- case
SELECT
CASE atta_type WHEN '1' THEN '原稿、任务文件、试译文件' WHEN '2' THEN '初稿' WHEN '3' THEN '中间稿' WHEN '4' THEN '终稿' WHEN '5' THEN '参考文件' END AS attaTypeName,
date_format(a.upload_time,'%Y-%m-%d %H:%i') AS uploadTime
FROM t_common_atta a
WHERE a.del_state = '1'
<if test="list != null">
and a.id in
<foreach collection="list" index="index" item="item" open="(" separator="," close=")">#{item}</foreach>
</if>
- CONCAT
CONCAT(str1,str2,…)
返回结果为连接参数产生的字符串。如有任何一个参数为NULL ,则返回值为 NULL。
注意:
如果所有参数均为非二进制字符串,则结果为非二进制字符串。
如果自变量中含有任一二进制字符串,则结果为一个二进制字符串。
一个数字参数被转化为与之相等的二进制字符串格式;若要避免这种情况,可使用显式类型 cast, 例如:
SELECT CONCAT(CAST(int_col AS CHAR), char_col)
MySQL的concat函数可以连接一个或者多个字符串,如
mysql> select concat('10');
+--------------+
| concat('10') |
+--------------+
| 10 |
+--------------+
1 row in set (0.00 sec)
mysql> select concat('11','22','33');
+------------------------+
| concat('11','22','33') |
+------------------------+
| 112233 |
+------------------------+
1 row in set (0.00 sec)
MySQL的concat函数在连接字符串的时候,只要其中一个是NULL,那么将返回NULL
mysql> select concat('11','22',null);
+------------------------+
| concat('11','22',null) |
+------------------------+
| NULL |
+------------------------+
1 row in set (0.00 sec)
- concat_ws
使用方法:
CONCAT_WS(separator,str1,str2,…)
CONCAT_WS() 代表 CONCAT With Separator ,是CONCAT()的特殊形式。第一个参数是其它参数的分隔符。分隔符的位置放在要连接的两个字符串之间。分隔符可以是一个字符串,也可以是其它参数。
注意:
如果分隔符为 NULL,则结果为 NULL。函数会忽略任何分隔符参数后的 NULL 值。
如连接后以逗号分隔
mysql> select concat_ws(',','11','22','33');
+-------------------------------+
| concat_ws(',','11','22','33') |
+-------------------------------+
| 11,22,33 |
+-------------------------------+
1 row in set (0.00 sec)
和MySQL中concat函数不同的是, concat_ws函数在执行的时候,不会因为NULL值而返回NULL
mysql> select concat_ws(',','11','22',NULL);
+-------------------------------+
| concat_ws(',','11','22',NULL) |
+-------------------------------+
| 11,22 |
+-------------------------------+
1 row in set (0.00 sec)
- group_concat
group_concat([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator ‘分隔符’])
SELECT * FROM testgroup
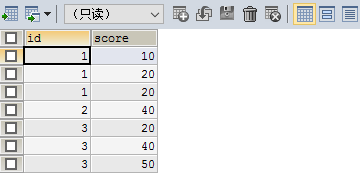
表结构与数据如上
现在的需求就是每个id为一行 在前台每行显示该id所有分数
group_concat 上场!!!
SELECT id,GROUP_CONCAT(score) FROM testgroup GROUP BY id
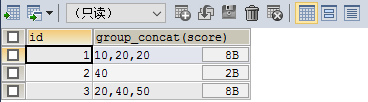
可以看到 根据id 分成了三行 并且分数默认用 逗号 分割 但是有每个id有重复数据 接下来去重
SELECT id,GROUP_CONCAT(DISTINCT score) FROM testgroup GROUP BY id
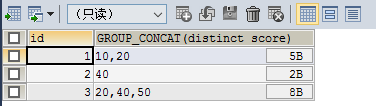
排序
SELECT id,GROUP_CONCAT(score ORDER BY score DESC) FROM testgroup GROUP BY id
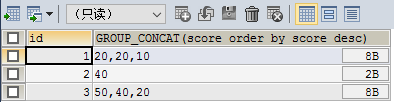
最后可以设置分隔符
SELECT id,GROUP_CONCAT(score SEPARATOR ';') FROM testgroup GROUP BY id

这样我们的数据就根据id 不同分隔符 放在了一行 前台可以根绝对应的分隔符 对score 字段进行分割 但是有可能存在score 数据类型过大问题
- repeat
用来复制字符串,如下’ab’表示要复制的字符串,2表示复制的份数
mysql> select repeat('ab',2);
+----------------+
| repeat('ab',2) |
+----------------+
| abab |
+----------------+
1 row in set (0.00 sec)
又如
mysql> select repeat('a',2);
+---------------+
| repeat('a',2) |
+---------------+
| aa |
+---------------+
1 row in set (0.00 sec)
- exists 和 in
select * from student s where EXISTS(select stuid from score ss where ss.stuid = s.stuid)
select * from student s where s.stuid in(select stuid from score ss where ss.stuid = s.stuid)
区别及应用场景:
in 和 exists的区别: 如果子查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用in, 反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用exists。其实我们区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询,所以我们会以驱动表的快速返回为目标,那么就会考虑到索引及结果集的关系了 ,另外IN时不对NULL进行处理。
in 是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。一直以来认为exists比in效率高的说法是不准确的。
not in 和not exists
如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。