目录
· 概况
· 构建流
· 由值创建流
· 由数组创建流
· 由文件生成流
· 并行流
概况
1. Stream API:以声明性方式处理数据集合,即说明想要完成什么(比如筛选热量低的菜肴)而不是说明如何实现一个操作(利用循环和if条件等控制流语句)。
2. Stream API特点
a) 流水线:很多流操作本身会返回一个流,这样多个操作就可以链接起来,形成一个大的流水线。这让可实现延迟和短路优化。
b) 内部迭代:与使用迭代器显式迭代的集合不同,流的迭代操作是在背后进行的。
3. Stream(流):从支持数据处理操作的源生成的元素序列(A sequence of elements from a source that supports data processing operations)。
a) 元素序列:与集合类似,流也提供了一个接口(java.util.stream.Stream),可以访问特定元素类型的一组有序值。因为集合是数据结构,所以它的主要目的是以特定的时间/空间复杂度存储和访问元素(如ArrayList、LinkedList);但流的目的在于表达计算,比如filter、sorted和map。
b) 源:流会使用一个提供数据的源,如集合、数组或输入/输出。注意,从有序集合生成流时会保留原有的顺序。
c) 数据处理操作:流的数据处理功能支持类似于数据库的操作,以及函数式编程语言中的常用操作,如filter、map、reduce、find、match、sort等。流操作可以顺序执行,也可并行执行。
4. 流操作分类
a) 中间操作(Intermediate Operations):可以连接起来的流操作,并不会生成任何结果。
b) 终端操作(Terminal Operations):关闭流的操作,处理流水线以返回结果。
c) 常用中间操作
| 操作 |
返回类型 |
操作参数 |
函数描述符 |
| filter |
Stream<T> |
Predicate<T> |
T -> boolean |
| map |
Stream<R> |
Function<T, R> |
T -> R |
| limit |
Stream<T> |
|
|
| sorted |
Stream<T> |
Comparator<T> |
(T, T) -> R |
| distinct |
Stream<T> |
|
d) 常用终端操作
| 操作 |
目的 |
| forEach |
消费流中的每个元素并对其应用Lambda。这一操作返回void。 |
| count |
返回流中元素的个数。这一操作返回long。 |
| collect |
把流归约成一个集合,比如List、Map甚至是Integer。 |
5. 举例
a) Dish.java(后续举例将多次使用到该类)
1 public class Dish { 2 private final String name; 3 private final boolean vegetarian; 4 private final int calories; 5 private final Type type; 6 7 public enum Type {MEAT, FISH, OTHER} 8 9 public Dish(String name, boolean vegetarian, int calories, Type type) { 10 this.name = name; 11 this.vegetarian = vegetarian; 12 this.calories = calories; 13 this.type = type; 14 } 15 16 public String getName() { 17 return name; 18 } 19 20 public boolean isVegetarian() { 21 return vegetarian; 22 } 23 24 public int getCalories() { 25 return calories; 26 } 27 28 public Type getType() { 29 return type; 30 } 31 32 @Override 33 public String toString() { 34 return name; 35 } 36 37 }
b) DishUtils.java(后续举例将多次使用到该类)
1 import java.util.Arrays; 2 import java.util.List; 3 4 public class DishUtils { 5 6 public static List<Dish> makeMenu() { 7 return Arrays.asList( 8 new Dish("pork", false, 800, Dish.Type.MEAT), 9 new Dish("beef", false, 700, Dish.Type.MEAT), 10 new Dish("chicken", false, 400, Dish.Type.MEAT), 11 new Dish("french fries", true, 530, Dish.Type.OTHER), 12 new Dish("rice", true, 350, Dish.Type.OTHER), 13 new Dish("season fruit", true, 120, Dish.Type.OTHER), 14 new Dish("pizza", true, 550, Dish.Type.OTHER), 15 new Dish("prawns", false, 300, Dish.Type.FISH), 16 new Dish("salmon", false, 450, Dish.Type.FISH)); 17 } 18 19 public static <T> void printList(List<T> list) { 20 for (T i : list) { 21 System.out.println(i); 22 } 23 } 24 25 }
c) Test.java
