1. 池化
池化层的输入一般来源于上一个卷积层,主要作用是提供了很强的鲁棒性(例如max-pooling是取一小块区域中的最大值,此时若此区域中的其他值略有变化,或者图像稍有平移,pooling后的结果仍不变),并且减少了参数的数量,防止过拟合现象的发生。池化层一般没有参数,所以反向传播的时候,只需对输入参数求导,不需要进行权值更新
池化层的前向计算
前向计算过程中,我们对卷积层输出map的每个不重叠(有时也可以使用重叠的区域进行池化)的n*n区域(我这里为2*2,其他大小的pooling过程类似)进行降采样,选取每个区域中的最大值(max-pooling)或是平均值(mean-pooling),也有最小值的降采样,计算过程和最大值的计算类似。
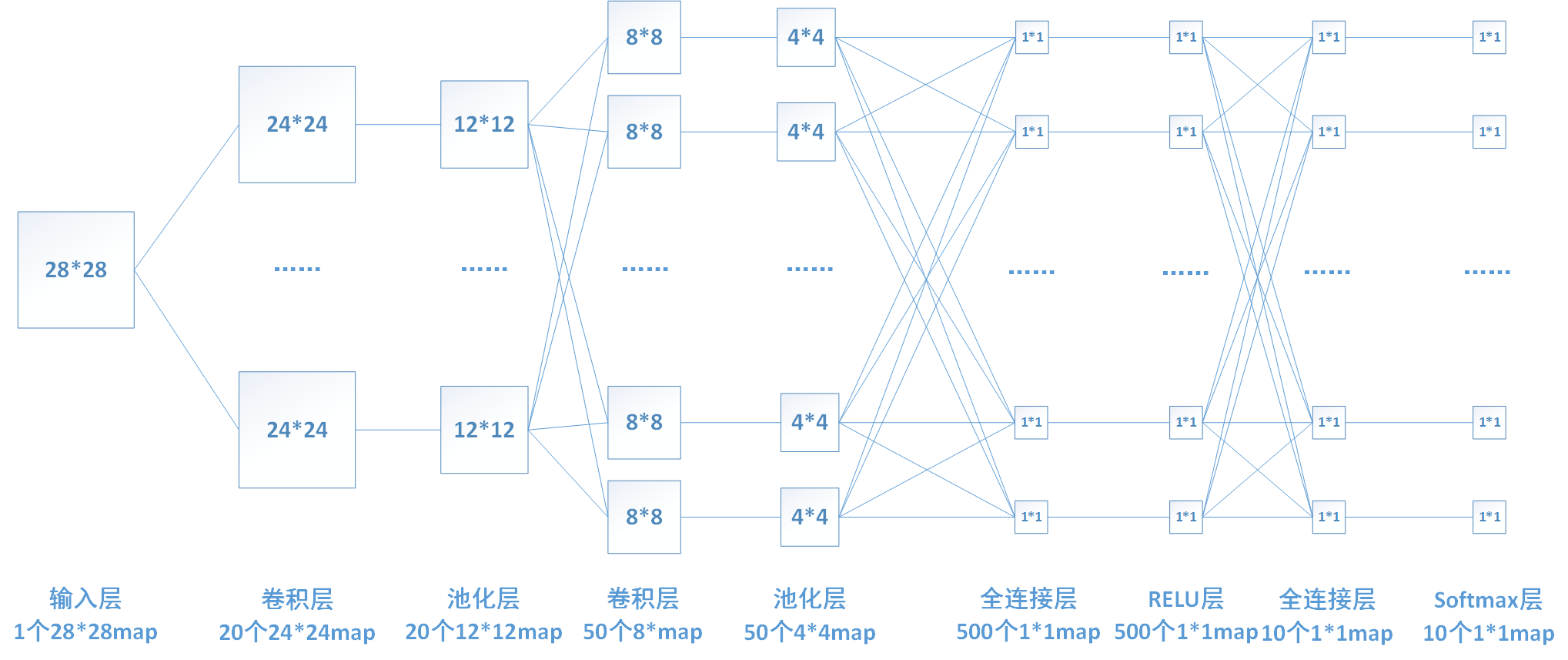
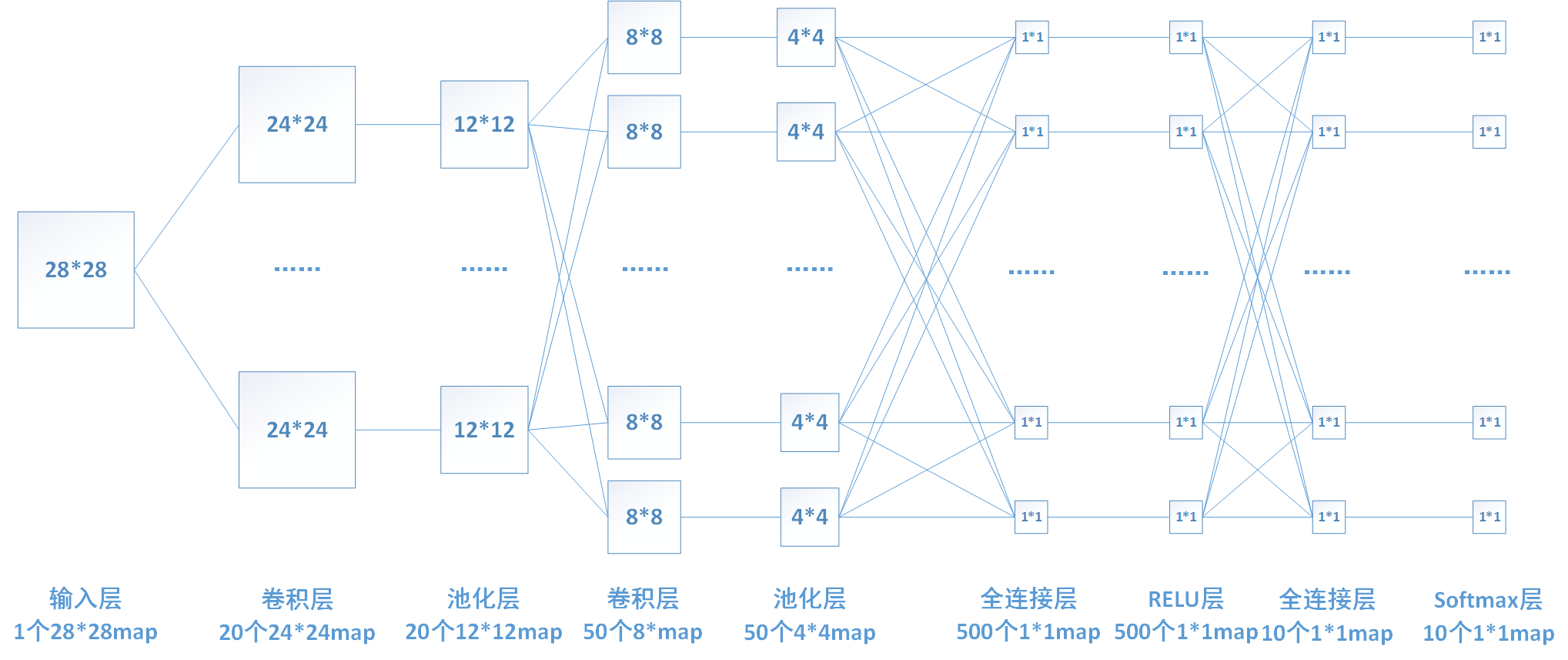
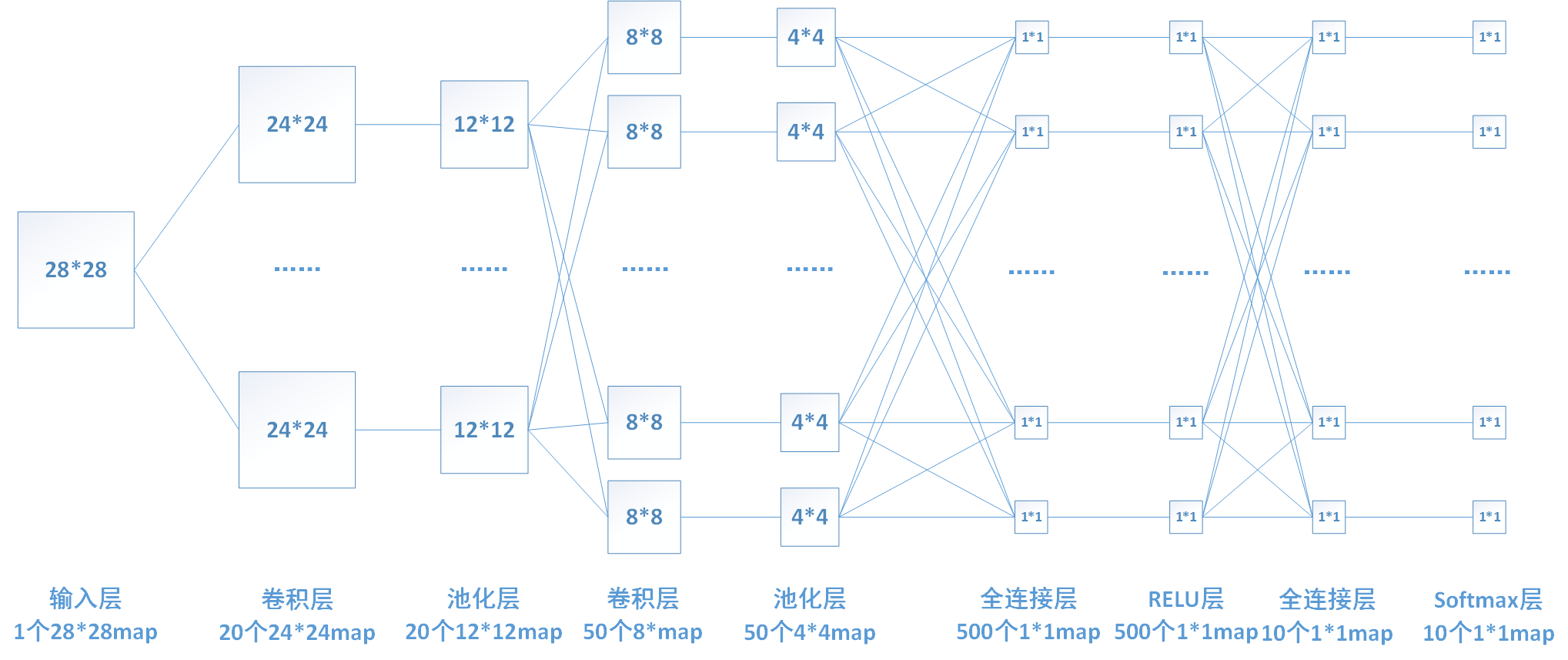
上图中,池化层1的输入为卷积层1的输出,大小为24*24,对每个不重叠的2*2的区域进行降采样。对于max-pooling,选出每个区域中的最大值作为输出。而对于mean-pooling,需计算每个区域的平均值作为输出。最终,该层输出一个(24/2)*(24/2)的map。池化层2的计算过程也类似。
