前言:
在深度学习方面学习和实践了很长时间了,正好今天比较空闲,觉得还是有必要将其发展历程梳理一下,做一个简单的笔记,就当是看了一场深度学习的纪录片吧哈哈哈,所以没有过多的关于数学方面精确推导等过程,就是根据作者论文做了一个脉络上的简单的感性的梳理,不得不说深度学习的发展是曲折的,其多次跌入低谷,能有今天的再次璀璨,离不开一些大牛的坚持不懈,说的这里就不得不提一下Geoff Hinton,可以看一下Hinton教授个人的传奇人生,从中就会发现神经网络一路走来的不平凡,而Hinton教授多年来的坚持真心值得敬佩,在一次次质疑声中,他靠着一个信念,说的更准确点我觉得是自信,那就是Hinton教授本人那一句:everyone else is wrong!!!!!!!!!!!!!!!!!
时至今日,深度学习已经有很多派系:CNN,RNN,对抗神经网络,以及强化学习这一大分支等等,但是从发展进程来看,RNN和CNN是较早出现的,目前使用也较为广泛,尤其是CNN这一派系中经典模型较多,每一个经典模型都为下一个更经典模型的提出提供了宝贵的经验,所以本文重点梳理了RNN和CNN(对强化学习感兴趣的同学可以看一下笔者早期的几篇博客q-learning等等,都比较简单,入门尚可),通过看其两者的发展我们就能大概看到深度学习发展的一个缩影,共同回味,面向未来!文章最后是一点个人小笔记(方面后续查看),有tensorflow方面的等等,可以不必看
注意:(1)本文部分图片来源于:TensorFlow实战_黄文坚一书
(2)本文一级标题的字体是深紫色斜体,二级标题字体是深红色,三级标题是浅红色,四级标题字体是浅紫色,绿色是注意点
主要的数据集、顶级会议、数据库:
ILSVRC计算机视觉比赛:其数据集来至于ImageNet:有着1500万张照片,2200分类,其中ILSVRC用了120万,1000种分类, 采用top5-top1的评价模式,ILSVRC第一次出现是在2012年,后面几乎每年的冠军就对应着一个新的模型,其中2012-2015是模型的高速发展期,也是现在我们所熟知那些经典模型的夺冠年,现如今深度学习已经发展的越来越好,解决ILSVRC已经不是什么难题,再在上面比下去已经没有什么意义了,所以2017年也是其举办的最后一年比赛,后面会由WebVision竞赛(Challenge on Visual Understanding by Learning from Web Data)继续,ILSVRC虽然落幕,但是它给深度学习发展尤其是计算机视觉方面带来的影响却是深远的,在该领域名留青史无可厚非。
NIPS,全称神经信息处理系统大会(Conference and Workshop on Neural Information Processing Systems),是一个关于机器学习和计算神经科学的国际会议。该会议固定在每年的12月举行,由NIPS基金会主办。NIPS是机器学习领域的顶级会议 。在中国计算机学会的国际学术会议排名中,NIPS为人工智能领域的A类会议 。
arXiv.org:最初创立于1991年,那个时候甚至连万维网(WWW)都还不存在,但Paul Ginsparg的创造被证明很受他的同行们欢迎,高能物理学家们很快就接受了这种新的交流方式,并积极地参与进来。并很快曼延到天体物理、凝聚态物理等其他领域。目前包含了超过50万篇文章,传统的机器学习和深度学习很多论文上面基本都有,是一个很好的好资源网站,本篇所提到的论文在上面都可以找到,要知道学习一个模型最权威的资料就是作者的原始论文,所以说请记住这个网站:https://arxiv.org/
大牛:
Hinton教授、Yann LeCun
上面两位是公认的大牛,他们的事迹这里就不多说了,大家自行查阅即可,绝对是值得膜拜的
Andrew、Andrej Karpathy、Ian Goodfellow、Yoshua Bengio、Ruslan Salakhutdinov、Pieter Abbel
这些也都是大牛,所在机构或创立的机构都是大家耳熟能详的,尤其是第一位相信大家很熟悉了
Schmidhuber教授
最后单独说一位教授,即Schmidhuber教授,为什么单独说呢?因为教授本身有很大的成果,但是其名声却不是很大,不被AI界待见,虽不出名,但是其成果如雷贯耳,LSTM!!!!,对没有看错,LSTM就是Schmidhuber教授本人提出的,甚至后面即将说的ResNet网络的灵感也是来源于Schmidhuber教授的Highway Network,DeepMind的联合创始人Shane Legg也曾是Schmidhuber教授的博士生,可见其实力,有人说其可以和Hinton教授、Yann LeCun并肩,称为AI“教父”,但是结果却不尽人意,原因就是:“爱怼!”,尤其是在NIPS大会上“怼”,关于是不是真的无所根据的瞎怼,不做评价,就像Yann LeCun所说:“来回地反驳是毫无意义的,人们有自己的看法”。
所以不论怎么,我们不应该将重点放在这上面,单从科学技术方面看Schmidhuber教授是毫无疑问值得尊敬的,他的研究成果对推动深度学习发展发挥了不可磨灭的作用!!!!!这是应该被记住的。
CNN有关模型发展历史:
概述:
各个模型在ILSVRC比赛中的结果
注意:除了LeNet(那时候还没有ILSVRC),后面的模型都是在ILSVRC比赛中亮相进入公众视野!!!!!!!!1