1 import java.util.List; 2 3 import static java.util.stream.Collectors.toList; 4 5 public class Test { 6 7 public static void main(String[] args) { 8 List<String> names = DishUtils.makeMenu().stream() // 获取流 9 .filter(d -> d.getCalories() > 300) // 中间操作,选出高热量菜 10 .map(Dish::getName) // 中间操作,获取菜名 11 .limit(3) // 中间操作,选出前三 12 .collect(toList()); // 终端操作,将结果保存在List中 13 DishUtils.printList(names); 14 15 DishUtils.makeMenu().stream() 16 .filter(d -> d.getCalories() > 300) 17 .map(Dish::getName) 18 .limit(3) 19 .forEach(System.out::println); // 遍历并打印 20 } 21 22 }
d) 示意图
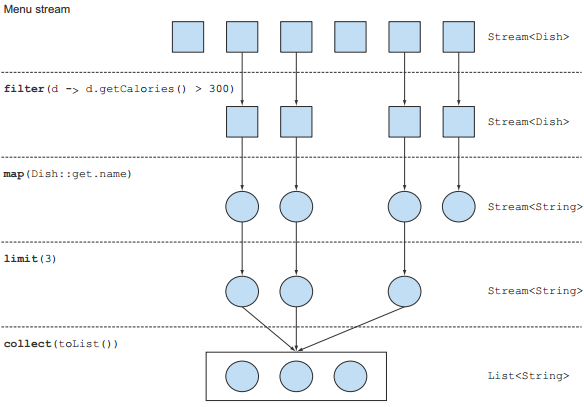
筛选(Filtering)
1. 筛选相关方法
a) filter()方法:使用Predicate筛选流中元素。
b) distinct()方法:调用流中元素的hashCode()和equals()方法去重元素。
2. 举例
1 import java.util.Arrays; 2 import java.util.List; 3 import static java.util.stream.Collectors.toList; 4 // filter()方法 5 List<Dish> vegetarianMenu = DishUtils.makeMenu().stream() 6 .filter(Dish::isVegetarian) 7 .collect(toList()); 8 DishUtils.printList(vegetarianMenu); 9 System.out.println("-----"); 10 // distinct()方法 11 List<Integer> numbers = Arrays.asList(1, 2, 1, 3, 3, 2, 4); 12 numbers.stream() 13 .filter(i -> i % 2 == 0) 14 .distinct() 15 .forEach(System.out::println);
切片(Slicing)
1. 切片相关方法
a) limit()方法:返回一个不超过给定长度的流。
b) skip()方法:返回一个扔掉了前n个元素的流。如果流中元素不足n个,则返回一个空流。
2. 举例
1 import java.util.List; 2 import static java.util.stream.Collectors.toList; 3 // limit()方法 4 List<Dish> dishes1 = DishUtils.makeMenu().stream() 5 .filter(d -> d.getCalories() > 300) 6 .limit(3) 7 .collect(toList()); 8 DishUtils.printList(dishes1); 9 System.out.println("-----"); 10 // skip()方法 11 List<Dish> dishes2 = DishUtils.makeMenu().stream() 12 .filter(d -> d.getCalories() > 300) 13 .skip(2) 14 .collect(toList()); 15 DishUtils.printList(dishes2);
映射(Mapping)
1. 映射相关方法
a) map()方法:接受一个函数作为参数,该函数用于将每个元素映射成一个新的元素。
b) flatMap()方法:接受一个函数作为参数,该函数用于将每个数组元素映射成新的扁平化流。
c) 注意:map()、flatMap()方法都不会修改原元素。
2. 举例
1 import java.util.Arrays; 2 import java.util.List; 3 import static java.util.stream.Collectors.toList; 4 // map()方法 5 List<Integer> dishNameLengths = DishUtils.makeMenu().stream() 6 .map(Dish::getName) 7 .map(String::length) 8 .collect(toList()); 9 DishUtils.printList(dishNameLengths); 10 System.out.println("-----"); 11 // flatMap()方法 12 String[] arrayOfWords = {"Goodbye", "World"}; 13 Arrays.stream(arrayOfWords) 14 .map(w -> w.split("")) // 将每个单词转换为由其字母构成的数组 15 .flatMap(Arrays::stream) // 将各个生成流扁平化为单个流 16 .distinct() // 去重 17 .forEach(System.out::println);
匹配(Matching)
1. 匹配相关方法
a) anyMatch()方法:检查流中是否有一个元素能匹配给定的Predicate。
b) allMatch()方法:检查流中是否所有元素能匹配给定的Predicate。
c) noneMatch()方法:检查流中是否所有元素都不匹配给定的Predicate。
2. 举例