下面用图示来看一下2种不同的pooling过程。
max-pooling:

mean-pooling:

池化层的反向计算
在池化层进行反向传播时,max-pooling和mean-pooling的方式也采用不同的方式。
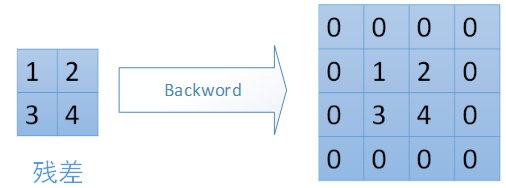
对于max-pooling,在前向计算时,是选取的每个2*2区域中的最大值,这里需要记录下最大值在每个小区域中的位置。在反向传播时,只有那个最大值对下一层有贡献,所以将残差传递到该最大值的位置,区域内其他2*2-1=3个位置置零。具体过程如下图,其中4*4矩阵中非零的位置即为前边计算出来的每个小区域的最大值的位置。
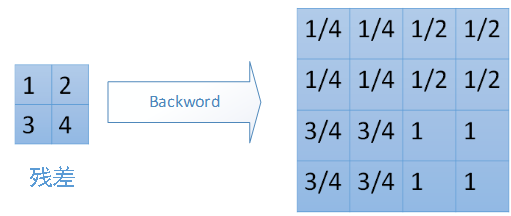
对于mean-pooling,我们需要把残差平均分成2*2=4份,传递到前边小区域的4个单元即可。具体过程如图:

全连接层的每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来。由于其全相连的特性,一般全连接层的参数也是最多的。
全连接层的前向计算
