范涛
发表于2017-04-14
LDA 是一种topic model,相信对大多数工业界研发人员来说,LDA是一种让人望而却步的东西。LDA背后的数学理论是相对复杂的,但是LDA的最终计算公式却很简单,物理意义也很好理解。在互联网行业,主题模型经常用于query语义分析,广告query-bid触发匹配等各种文本挖掘场景。现在主流搜索公司,querylog日志数量是惊人的。海量文本中如何快速进行主题模型学习,至关重要,直接影响到主题模型是否可以在工业界中应用。这里重点介绍下目前业界用的比较多的几种快速采样算法,包括Sparse LDA,Alias LDA,Light LDA(做个知识的搬运工和解说家)。
介绍快速采样算法前,先简单回顾下标准的Gibbs 采样LDA相关介绍, 采样时间复杂度是O(K),K表示主题数(不同主题有不同命中概率,需要计算累计概率归一化项):

一 Sparse LDA
主要利用LDA的稀疏特性。现实中一般文档只会包含少数若干个主题,一个词也是参与到少数几个主题中。基于这种假设,把采样概率公式进行如下分解,分成3部分(r, s, t)。其中 “r”称为 “smothing only”桶 (与文档无关) ,“s”称为“doc-topic”桶(包含文档关联主题的非0项),“t”称为“topic-word”桶(包含主题-词的非0项)。
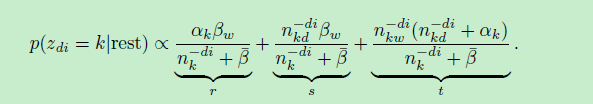
采样的时候就在r, s,t 各个桶中进行采样,采样机制如下:
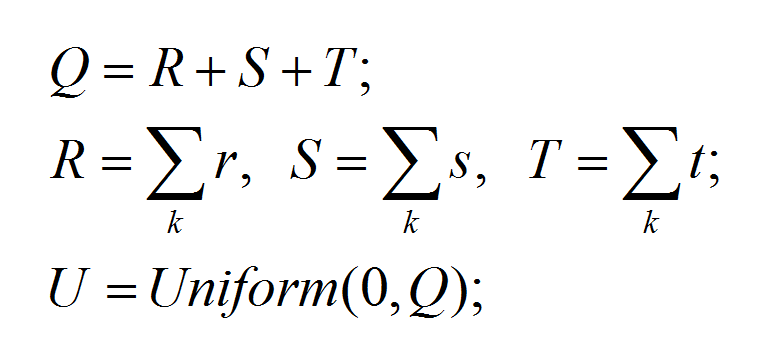
(1) 若U< T, 则在“topic-word”桶采样;(2) 若 T<=U < T+S, 则在“doc-topic”桶采样;
(3) 若U>=T+S, 则在“smothing only”桶采样;
Sparse LDA 的时间复杂度是O(Kd + Kw), 其中Kd是表示文档的主题数(稀疏),Kw表示词的主题数 (稀疏)。
二 Alias LDA
Sparse LDA利用稀疏性的特征,相对标准Gibbs LDA 提升了几十倍速度,那是否还能继续提升? 答案是肯定的。Alias LDA通过引入Alias Table 和Metropolis-Hastings 方法来进一步加快采样速度。
Alias LDA把采样概率公式进行如下分解(相对上面公式,改下公式变量名,主要是为了和论文一致):
标准Gibbs采样概率公式:
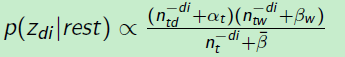
分解如下:
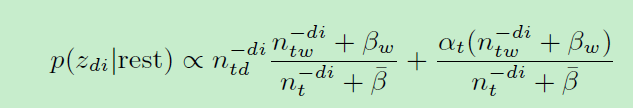
从这个公式来看,第二项可以看做“topic-word”桶,与文档无关。这一项可以通过Alias Table和 Metropolis-Hastings(一种蒙特卡洛采样方法) 进行O(1) 时间复杂度采样。
首先简单介绍下什么是Alias Table?
Alias Table是一种机制把离散非均匀分布转换成离散均匀分布 (均匀分布的采样时间复杂度O(1))。
下面Alias Table构造的一个示例: 4种颜色,分布概率不同, 最终转换成4个高度相同的四列,每列最多包含两种颜色。

GenerateAlias

Sample Alias

Metropolis-Hastings方法介绍:
为什么要用Metropolis-Hastings? 主要是原分布难采样,设计一个Proposal Distribution,近似原分布,但采样相对容易。但是这里有一个接受率问题,采样结果有可能不被接受需要重新采样。

其中p是原始分布,q是proposal distribution。
再回到Alias LDA这里。
如何把Alias Table机制应用到 LDA呢?
我们主题采样概率p是变化的,如果用p来建立Alias Table 是不合适的。
我们可以设计一个Proposal Distribution,近似原来主题概率分布,但采样相对容易。
(1)Alias Table:
设计qw(t) (主题采样概率分布的Proposal Distribution的一部分), 建立Alias Table,所以qw(t)分布采样时间复杂度是 O(1) .


(2)Metropolis Hastings proposal:定义pdw(t)分布:
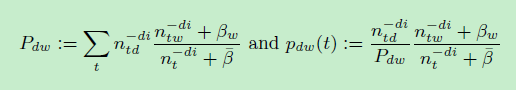
Pdw 可以看成稀疏的依赖文档的topic 分布(其实是Alias LDA主题采样概率分解公式第一项的归一化后形式),时间复杂度是O(Kd)。
那最终的完整的主题采样概率的Proposal Distribution如下:

Metropolis Hastings 过程中,从q(t) 采样的时间复杂度是O(Kd)(根据pdw和qw的概率来决定从哪一份采样)。
采样时候从之前主题s转移到主题t,会有个接受概率(参考Metropolis-Hastings方法介绍):


Alias LDA 时间复杂度是O(Kd),主要是从pw分布采样时间复杂度是O(Kd),而才qw分布采样时间复杂度是O(1)。
三 Light LDA
Alias LDA通过引入Alias Table 和Metropolis-Hastings,把时间复杂度控制在O(Kd)。他把主题采样概率分布分解成两部分,其中一项可以在O(1)时间复杂度采样完成,另外一部分不可以。那这里试想下是否有一种方法可以做到把主题采样概率分布分解成两部分,两部分都可以采用Alias table 和Metropolis Hastings 方法进行O(1)时间复杂度采样呢? Light LDA就是试图解决这个问题。主题采样分布可以分解成下面 形式:

设计如下的proposal 分布,里面包含了doc-proposal和word-proposal。

(1) word-proposal:
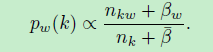
采样Metropolis-Hastings机制,从状态s向状态t转换,接受概率:



从pw(t) 中采样,根据Alias Table 的方法,时间复杂度O(1)。
(2)doc-proposal
采样Metropolis-Hastings机制,从状态s向状态t转换,接受概率:



这里指的提下,doc-proposal 可以不用建立alias table 也能做到O(1)时间复杂度进行采样。为什么?
看下图示例,zdi表(文档中每个词的主题表)就是个天然的alias表:
(3)组合 word-proposal 和doc-proposal
组成成一个“cycle proposal”:
如:先进行 word-proposal机制 采样,再进行doc-proposal 机制采样。
参考文献
【1】Yuan J, Gao F, Ho Q, et al. LightLDA: Big Topic Models on Modest Computer Clusters[J]. 2014:1351-1361.
【2】Li A Q, Ahmed A, Ravi S, et al. Reducing the sampling complexity of topic models[J]. 2014:891-900.
【3】https://github.com/Microsoft/LightLDA