1 // anyMatch()方法 2 if (DishUtils.makeMenu().stream().anyMatch(Dish::isVegetarian)) { 3 System.out.println("The menu is (somewhat) vegetarian friendly!!"); 4 } 5 // allMatch()方法 6 boolean isHealthy1 = DishUtils.makeMenu().stream() 7 .allMatch(d -> d.getCalories() < 1000); 8 System.out.println(isHealthy1); 9 // noneMatch()方法 10 boolean isHealthy2 = DishUtils.makeMenu().stream() 11 .noneMatch(d -> d.getCalories() >= 1000); 12 System.out.println(isHealthy2);
查找(Finding)
1. 查找相关方法
a) findAny()方法:返回当前流中的任意元素,返回类型为java.util.Optional(Java 8用于解决NullPointerException的新类)。
b) findFirst()方法:与findAny()方法类似,区别在于返回第一个元素。
2. 举例
1 import java.util.Arrays; 2 import java.util.List; 3 import java.util.Optional; 4 // findAny()方法 5 Optional<Dish> dish = DishUtils.makeMenu().stream() 6 .filter(Dish::isVegetarian) 7 .findAny(); 8 System.out.println(dish.get()); // french fries 9 // findFirst()方法 10 List<Integer> someNumbers = Arrays.asList(1, 2, 3, 4, 5); 11 Optional<Integer> firstSquareDivisibleByThree = someNumbers.stream() 12 .map(x -> x * x) 13 .filter(x -> x % 3 == 0) 14 .findFirst(); // 9 15 System.out.println(firstSquareDivisibleByThree.get());
归约(Reducing)
1. 归约相关方法
a) reduce()方法:把一个流中的元素组合起来,也叫折叠(fold)。
i. 如果指定初始值,则直接返回归约结果值。
ii. 如果不指定初始值,则返回Optional。
2. 举例
1 import java.util.ArrayList; 2 import java.util.List; 3 import java.util.Optional; 4 List<Integer> numbers = new ArrayList<>(); 5 for (int n = 1; n <= 100; n++) { 6 numbers.add(n); 7 } 8 // 元素求和 9 int sum1 = numbers.stream().reduce(0, (a, b) -> a + b); // 指定初始值0 10 System.out.println(sum1); 11 Optional<Integer> sum2 = numbers.stream().reduce((a, b) -> a + b); // 不指定初始值0 12 System.out.println(sum2); 13 int sum3 = numbers.stream().reduce(0, Integer::sum); // 方法引用 14 System.out.println(sum3); 15 // 最大值 16 Optional<Integer> max1 = numbers.stream().reduce((a, b) -> a < b ? b : a); // Lambda表达式 17 System.out.println(max1); 18 Optional<Integer> max2 = numbers.stream().reduce(Integer::max); // 方法引用 19 System.out.println(max2); 20 // 统计个数 21 int count1 = DishUtils.makeMenu().stream() 22 .map(d -> 1) 23 .reduce(0, (a, b) -> a + b); // MapReduce编程模型,更易并行化 24 System.out.println(count1); 25 long count2 = DishUtils.makeMenu().stream().count(); 26 System.out.println(count2);
排序(Sorting)
1. 排序相关方法
a) sorted()方法:根据指定的java.util.Comparator规则排序。
2. 举例
1 import static java.util.Comparator.comparing; 2 DishUtils.makeMenu().stream() 3 .sorted(comparing(Dish::getCalories)) 4 .forEach(System.out::println);
数值流(Numeric streams)
原始类型流(Primitive stream)
1. 使用目的:避免自动装箱带来的开销。
2. 相关方法
a) mapToInt():将流转换为原始类型流IntStream。
b) mapToDouble():将流转换为原始类型流DoubleStream。
c) mapToLong():将流转换为原始类型流LongStream。
d) boxed():将原始类型流转换为对象流。
3. Optional的原始类型版本:OptionalInt、OptionalDouble和OptionalLong。
4. 举例