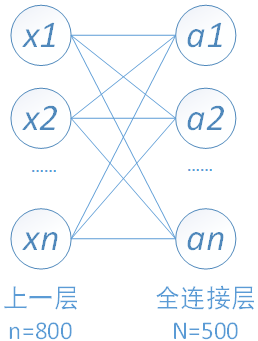
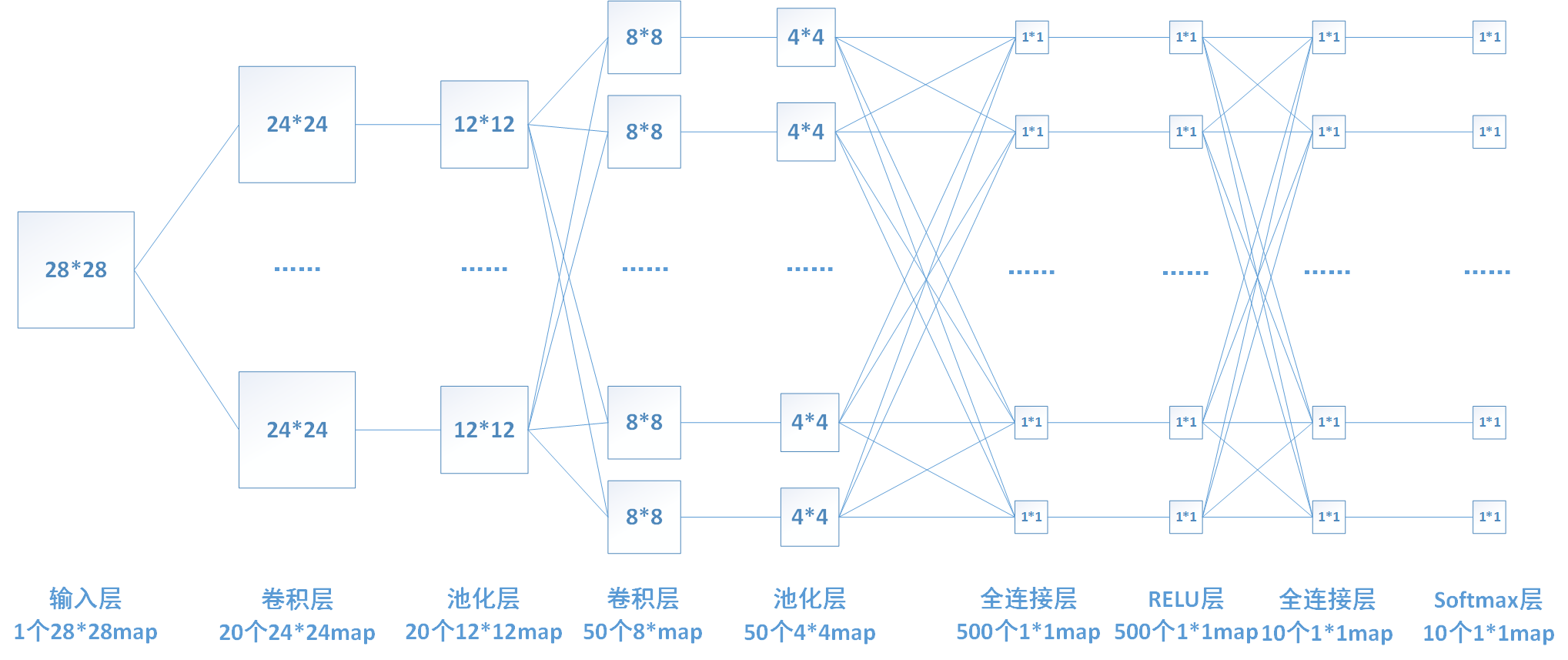
下图中连线最密集的2个地方就是全连接层,这很明显的可以看出全连接层的参数的确很多。在前向计算过程,也就是一个线性的加权求和的过程,全连接层的每一个输出都可以看成前一层的每一个结点乘以一个权重系数W,最后加上一个偏置值b得到,即 。如下图中第一个全连接层,输入有50*4*4个神经元结点,输出有500个结点,则一共需要50*4*4*500=400000个权值参数W和500个偏置参数b。
下面用一个简单的网络具体介绍一下推导过程
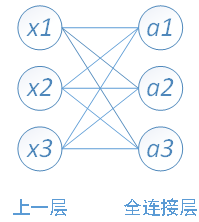
其中,x1、x2、x3为全连接层的输入,a1、a2、a3为输出,根据我前边在笔记1中的推导,有
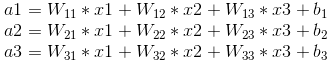
可以写成如下矩阵形式:
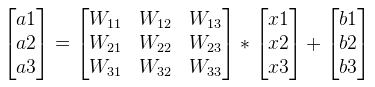
全连接层的反向传播
以我们的第一个全连接层为例,该层有50*4*4=800个输入结点和500个输出结点。
由于需要对W和b进行更新,还要向前传递梯度,所以我们需要计算如下三个偏导数。
