进行分割。默认值为2.
min_samples_split越小,决策树越深,决策边界越复杂。而决策树一旦开始变的非常深入和复杂,所得到的决策边界会试图把所有点都正确分类,最终可能导致过拟合。
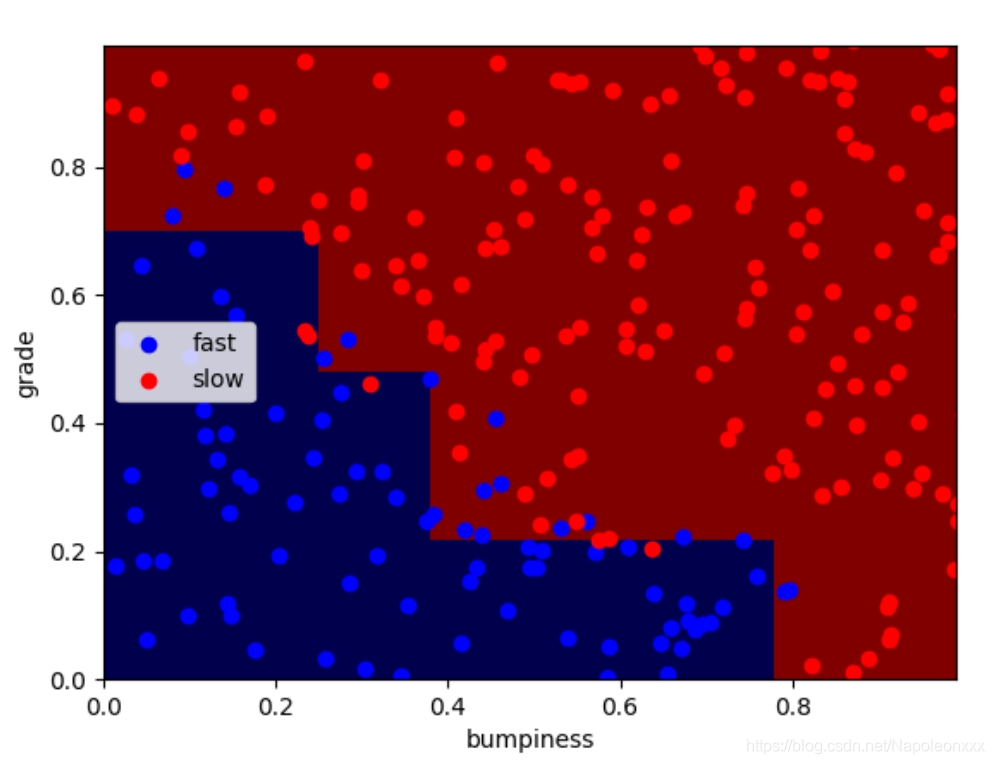
将min_samples_split设置为50,通过下图可以发现,决策边界更简单,准确率更高。
clf = DecisionTreeClassifier(random_state=0, min_samples_split=50)
### 准确率:0.912
熵(entropy)和信息增益(information gain)
数据杂质与熵(entropy)
熵主要控制决策树决定在何处分割数据。
熵的定义是:一系列样本中不纯度(impurity)的测量值。
还以自动驾驶训练集为例:问题是汽车可以快速行驶还是需要减速行驶。目前我们有两个训练变量,坡度(grade)和颠簸值(bumpiness)。假设有个新变量限速(speed limit)需要考虑。如果有限速,就不能开的太快。
我们将横轴颠簸度改为限速:超过某个限速值,无论坡度如何,都需要减速。
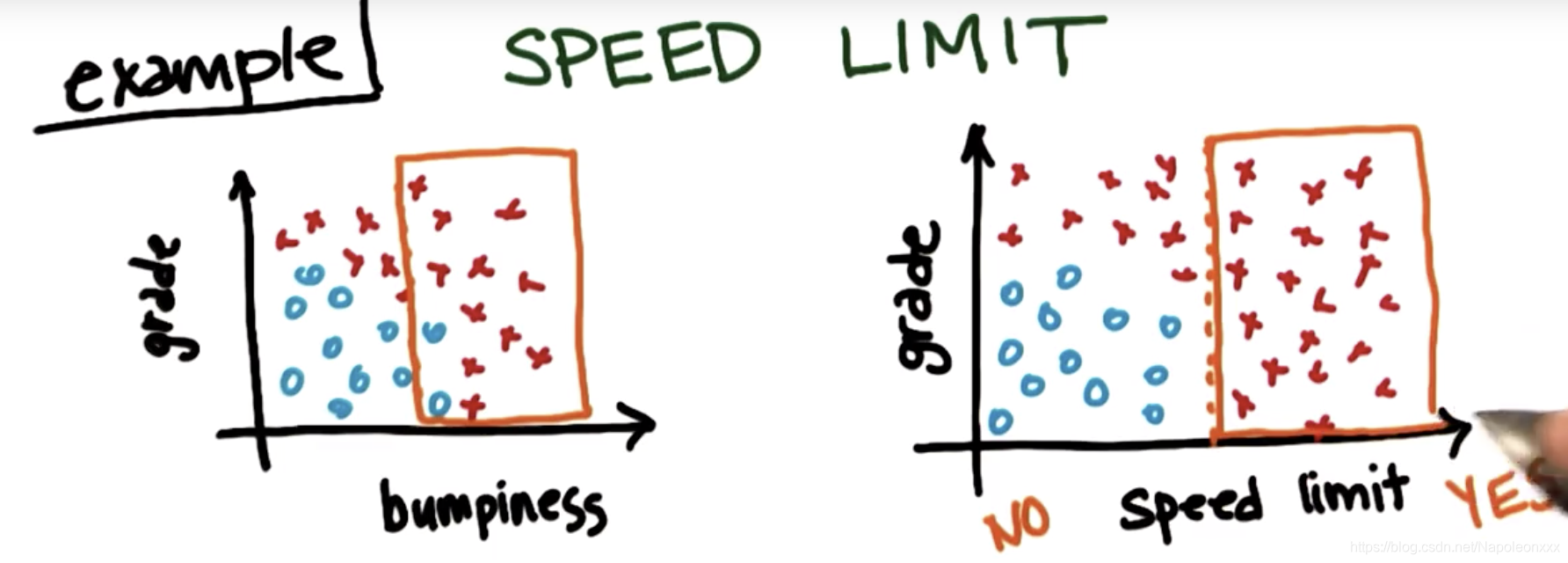
比较以上两种划分方式,可以发现,第二种划分方式的数据单一性更高(more purity)。
这就是熵和数据单一性的简单概念。建立决策树的过程其实就是找到变量划分点,从而产生尽可能单一的子集。实际上决策树做决策的过程就是对这个过程的递归重复。