1 import java.util.OptionalInt; 2 import java.util.stream.IntStream; 3 import java.util.stream.Stream; 4 // 映射到数值流 5 int calories = DishUtils.makeMenu().stream() // 返回Stream<Dish> 6 .mapToInt(Dish::getCalories) // 返回IntStream 7 .sum(); 8 System.out.println(calories); 9 // 转换回对象流 10 IntStream intStream = DishUtils.makeMenu().stream().mapToInt(Dish::getCalories); // 将Stream 转换为数值流 11 Stream<Integer> stream = intStream.boxed(); // 将数值流转换为Stream 12 // OptionalInt 13 OptionalInt maxCalories = DishUtils.makeMenu().stream() 14 .mapToInt(Dish::getCalories) 15 .max(); 16 int max = maxCalories.orElse(1); // 如果没有最大值的话,显式提供一个默认最大值 17 System.out.println(max);
数值范围(Numeric ranges)
1. 数值范围相关方法
a) range()方法:生成起始值到结束值范围的数值,不包含结束值。
b) rangeClosed()方法:生成起始值到结束值范围的数值,包含结束值。
2. 举例
1 import java.util.stream.IntStream; 2 IntStream.range(1, 5).forEach(System.out::println); // 1~4 3 IntStream.rangeClosed(1, 5).forEach(System.out::println); // 1~5
构建流
由值创建流
1. 举例
a) Stream.of()方法
1 import java.util.stream.Stream; 2 Stream<String> stream = Stream.of("Java 8 ", "Lambdas ", "In ", "Action"); 3 stream.map(String::toUpperCase).forEach(System.out::println);
b) 空流
1 import java.util.stream.Stream; 2 Stream<String> emptyStream = Stream.empty();
由数组创建流
1. 举例
1 int[] numbers = {2, 3, 5, 7, 11, 13}; 2 int sum = Arrays.stream(numbers).sum(); 3 System.out.println(sum); // 41
由文件生成流
1. 举例
1 try (Stream<String> lines = Files.lines(Paths.get("data.txt"), Charset.defaultCharset())) { 2 long uniqueWords = lines.flatMap(line -> Arrays.stream(line.split(" "))) 3 .distinct() 4 .count(); 5 System.out.println(uniqueWords); 6 } catch (IOException e) { 7 e.printStackTrace(); 8 }
由函数生成流(创建无限流)
1. 无限流:没有固定大小的流。
2. 相关方法
a) Stream.iterate()方法:生成无限流,其初始值为第1个参数,下一个值由第2个参数的Lambda表达式生成。
b) Stream.generate()方法:生成无限流,其值由参数的Lambda表达式生成。
3. 注意:一般,应该使用limit(n)对无限流加以限制,以避免生成无穷多个值。
4. 举例
1 Stream.iterate(0, n -> n + 2) 2 .limit(5) 3 .forEach(System.out::println); // 0 2 4 6 8 4 Stream.generate(Math::random) 5 .limit(5) 6 .forEach(System.out::println);
collect()高级用法
归约和汇总(Reducing and summarizing)
1. 举例
a) 按元素某字段查找最大值
1 import java.util.Comparator; 2 import java.util.Optional; 3 import static java.util.stream.Collectors.maxBy; 4 Comparator<Dish> dishCaloriesComparator = Comparator.comparingInt(Dish::getCalories); 5 Optional<Dish> mostCalorieDish = DishUtils.makeMenu().stream() 6 .collect(maxBy(dishCaloriesComparator)); 7 System.out.println(mostCalorieDish);
b) 按元素某字段求和
1 import static java.util.stream.Collectors.summingInt; 2 int totalCalories = DishUtils.makeMenu().stream().collect(summingInt(Dish::getCalories)); 3 System.out.println(totalCalories);
c) 按元素某字段求平均值
1 import static java.util.stream.Collectors.averagingInt; 2 double avgCalories = DishUtils.makeMenu().stream().collect(averagingInt(Dish::getCalories)); 3 System.out.println(avgCalories);
d) 连接字符串
1 import static java.util.stream.Collectors.joining; 2 String shortMenu = DishUtils.makeMenu().stream().map(Dish::getName).collect(joining(", ")); 3 System.out.println(shortMenu);
e) 广义归约
1 // 所有热量求和 2 import static java.util.stream.Collectors.reducing; 3 // i.e. 4 // int totalCalories = DishUtils.makeMenu().stream() 5 // .mapToInt(Dish::getCalories) // 转换函数 6 // .reduce(0, Integer::sum); // 初始值、累积函数 7 int totalCalories = DishUtils.makeMenu().stream() 8 .collect(reducing( 9 0, // 初始值 10 Dish::getCalories, // 转换函数 11 Integer::sum)); // 累积函数 12 System.out.println(totalCalories);
分组(Grouping)
1. 分组:类似SQL语句的group by,区别在于这里的分组可聚合(即SQL的聚合函数),也可不聚合。
2. 举例
a) 简单分组
1 Map<Dish.Type, List<Dish>> dishesByType = DishUtils.makeMenu().stream() 2 .collect(groupingBy(Dish::getType)); 3 System.out.println(dishesByType); // {FISH=[prawns, salmon], MEAT=[pork, beef, chicken], OTHER=[french fries, rice, season fruit, pizza]}
b) 复杂分组
1 import static java.util.stream.Collectors.groupingBy; 2 public enum CaloricLevel {DIET, NORMAL, FAT} 3 Map<CaloricLevel, List<Dish>> dishesByCaloricLevel = DishUtils.makeMenu().stream().collect( 4 groupingBy(dish -> { 5 if (dish.getCalories() <= 400) return CaloricLevel.DIET; 6 else if (dish.getCalories() <= 700) return CaloricLevel.NORMAL; 7 else return CaloricLevel.FAT; 8 })); 9 System.out.println(dishesByCaloricLevel); // {NORMAL=[beef, french fries, pizza, salmon], DIET=[chicken, rice, season fruit, prawns], FAT=[pork]}
c) 多级分组
1 import static java.util.stream.Collectors.groupingBy; 2 public enum CaloricLevel {DIET, NORMAL, FAT} 3 Map<Dish.Type, Map<CaloricLevel, List<Dish>>> dishesByTypeCaloricLevel = DishUtils.makeMenu().stream().collect( 4 groupingBy(Dish::getType, // 一级分类函数 5 groupingBy(dish -> { // 二级分类函数 6 if (dish.getCalories() <= 400) return CaloricLevel.DIET; 7 else if (dish.getCalories() <= 700) return CaloricLevel.NORMAL; 8 else return CaloricLevel.FAT; 9 }) 10 ) 11 ); 12 System.out.println(dishesByTypeCaloricLevel); 13 // {FISH={NORMAL=[salmon], DIET=[prawns]}, MEAT={NORMAL=[beef], DIET=[chicken], FAT=[pork]}, OTHER={NORMAL=[french fries, pizza], DIET=[rice, season fruit]}}
d) 分组聚合
1 import static java.util.Comparator.comparingInt; 2 import static java.util.stream.Collectors.groupingBy; 3 import static java.util.stream.Collectors.counting; 4 Map<Dish.Type, Long> typesCount = DishUtils.makeMenu().stream() 5 .collect(groupingBy(Dish::getType, counting())); 6 System.out.println(typesCount); // {FISH=2, MEAT=3, OTHER=4} 7 8 Map<Dish.Type, Optional<Dish>> mostCaloricByType1 = DishUtils.makeMenu().stream() 9 .collect(groupingBy(Dish::getType, maxBy(comparingInt(Dish::getCalories)))); 10 System.out.println(mostCaloricByType1); // {FISH=Optional[salmon], MEAT=Optional[pork], OTHER=Optional[pizza]} 11 12 Map<Dish.Type, Dish> mostCaloricByType2 = DishUtils.makeMenu().stream() 13 .collect(groupingBy(Dish::getType, // 分类函数 14 collectingAndThen( 15 maxBy(comparingInt(Dish::getCalories)), // 包装后的收集器 16 Optional::get))); // 转换函数 17 System.out.println(mostCaloricByType2); // {FISH=salmon, MEAT=pork, OTHER=pizza}