1、对上一层的输出(即当前层的输入)求导
若我们已知转递到该层的梯度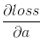 ,则我们可以通过链式法则求得loss对x的偏导数。
,则我们可以通过链式法则求得loss对x的偏导数。
首先需要求得该层的输出a i对输入x j的偏导数

再通过链式法则求得loss对x的偏导数:
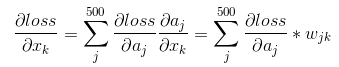
上边求导的结果也印证了我前边那句话:在反向传播过程中,若第x层的a节点通过权值W对x+1层的b节点有贡献,则在反向传播过程中,梯度通过权值W从b节点传播回a节点。
若我们的一次训练16张图片,即batch_size=16,则我们可以把计算转化为如下矩阵形式。

2、对权重系数W求导
我们前向计算的公式如下图,
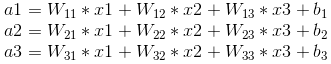
由图可知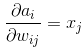
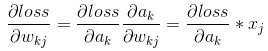
当batch_size=16时,写成矩阵形式:

3、对偏置系数b求导
由上面前向推导公式可知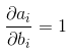 ,
,
即loss对偏置系数的偏导数等于对上一层输出的偏导数。
当batch_size=16时,将不同batch对应的相同b的偏导相加即可,写成矩阵形式即为乘以一个全1的矩阵:

激活函数是用来引入非线性因素的。网络中仅有线性模型的话,表达能力不够。比如一个多层的线性网络,其表达能力和单层的线性网络是相同的(可以化简一个3层的线性网络试试)。我们前边提到的卷积层、池化层和全连接层都是线性的,所以,我们要在网络中加入非线性的激活函数层。一般一个网络中只设置一个激活层。
激活函数一般具有以下性质:
非线性: 线性模型的不足我们前边已经提到。
处处可导:反向传播时需要计算激活函数的偏导数,所以要求激活函数除个别点外,处处可导。
单调性:当激活函数是单调的时候,单层网络能够保证是凸函数。
输出值的范围: 当激活函数输出值是有限的时候,基于梯度的优化方法会更加稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是无限的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的learning rate.