下面会按照历史发展顺序依次介绍各个模型以及他们之前到底有哪些联系,以紫色分割线隔开
----------------------------------------------------------------------------------------------------------------------
LeNet:
(1998)其是Facebook的AI实验室负责人Yann LeCun利用深度神经网络建立的,标志着神经网络的诞生。
5层网络=2个卷积层+3个全连接层
一个卷积层(5*5*6)[一般还有经过一个激活函数Relu]、池化层(2*2减半),一个卷积层(5*5*16)[一般还有经过一个激活函数Relu]、池化层(2*2减半)、两个全连接层[一般后面还有加一个Dropout防止过拟合,记住全连接层后面一般加Dropout]、一个高斯连接层

但这并没有使得CNN火起来,因为后面出现的SVM算法效果很好,而且当时的算力也跟不上,但是CNN只是昙花一现,但LeNet有一个最大贡献那就是:确定了CNN的基本组成单元即卷积层+池化层。要知道这是开创性的,来之不易!!!!!!!!!
-------------------------------------------------------------------------------------------------------------------------
AlexNet:
(2012)Geoff Hinton:AI之父,40多年的深度学习,英国人,奠定了他在今天人工智能圈“教父”地位的,是他在多层神经网络技术的贡献在1986年提出的通过反向传播来训练深度网络理论,标志着深度学习发展的一大转机,为近年来人工智能的发展奠定了基础,因不愿与国防部挂钩,去到了加拿大的多伦多大学,2012年带着团队用AlexNet参加了ILSVRC比赛夺冠。最近2017年又提出胶囊神经网络
8层网络=5个卷积层+3个全连接层
AlexNet:五个卷积层(前两个后面都加了池化层,后面三个一起结束后,加了一个池化层),三个全连接层

可以说AlexNet的出现给CNN带来了春天,随后CNN就井喷式的发展起来了,该模型的突出贡献:
1 使用Relu激活函数代替了sigmoid,之前也有使用Relu激活函数的,但是到这里才正式确定了其地位
2 使用了Dropout技术,防止过拟合
3 相比于以前的平均池化层,这里采用了最大池化层
须知:这里的3点在以后的模型中基本成了标配!!!!!!!!!!!
-----------------------------------------------------------------------------------------------------------------------
ZF-Net:
该模型是2013的冠军,但本质是在AlexNet上的小打小闹,调调参数,没什么可说的,名气也远没有其他年份冠军那么大
---------------------------------------------------------------------------------------------------------------------
VGGNet
(2014)牛津大学计算机视觉组和google的DeepMind公司共同研发一种深度卷积网络,2014年的亚军。
19层网络=16层卷积层+3层网络层

其一共有5种等级,性能表现:

从这里可以看出,网络进一步走向了深处,且除了C等级中有少许的1*1卷积层外,其它的卷积层都是3*3,作者实践后自己总结如下:

需注意:
(1)虽然从A-E网络逐步变深,但是参数量并没有增长很多,原因参数量主要是消耗在最后3个全连接层,而前面的卷积层虽然层数多,但消耗的参数量不大。不过,卷积层的训练比较耗时,因为其计算量大。
(2) D和E是常说的VGGNet-16和VGGNet-19。C中1*1卷积的意义在于线性变换,而输入的通道数和输出的通道数不变,没有发生降维。
(3)训练的时候可以逐级进行,先训练A,然后用训练的参数结果作为后面训练模型参数的初始化。
VGGNet带来的贡献就是:
探索了网络深度和性能的关系即越深的网络效果越好
同时给与设计神经网络如下两点启发:
(1)多使用3*3的这种小卷积层堆叠可以带来的好处就是:
参量变少,2个3*3卷积层堆叠相当于1个5*5卷积层(如下图),3个3*3卷积层堆叠相当于一个7*7卷积层,那么参量减少了
3*3*3/7*7=55%,泛化能力变强,因为使用3次3*3相当于使用了3次Relu进行非线性转化,而后者7*7只进行了一次

(2) 1*1卷积使用之一,在不影响纬度的情况下,使用1*1(线性变化),但其后面紧接着一个Relu,相当于又多一次使用了Relu,提高泛化能力
---------------------------------------------------------------------------------------------------------------------------
InceptioNet
2014年的冠军
按发展期一共出现四种模型:Inception V1、Inception V2、Inception V3、Inception V4
(2014.9,top-5错误率:6.67%)Inception V1原论文:https://arxiv.org/pdf/1409.4842.pdf
(2015.2,top-5错误率:4.8%)Inception V2原论文:https://arxiv.org/pdf/1502.03167.pdf
(2015.12,top-5错误率:3.5%)Inception V3原论文:https://arxiv.org/pdf/1512.00567.pdf
(2016.2,top-5错误率:3.08%)Inception V4、Inception-ResNet原论文:https://arxiv.org/pdf/1602.07261.pdf
Inception系列模型不但在深度上面继续走向了深处,而且在宽度上也进行了探索,深度上以前的经典Net都已经很好的进行实践,越深带来的性能越好,当然了,参数量也越多,需要的算力也越多,那么宽度上面怎么理解呢?其设计思想可以这样来看:其实在设计网络的时候难点就是在于卷积核尺寸选用方面,到底是选用多大,或者更极端一点就是说该层到底需不需要卷积层,同理池化层面临着同样的问题,既然不知道,那么我们就将这几种情况都排在该层(即同一深度下增加了宽度),让模型通过训练自己选择出较好的一种,相比于以前,在同一宽度下,比较直观的理解就是又多了几种选择
注意:因为V4是Inception最新的一种网络,也可以看成是经过了几代优化后目前最好的一种,所以本位会结合其论文重点解读一下。
Inception V1(22层网络:9个Inception Model)
论文的Inception Model:

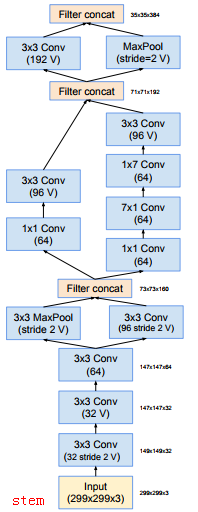
图(a)是最原始的Model,所有的卷积核都在上一层的所有输出上来做,但由于Previous layer(前一层)特征图厚度很大,那么和卷积层(比如图中的5*5)卷积所需要的算力就会很大,为了避免这一现象于是提出了图(b),在3x3前,5x5前,max pooling后分别加上了1x1的卷积核起到了降低特征图厚度的作用,也就是Inception v1的网络结构。
注意:这里就体现了1*1卷积核的另一个作用(在VGGNet中讲过其另一个作用):降维,怎么理解呢?比如前一层是28*28*192,可以看到192是很深的特征图,那么使用比如1*1*32的卷积核后,就变为28*28*32,从192到32是不是就相当于降维了,其实完整来说应该是这样(比如batch_size是128):Previous layer是[128,28,28,192],1*1 convolutions是[1,1,192,32]
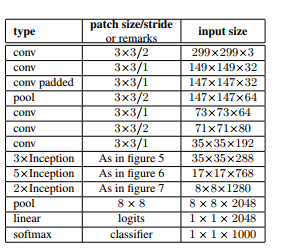
完整的网路图:(图片来源原论文)

详细参数

上图中红色的框就是Inception Model,一共是9个,同时需注意还有一些绿色框(辅助分类节点),一共有两个,从图中也可以看出其也是分类,做法是将其按一个较小的权重(0.3)加到最终的分类结果中,这样做的好处(TensorFlow实战_黄文坚一书)就是相当于模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个Inception Model 训练都有裨益。同时以往模型最后三个是全连接层,这里换成了平均池化层,我们知道,参数量主要是消耗在全连接层的,而这里用了一个池化层代替,大大减少了参数量,对于整个GoogLeNet模型,虽然总共有22层,但是参数数量却只是8层的AlexNet的十二分之一。
Inception V1的突出贡献或带来的启示在于:
(1)宽度上面首次探索即Inception Model 的使用
(2)1*1卷积层在降维上面的使用
(3)平均池化层取代全连接层进而大幅度减少了参数量
(4)辅助分类节点的使用
Inception V2(32层网络:10个Inception Model)
可以看到V2的模型相比于V1更深,
其主要的改变:
(1)在网络的前半部分用2个3*3卷积层代替了Inception Model中的5*5卷积层,原因是降低了参数量(具体原因VGGNet启示部分已经讲过)并进一步防止了过拟合

(2)使用了Batch Normalization:提高了训练速度,同时提高了准确率
主要参数模型如下:

Inception V3
在V2的基础上再次走向深处
其主要:
(1)在网络的前半部分用2个3*3卷积层代替了Inception Model中的5*5卷积层(如图一),这一点沿用了V2的技术,但不同的是在网络的后部,又出现了图二、图三的改造:有可能有人要问为什么后面要使用图二图三,不继续使用图一的那种改造结构呢?没为什么,说的直白点就是如果有想法,觉得这样做可能会好点,就去试一试,相信原作者也是两种情况都试了进行了比较,最后选取好的一种方案,当然了也有相应的解释,但都是先成功后解释,最后也是最直接的办法还是那句话:实践!实践说明一切。



(3)像V1一样有辅助分类,而且在辅助分类中还有辅助分类即分支中还有分支,网络中的网络中的网络,哈哈哈
整体网络图:

更加详细的整体图:https://www.jianshu.com/p/3bbf0675cfce
主要参数:
上面所说的figure5,6,7分别对应上面给出的图一,二,三
综上来看,V2带来的新启示就是:
(1)拆分大卷积核为更多更小的卷积核不但可以降低参数量,还增加了非线性,在拆分时甚至可以拆分为几个1维卷积
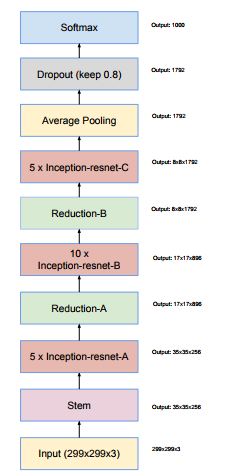
Inception V4,Inception-ResNet
V4结构的话,论文是分为两部分介绍的,一个是纯粹只有Inception模块即V4,另一个是融合了ResNet的Inception-ResNet(关于ResNet可以先看下面ResNet,再返回头来看该部分)
需注意:该篇论文是16年发表的,而ResNet是15年的,由于ResNet想法新颖,效果较好,于是google团队们也想跃跃欲试,于是便开始了将ResNet融入了自己开发的Inception的研发,当然了,正如论文所说的除了简单粗暴的直接融合外,还进一步探究了融合ResNet给Inception所带来的好处以及有没有必要性等问题,文中通过实践证据(注意:就是直接看模型在数据集上的结果)给出了如下结论:
在ResNet论文中通过理论和实践两方面论证了残差结构在深度卷积网络中(尤其是想往继续往深走)使用是非常必要的,但是通过实践google并不认同这一观点,最少在图片分类这方面并不认同,同时他们发现在Inception应用ResNet的一个好处就是加速了模型的训练。关于这部分内容,大家有兴趣可以看原论文的2部分
下面就来先看一下Invection V4:
作者认为:过去做法非常保守,限制改变独立网络的组分,保持其余网络的稳定性,之前没有对网络进行简化,导致网络看起来更加复杂,在最新的Inception-v4中,要去掉不必要的模块,同时统一各个grid size一样的Inception模块的参数。
什么意思呢?简单来说就是:以前为了分布式,往往限制改变网络的组成部分,即为了维护稳定,一般不会大幅度的改变网络组成结构,但是由于使用tensorflow,就可以不必有此顾忌,于是为了模型更加简单,这里将Inception Model 进一步简单化,即将很多原先尺寸不一样的model都标准化,统一化,关于更多细节见论文3部分,最后看一下Invection V4整体的网络图:
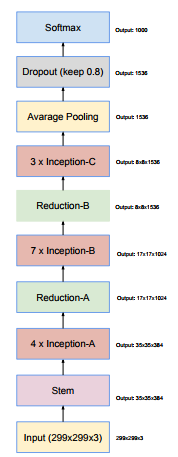
其中各个模块的详细构造:
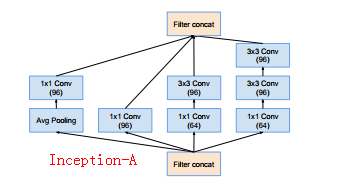



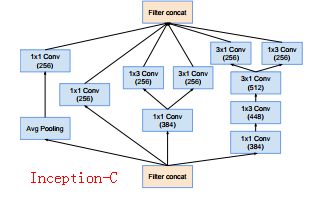
说明:
(1)在各个模块的详细构造中不难发现有“V”的标识,带有V的卷积层代表采用的不是“SAME” padding方式即输入输出层的size不一样,相反不带有V的卷积层采用的是SAME,输入输出层size一样
(2)Reduction-A中还有k,l,m,n,其在不同的网络中参数大小不一样,具体为:
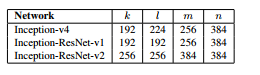
为了验证我这里就简单计算一下,就以Reduction-A为例:
从总的网络图中可以看到该层的输入大小为35*35*384,输出为17*17*1024
宽和高我们这里就不多讲了,相应的公式大家也很熟悉,我们主要看一下channels是怎么由384变到1024的
首先Reduction-A层最左面的Maxpool的输出channel还是384
然后从上图中我们得到k,l,m,n分别是192,224,256,384,
那么中间这一3*3卷积层输出channels应该就是n即384
最右面的输出channels应该就是m即256
所以叠加后就是384+384+256=1024
Inception-ResNet
作者在设计Inception-ResNet网络的时候,已经试过很多尺寸不同的ResNet模块,最后为了对比,论文中给出了两种网络结构即
Inception-ResNet-V1和Inception-ResNet-V2,其中V1是为了和之前的Inception V3作比较,Inception-ResNet-V2是为了和Inception V4做比较
两者有着共同的整体网络:如下
但是V1和V2的每个模块的具体构造并不是相同的,为了对比,具体模块的具体设计在计算复杂度上都参考了各自的比较对象,尽量和其比较对象相同,这样比较性能才有意义对吧
V1模块的具体构造:






V2模块的具体构造:

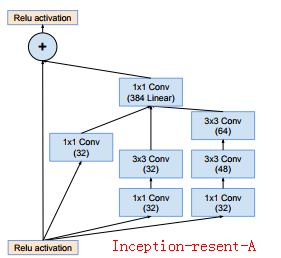



说明:
(1)Inception V4、Inception-ResNet-V1、Inception-ResNet-V2三种网络的整体网络外观相同,但是具体model是不一样
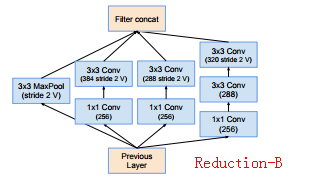
(2)Inception V4、Inception-ResNet-V1、Inception-ResNet-V2的Redution-A网络的框架上构造是相同的,主要区别就是卷积核的个数不一样,即k,l,m,n个数不一样
(3)同理Inception-ResNet-V1、Inception-ResNet-V2的Reduction-B网络的框架构造上是相同的,但是主要区别就是卷积核的个数不相同
(4)Inception-ResNet-V1、Inception-ResNet-V2中的1*1卷积核后面都是没有使用激活函数
接着在论文3.3部分作者提出,在训练时发现,当filters的数目超过1000时,residual这种网络就会不稳定,过早“死亡”,即在经过几万次迭代后,平均池化层(整体网络图的Average Pooling)只会产生0,而且通过降低学习率或者BN(batch归一化)都不能解决。
ResNet的原作者也发现这个问题了,所以ResNet的作者建议two-parse training 即两个阶段训练,就是说先用一个低的学习率去训练(论文中称为warm-up phase),后面阶段再用一个大的学习率去训练,但Inception V4的作者们发现,当filters树非常大时,上面所说的第一个阶段即使采用0.00001也不能很好的解决不稳定性问题,而且第二阶段所采用的大学习率又破坏了之前训练得到的效果(小的学习率逐渐接近最优解,突然又来了个大的步伐,自然不好,按我们在传统的机器学习算法中,一般做法是先是采用大学习率,后使用小学习率),那到底有没有很好的解决方法呢?Inception V4的作者发现,单单缩小Shortcut Connection 结构中的residuals的输出就可以改善这一情况,模型如下:

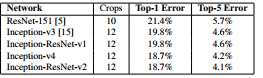
论文最后部分还给出了训练策略和对比性能结果,分别是论文的4和5部分,这里就不再展开叙述了,感兴趣的可以自行阅读,这里就简单展示一张论文中给出的其中一个对比结果图:
---------------------------------------------------------------------------------------------------------------------------
ResNet
2015年的冠军
其是由微软研究院的4名华人提出的
152层网络
ResNet原论文:https://arxiv.org/pdf/1512.03385.pdf
说到ResNet就不得不提到Schmidhuber教授,其设计灵感就是来源于教授的一篇Highway Network论文,这也是ResNet的最大贡献:
残差网络

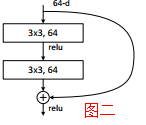
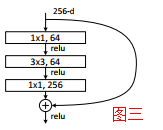
通过之前种种模型,大概可以得到这样一个小结论,网络越深,带来的性能越好,但实际上随着网络的加深,会发现错误率是一直减小,到达一个极限值后,又会增加,故模型貌似退化了,该问题产生的原因在于难以优化,当模型变复杂时,SGD的优化变得更加困难,导致了模型达不到好的学习效果为此,作者提出上图一的Shortcut Connection 结构(图中左半部分称为Residual,右面称为identity),它解决了一部分信息损失、消耗等等问题,这个简单的加法并不会给网络增加额外的参数和计算量,同时却可以大大增加模型的训练速度、提高训练效果,并且当模型的层数加深时,这个简单的结构能够很好的解决退化问题。上图二、三分别是ResNet的两层、三层残差网络模块,注意图三中的2个1*1卷积层,其过程相当于是先降维再升纬。
ResNet作者后面还进一步提出了ResNet v2,其是继续在残差网络模块上面做修改
下面图片来源:原论文:https://arxiv.org/pdf/1603.05027.pdf
其中(a)(e)分别对应最原始,和后面改进的ResNet即ResNet v1,ResNet v2
比较重要的结论就是:
1)不轻易改变”identity“分支的值,也就是输入与输出一致;
2)addition之后不再接改变信息分布的层;
五种结构的具体对比,可以参看原论文,英文不好可以看一下https://blog.csdn.net/lanran2/article/details/80247515的解析
在残差网络中有一点需要注意:

这是论文中给出的34-layer residual ,可以看到这里有很多弯弯的箭头,其实就是相当于Shortcut Connection 结构中的identity,而且这里有实线和虚线之分,那是因为图一中F(X)和X的channel有可能不相同,当相同时很简单就是直接相加即可即F(X)+X,即上图中的实线,

当不相同时:即虚线部分

说白了就是改变X,使得channel和F(X)匹配,更多细节请看论文3.2部分
最后给一下模型的详细参数:

说明:
我们在上面给出的图二这种两层残差网络模块多用在34-layer之前,而图三这种三层残差网络模块多用在50-layer之后,原因也很简单,因为随着网络加深,卷积厚度就不会不断加深,所需参数量也会不断增加,所以这里参考了以前的做法即用1*1卷积核降维,同时降维计算后,别忘了再将纬度还原回去,所以一般都是前后两个1*1卷积核,同时需要注意这里的名词,因为后续论文中都是会提到这些的,如果不注意可能看不懂,首先conv2_x这种的都就是一个模块,也叫做building block,其中对于采用了1*1降维又升纬的这种结构(图二)又称为bottleneck design,bottleneck很形象即为瓶口的意思如下图:先变窄(降维),再变粗(升维),而我们真真的卷积计算是在中间那一段比较窄的地方进行的,减少了参量,那么较少了多少呢?就拿152-layer的conv2_x来举例吧:
使用了bottleneck design:1*1*256*64+3*3*64*64+1*1*64*256=69632
没有使用bottleneck design:3*3*256*256=589824
589824/69632=8.5
可见减少了大概8.5倍

在论文给出的几种模型中,ResNet50和ResNet101被使用的概率最高。下面就给出ResNet50具体的网络图示意一下:

总之ResNet带来的最大贡献就是:
残差网络
---------------------------------------------------------------------------------------------------------------------------
CNN最新其它模型:
待更新,,,,,,,,,,,,,,,
---------------------------------------------------------------------------------------------------------------------------
CNN模型介绍总结:
(1)按照历史发展我们可以看到由CNN演变出来的模型多种多样,总体趋势是越来越深
(2)发展顺序:LeNet-->AlexNet(2012冠军)-->ZF-Net(2013冠军)-->VGGNet(2014亚军)-->Inception(2014冠军)-->ResNet(2015冠军)
(3)LeNet首次使用了CNN,AlexNet使得卷积加池化成了标配以及使用了NB,VGGNet首次探索了深度与性能的关系,Inception首次探索了宽度与性能的关系,ResNet创造性的提出了残差网络
(4)增加深度上面带来的性能好于增加宽度,原则上越深带来的性能越好
(5)目前CNN的各种模型在图像领域可以说已经表现的很好了,但是仍有提升的空间
------------------------------------------------------------------------------------------------
RNN有关模型发展历史:
RNN综述:
RNN可以说是深度学习的另外一个派系了吧,如果说CNN是为了解决图像问题而发展起来的话,那么RNN就是为了解决和时间序列有关问题而发展起来的,比如语音,音乐方面的问题,现如今RNN已经被广泛的应用在各个领域了,在RNN的多种模型中,LSTM的出现无疑给其带来了春天,随后有更多的研究探索相继出现,可以看做是LSTM的变体,这其中很多模型的名字,大家或多或少应该都听过,所以这里就重点看一下LSTM吧
本节的图片大部分来源于:《Understanding LSTM Networks》一文
---------------------------------------------------------------------------------------------------------------------------
传统RNN
传统的RNN是基于这样一个场景:比如读一篇文章,当前的所获所得,不但和当前读到的文字有关,而且和度过的文字也有很大关系,话句话说当前的输出不但和当前的状态有关,而且和以前的状态有关,其模型如下:
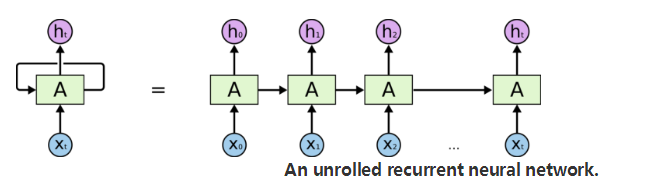
-------------------------------------------------------------------------------------------------------------------------
LSTM
传统的RNN在短期记忆问题上表现的很好,但是在长期记忆方面记忆很差,例如预测当前单词,其能利用的上下文就是仅仅是紧挨其的几个单词,对于距离其较远的单词,其似乎不太关心,或者说记不住哈哈哈,为此为了LSTM出现了

如上图记不住


上图中一个绿色小框就称为一个cell,第一幅图是传统的RNN,第二幅图是LSTM,可以看到其两者的不同就在于cell内部的具体实现,传统的RNN比较简单,就是一个tanh层,而LSTM则比较复杂
先来看一下图中符号的具体含义:

黄色就是代表具体的网络层,其内部的参数就是我们通过训练要学习的参数,粉色代表的就是一些运算,箭头就是一些矩阵转换,复杂等操作

LSTM之所以能够实现长期记忆的关键就是一条类似传送带的数据流向设计,可以简单地这样看:其和传统的最大区别就是将以前的数据直接传送到当前,保证了当前能够直接使用以前的数据,即记得以前的数据
接下来就来看看LSTM内部大名鼎鼎的三个门吧:
遗忘门:

是一个值域0到1的函数,我们考虑两个极端,当
时,其和
相乘结果就是0,换句话说即使丢弃了以往的所有信息,相反当为1时就是保留了以往的所有信息,所以
可以简单形象的看做是一个信息通过率的控制器,注意后面门中的
函数功能都可以这么看
总之遗忘门的功能就是:遗忘掉那些以往信息中该遗忘的信息或者说保留下以往信息中那些该保留的信息
传入门:

和遗忘门功能相比较的话,传入门的功能就是:遗忘掉那些新输入信息中该遗忘的信息或者说保留下新输入信息中那些该保留的信息
这里的毫无疑问又是一个信息通过率控制器,其控制的是
,而
是备选的用来更新的内容,更简单的可以看做是新输入值

上图就是c的更新值,从这里也可以看出来:和
分别代表以往信息和当前新输入值,
和
分别代表以往信息的通过率和当前新输入的通过率,而最后的
正好就是以往信息和新输入信息的总和
输出门:

还是充当一个通过率的角色,这里将
通过了一个tanh层作为了输出,并将其乘以
作为了最终输出
LSTM的变体:
文中还提到了LSTM的很多变体:



其中第三种的GRU也是很出名,其便为了两个门,即相当于合并了遗忘门和传送门
It combines the forget and input gates into a single “update gate.” It also merges the cell state and hidden state, and makes some other changes. The resulting model is simpler than standard LSTM models, and has been growing increasingly popular.
------------------------------------------------------------------------------------------------
其他一些琐碎的注意点:
<1>自编码:实现高阶特征提取
<2> Dropout(避免过拟合)、Relu(防止梯度弥散)、adagrade(自动学习率)
<3>卷积层其实更多的时候(SAME)不是减少了图片的尺寸,其目的主要就是提取了多个特征(厚度加大,出发点是:使训练参数尽量少,于是采用了一个filter只有一小部分参数),池化层的目的是减少尺寸,所以最后得到的图片的尺寸一般可以这样来看:
看看一共经过了几个池化层(比如说都是2*2),比如是3个吧,再看看最后一个卷积层使用了多少个卷积核比如16个吧,那么最终的图片大小就是:原始高度*(1/3)*原始宽度(1/3)*16
<4>Weights权值的初始化:随机加入一些噪声例如截断的正态分布,打破完全对称,同时因为激活函数是ReLu,所以加入一些小的正值避免过拟合,其实就是将bias初始化为例如0.1
<5> 对var进行了L2正则化



tf.nn.softmax(x*w+b)是将结果转化为了概率,而计算loss的时候又用到了coss_entropy即ylog(y*),而这里的tf.nn.sparse_softmax_corss_entropy_with_logits是将两则进行了结合。
<6>
tf.add_to_collection是把多个变量放入一个自己y用引号命名的集合里,也就是把多个变量统一放在一个列表中。
tf.get_collection与之相反,是从列表中取出所有元素,构成一个新的列表。