分区(Partitioning)
1. 分区:分区是分组的特殊情况,即根据Predicate<T>分组为true和false两组,因此分组后的Map的Key是Boolean类型。
2. 举例
1 import java.util.List; 2 import java.util.Map; 3 import java.util.Optional; 4 import static java.util.Comparator.comparingInt; 5 import static java.util.stream.Collectors.*; 6 Map<Boolean, List<Dish>> partitionedMenu = DishUtils.makeMenu().stream() 7 .collect(partitioningBy(Dish::isVegetarian)); 8 System.out.println(partitionedMenu); 9 // {false=[pork, beef, chicken, prawns, salmon], true=[french fries, rice, season fruit, pizza]} 10 11 Map<Boolean, Map<Dish.Type, List<Dish>>> vegetarianDishesByType = DishUtils.makeMenu().stream() 12 .collect(partitioningBy(Dish::isVegetarian, groupingBy(Dish::getType))); 13 System.out.println(vegetarianDishesByType); 14 // {false={FISH=[prawns, salmon], MEAT=[pork, beef, chicken]}, true={OTHER=[french fries, rice, season fruit, pizza]}} 15 16 Map<Boolean, Dish> mostCaloricPartitionedByVegetarian = DishUtils.makeMenu().stream() 17 .collect(partitioningBy(Dish::isVegetarian, collectingAndThen(maxBy(comparingInt(Dish::getCalories)), Optional::get))); 18 System.out.println(mostCaloricPartitionedByVegetarian); 19 // {false=pork, true=pizza}
并行流
1. 并行流:一个把内容分成多个数据块,并用不同的线程分别处理每个数据块的流。
2. 并行流相关方法
a) parallel()方法:将顺序流转换为并行流。
b) sequential()方法:将并行流转换为顺序流。
c) 以上两方法并没有对流本身有任何实际的变化,只是在内部设了一个boolean标志,表示让调用parallel()/sequential()之后进行的所有操作都并行/顺序执行。
3. 并行流原理:并行流内部默认使用ForkJoinPool,其默认的线程数为CPU核数(通过Runtime.getRuntime().availableProcessors()获取),同时支持通过系统属性设置(全局),比如:
System.setProperty('java.util.concurrent.ForkJoinPool.common.parallelism','12');
4. 何时并行流更有效?
a) 实测:在待运行的特定机器上,分别用顺序流和并行流做基准测试性能。
b) 注意装/拆箱:自动装箱和拆箱会大大降低性能,应避免。
c) 某些操作性能并行流比顺序流差:比如limit()和findFirst(),因为在并行流上执行代价较大。
d) 计算流操作流水线的总成本:设N是要处理的元素的总数,Q是一个元素通过流水线的大致处理成本,则N*Q就是这个对成本的一个粗略的定性估计。Q值较高就意味着使用并行流时性能好的可能性比较大。
e) 数据量较小时并行流比顺序流性能差:因为并行化会有额外开销。
f) 流背后的数据结构是否易于分解:见下表。
| 数据结构 |
可分解性 |
| ArrayList |
极佳 |
| LinkedList |
差 |
| IntStream.range |
极佳 |
| Stream.iterate |
差 |
| HashSet |
好 |
| TreeSet |
好 |
g) 流自身特点、流水线的中间操作修改流的方式,都可能会改变分解过程的性能:比如未执行筛选操作时,流被分成大小差不多的几部分,此时并行执行效率很高;但执行筛选操作后,可能导致这几部分大小相差较大,此时并行执行效率就较低。
h) 终端操作合并步骤的代价:如果该步骤代价很大,那么合并每个子流产生的部分结果所付出的代价就可能会超出通过并行流得到的性能提升。
5. 举例
1 // 顺序流 2 long sum1 = Stream.iterate(1L, i -> i + 1) 3 .limit(8) 4 .reduce(0L, Long::sum); 5 System.out.println(sum1); 6 // 并行流 7 long sum2 = Stream.iterate(1L, i -> i + 1) 8 .limit(8) 9 .parallel() 10 .reduce(0L, Long::sum); 11 System.out.println(sum2);

作者:netoxi
出处:http://www.cnblogs.com/netoxi
本文版权归作者和博客园共有,欢迎转载,未经同意须保留此段声明,且在文章页面明显位置给出原文连接。欢迎指正与交流。