常见激活函数介绍:
实际中可选用的激活函数有很多,如下图:
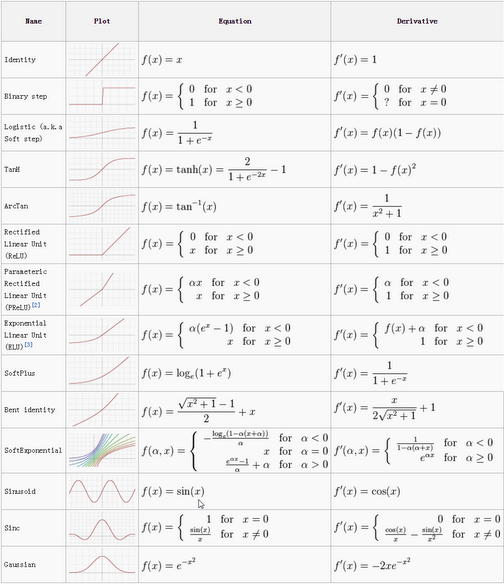
但不同的激活函数效果有好有坏,现在一般比较常见的激活函数有sigmoid、tanh和Relu,其中Relu由于效果最好,现在使用的比较广泛。3种激活函数具体介绍如下:
Sigmoid函数
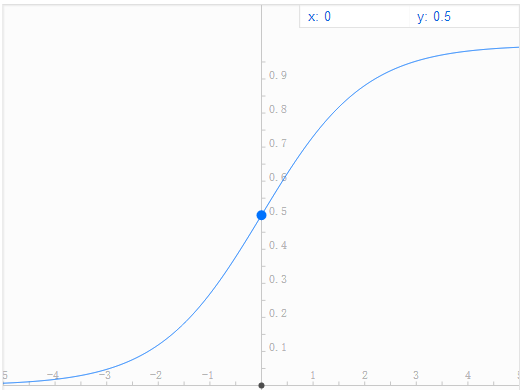
Sigmoid函数表达式为: ,它将输入值映射到[0,1]区间内,其函数图像如下图(谷歌和百度搜索框输入表达式就能给出图像,挺好用的)。
,它将输入值映射到[0,1]区间内,其函数图像如下图(谷歌和百度搜索框输入表达式就能给出图像,挺好用的)。
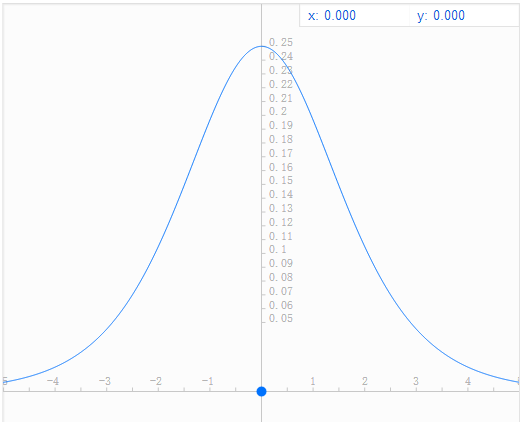
Sigmoid有一个十分致命的缺点就是它的导数值很小(sigmoid函数导数图像如下图),其导数最大值也只有1/4,而且特别是在输入很大或者很小的时候,其导数趋近于0。这直接导致的结果就是在反向传播中,梯度会衰减的十分迅速(后面公式的推导过程会证明这一点),导致传递到前边层的梯度很小甚至消失,训练会变得十分困难。
还有就是sigmoid函数的计算相对来说较为复杂(相对后面的relu函数),耗时较长,所以由于这些缺点,现在已经很少有人使用sigmoid函数。
Tanh函数
Tanh函数表达式为: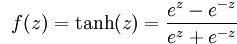 ,其图像为(函数复杂点百度就画不了了
,其图像为(函数复杂点百度就画不了了
 ):
):
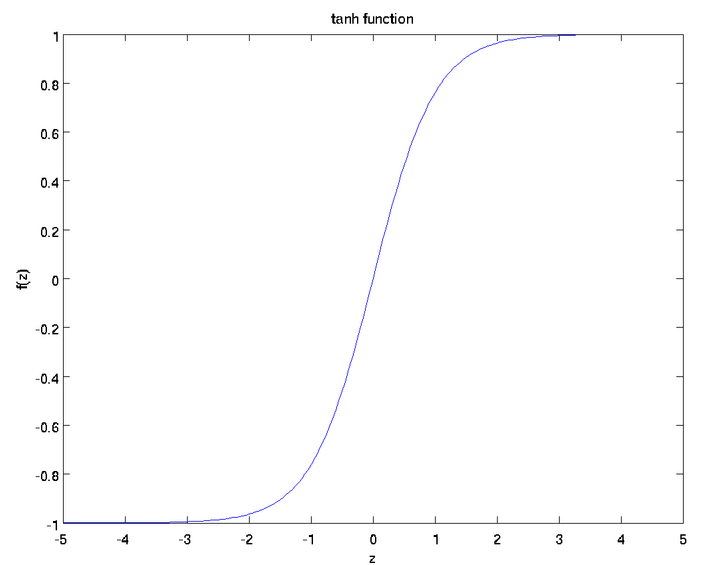
Tanh函数现在也很少使用。
Relu函数
Relu函数为现在使用比较广泛的激活函数,其表达式为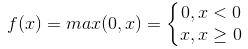 。当输入x<0时,输出为0;当x>0时,输出等于输入值。
。当输入x<0时,输出为0;当x>0时,输出等于输入值。
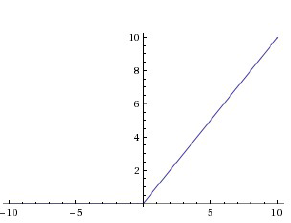
Relu函数相对于前边2种激活函数,有以下优点:
1、relu函数的计算十分简单,前向计算时只需输入值和一个阈值(这里为0)比较,即可得到输出值。在反向传播时,relu函数的导数为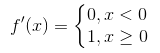 。计算也比前边2个函数的导数简单很多。
。计算也比前边2个函数的导数简单很多。
2、由于relu函数的导数为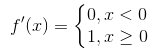
Relu函数也有很明显的缺点,就是在训练的时候,网络很脆弱,很容易出现很多神经元值为0,从而再也训练不动。一般我们将学习率设置为较小值来避免这种情况的发生。