熵公式
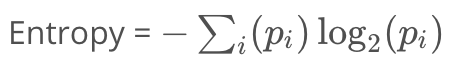
- Pi是第i类中的样本占总样本数的比例,再对所有类的结果求和
- 熵与数据单一性呈负相关
- 极端情况下,所有样本属于同一类,熵为0。在另一种极端情况下,样本均匀分布在所有类中,熵为最大值1.0。

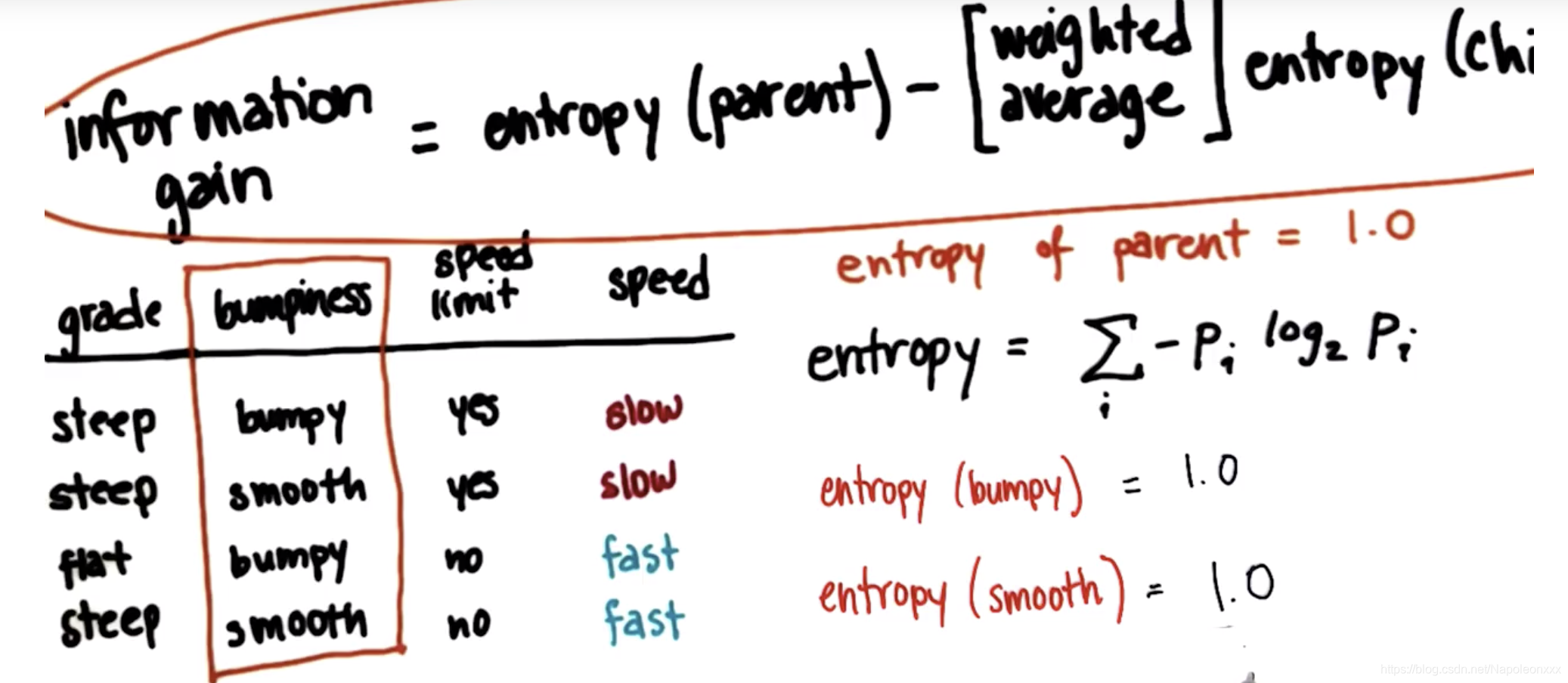
信息增益 information gain
信息增益定义为父节点的熵减去子节点的熵的加权平均。这些子节点是划分父节点后生成的。
决策树算法会最大化信息增益。

举个例子,我们来看下列算行驶数据:grade, bumpiness和speed limit为特征列,speed为label(Y值列)。
- 计算根据坡度grade划分数据能得到的信息增益
- grade作为parent的熵 entropy(grade) = 1. 因为grade对应的speed是均匀分布的(fast/slow=1)。
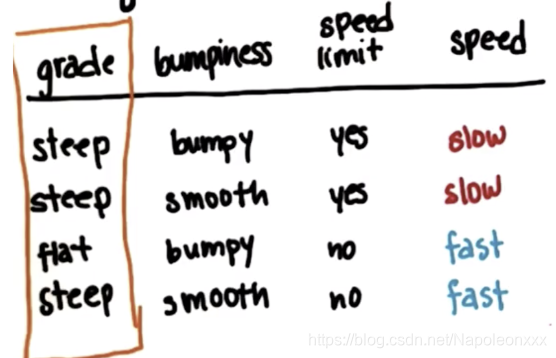
- 分支steep的熵
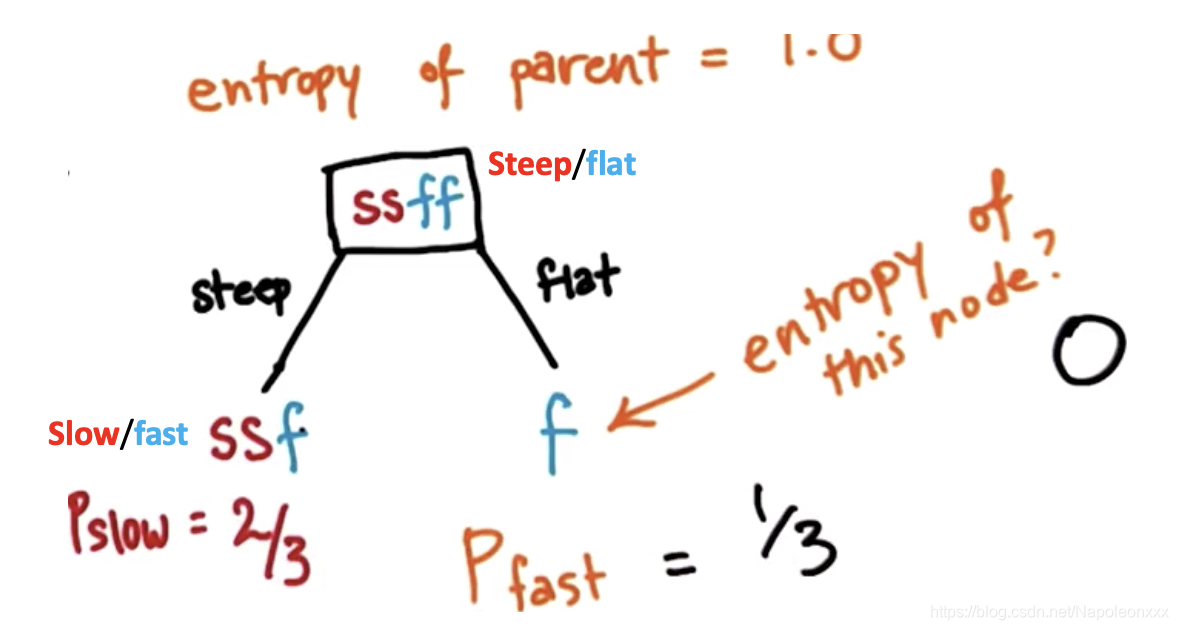

2)分支 flat的熵:grade值为’flat’时对应的speed只有一个样本,故熵为0
- grade作为parent的熵 entropy(grade) = 1. 因为grade对应的speed是均匀分布的(fast/slow=1)。
- 子节点的熵为两个分支熵的加权平均值
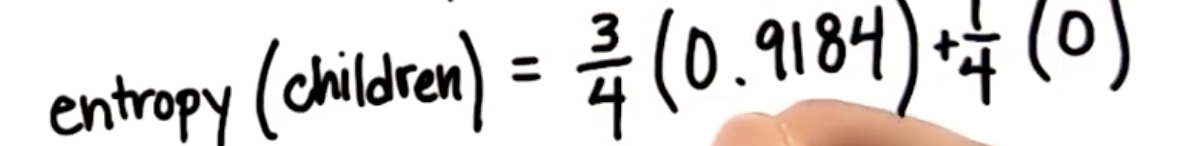
- 计算基于坡度进行数据划分时所得到的信息增益:

-
计算根据颠簸bumpiness程度划分数据能得到的信息增益
1)entropy(parent) = entropy(bumpiness) = 1
2)两个分支: entropy(bumpy) = 1.0
entropy(smooth) = 1.0
3)最后信息增益为0。这说明我们在划分这些训练样本后并没有学到任何东西,所以如果我们想要建立一个决策树,不会选择按照这个变量划分样本
-
计算根据速度限制(speed limit)进行拆分时的信息增益为1.
决策树在进行训练时就是在进行上述这种计算,它要考虑所有的训练样本以及所有的可用特征,然后使用信息增益准则来决定对哪个变量进行数据划分以及如何进行数据划分。
调整标准参数
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’,
splitter=’best’, max_depth=None, min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.0,
max_features=None, random_state=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
class_weight=None, presort=False)
criterion: 数据划分方式。默认值为gini,它是类似于数据单一性的指征。这个参数也支持etropy熵,亦即信息增益。gini和entropy有细微的差别,但在sklearn中都可以提供很好的结果。
偏差(bias)-方差(variance)困境
**高偏差(high bias)**机器学习算法会忽略训练数据,它几乎没有能力学习任何数据,这被称为偏差。
所以对一个有偏差的汽车进行训练,无论训练通过何种方式进行,它的操作都不会有任何区别。这在机器学习中不是好事。
**高方差(high variance)**机器学习算法是另外一个极端情况:汽车对数据高度敏感,它只能复现曾经见过的东西。对于之前未见过的情况,它的反应非常差。因为没有适当的偏差让它泛化新的东西。
所以我们真正想要的算法是两者的折中,即偏差-方差权衡。算法具有一定的泛化能力,但仍然对训练数据开放,能根据数据来调整模型
DT的优缺点
优点:
- 可解释性好
- 只需要很少的数据预处理工作。并且能够处理各种类型的特征
- 原生支持多分类
缺点:
- 决策树容易过拟合
- 决策树不稳定,也就是说可能数据集的一个很小的变动就会导致树发生很大的改变。
- 构建一个最佳的决策树是一个NP-hard问题,现有的启发式算法不能够保证最优(也没有一个理论的上下界)。
- 简单的决策树模型比较简单,很难表示数据集中的复杂关系