为了解决上面的问题,后来又提出很多修正过的模型,比如Leaky-ReLU、Parametric ReLU和Randomized ReLU等,其思想一般都是将x<0的区间不置0值,而是设置为1个参数与输入值相乘的形式,如αx,并在训练过程对α进行修正。
激活函数层的推导
激活函数层的前向计算
这里我以relu层为例介绍一下激活函数层的推导,由于relu层没有参数,所以不需要进行权值的更新,只需进行梯度的传递。下图还是我们熟悉的那个网络,其中倒数第三层为激活函数relu层。
relu函数的表达式为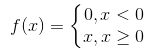
激活函数层的反向传播
Relu函数的导数为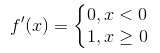 。假设该层前向计算过程为
。假设该层前向计算过程为
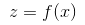 ,其中f(x)为relu函数。反向传播时已知
,其中f(x)为relu函数。反向传播时已知
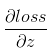 ,根据链式求导法则
,根据链式求导法则
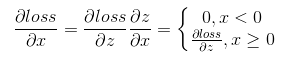 。
。
所以反向传播时,只需将前向计算时输入大于0的结点对应的梯度向前传,小于0的结点的梯度置零即可。
softmax简介
Softmax回归模型是logistic回归模型在多分类问题上的推广,在多分类问题中,待分类的类别数量大于2,且类别之间互斥。比如我们的网络要完成的功能是识别0-9这10个手写数字,若最后一层的输出为[0,1,0, 0, 0, 0, 0, 0, 0, 0],则表明我们网络的识别结果为数字1。
Softmax的公式为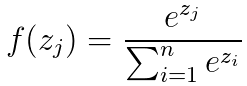
softmax层的推导
softmax层的前向计算
在我们的网络中,最后一层是softmax层。
softmax公式为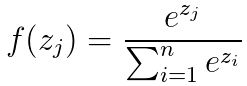
Softmax还有另一种计算方法。假设zk为输入中的最大值,则softmax也可以写成这种形式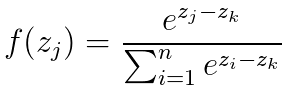
softmax层的反向传播
深度学习中的分类网络,一般都是使用softmax和交叉熵作为损失函数。关于softmax和cross entropy的介绍和解释可以详见我的另一篇博客softmax loss。这篇博客仅解释如何对softmax loss层进行求导反向传播。 假设网络最后一层的输出为z,经过softmax后输出为p,真实标签为y(one hot编码),则损失函数为:

或可描述为:
