前言
在分布式系统中,为了保证容错性,一般会维护多个副本集群,提高系统的高可用,但与之带来的问题就是多个副本的一致性(consensus)问题。
我们认为,对于一个具有一致性的的集群中,同一时刻所有节点对存储在其中的值都应该是相同的,并且在集群大部分节点可用时,集群也是可用的。
能完成这种一致性的协议,就叫一致性协议。
常见的分布式一致性协议有:
- 两阶段提交协议,
- 三阶段提交协议,
- 向量时钟,
- RWN协议,
- paxos协议,
- Raft协议等
所以本文说的raft协议,就是一种分布式一致性协议,他定义了易于实现一致性协议的实施标准,可以维护多个副本的一致性。
raft协议中,我们有以下规定:
1.集群中的节点,只有三种角色(leader,follower,candidate)
leader:
领导者,只有leader才能处理客户端请求,同步数据到其他实例。同时负责周期性的发送心跳包(heartbeat)到follower,目的是为了维持自己的leader角色。算法保证任何时刻都只存在一个合法的leader。
follower:
跟随者,被动接收RPC请求并做响应,比如leader请求添加日志数据,candidate请求选举。follower本身是被动的,不会主动发起RPC。
candidate:
候选人,当follower一段时间内没有收到leader的heartbeat(可能是leader挂了,可能是自己网络出问题了),就认为当前leader失效,转变为candidate角色。
2.term:任期,由一个唯一的id标识,每选举一次,term就会自增,leader永远是有最新的term。每个term一开始就会先进行选举:
3.LogEntry:客户端的一个命令对应一个LogEntry
raft协议中有两个重点(选举leader和日志复制):
1.Leader election(选举leader)
- follower将自己维护的current_term_id加1。
- 然后follower将自己的状态转成candidate(候选人)。
- 发送拉票消息给其它所有server
- 如果收到其他leader的消息,则证明有leader了;如果收到大部分的投票,就变成leader,同时通知其他人;否则重复123步骤
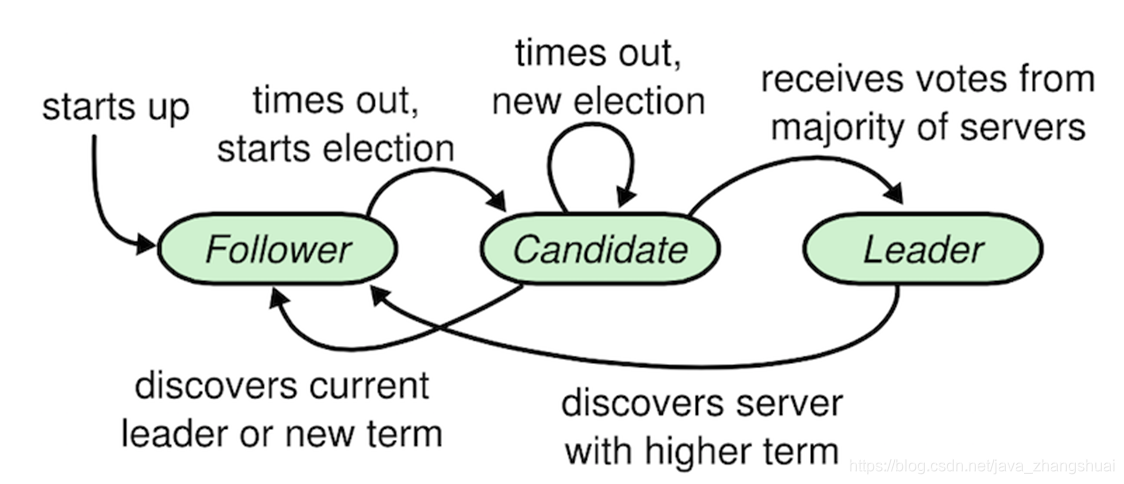
在上图这个选举的过程中,对于某个候选人,会有以下三种情况:
1.自己成为leader
获取相同term下超过半数的投票。
2.别人成为leader
candidate在等待投票的过程中,可能收到其他实例的AppendEntries RPCs,
如果发现RPC里参数的term >= 自身的currentTerm,那么就意识到已经有新的leader选出,自己败选,转为follower.
如果收到其他实例的RequestVote RPCs,发现RPC里的参数term > 自身的currentTerm,那么就意识到已经有新的term开始,转为follower.
3.没有选出leader
当投票被瓜分,没有任何一个candidate收到了majority的vote时,没有leader被选出。
这种情况下,每个candidate等待的投票的过程就超时了,接着candidates都会将本地的current_term_id再加1,发起拉票进行新一轮的leader election。
此外,影响成为leader的因素,不止任期,还有日志长度,日志长度的优先级低于任期的优先级。
总结来说,当一个实例收到RequestVote RPC时,要先判断任期是否大于本身,如果是,就直接投票,如果不是,再判断这个rpc的发送者的日志长度是不是小于等于自己,如果不是,就拒绝投票。
举个例子:
有A B C D E 5个实例
(1)A当选为leader,同步数据到D E并commit,之后D E宕机
(2)此时A网络断连,B C都成为candidate,不断自增term,但由于只有两个实例,无法满足大多数的条件
(3)A网络恢复,此时B C term都较高,因此A接收到RequestVote后转为follower
(4)A B C 3个实例,如果B C随机超时时间总是较短,那么总是能发出RequestVote RPC使得A转为follower一直无法参与选举
(5)由于A的日志里已经有commit的数据,此时规则需要保证A胜出
对于刚刚网络恢复的A来说,如果收到B或C的RequestVote RPC,会因为自己的日志长度大于B或C,从而拒绝投票,
那么B或C就得不到大多数的投票(5个实例,大多数至少是3票),最终引起选举超时,然后ABC将会重新开始选举,直到A发起投票,成为leader。
再说说上面例子中的选举超时:
为了尽可能避免平票的问题,同时就算平票,也能快速解决,选举超时的时间是很讲究的,
官网给定的是在(150ms~300ms)直接随机取一个超时时间。
如此一来,大多数情况下就只有一个节点会发起选举。
即使出现平票,每个节点又会在一个随机时间后(重置timer)开始新的选举,避免了重复平票。
(注意,这种随机的超时时间,是一种思想,不仅在选举中会用到,我们也要在其他场景中想到这种方案。)
选举超时重置的3种情况:
(1)candidate开始选举后,要重置timer
(2)如果收到RequestVote,只有在投票给对方转为follower的情况下,才重置
(3)如果收到AppendEntries,而且收到的term比自身大,则转为follwer并重置
2.Log Replication (日志复制)
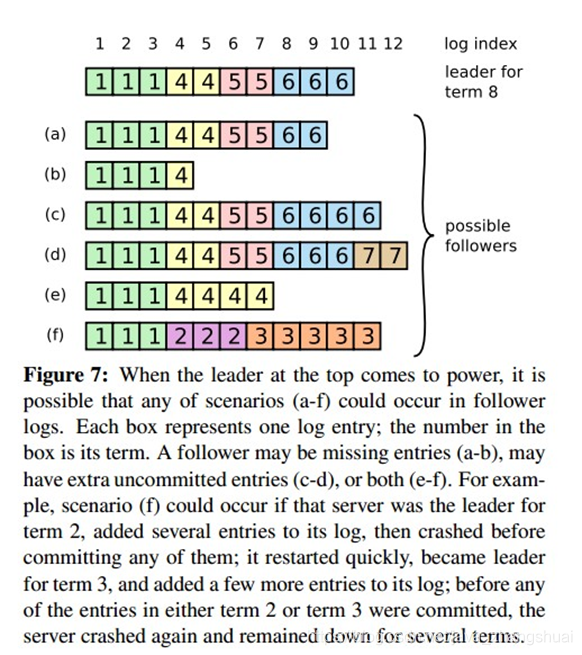
最上面这个是新leader,a~f是follower,每个格子代表一条log entry,格子内的数字代表这个log entry是在哪个term上产生的。
(1)a、b少数据
(2)c、d多数据
(3)e、f数据冲突
为什么leader和follower的日志是一致的:
需要有一种机制来让leader和follower对log达成一致,leader会为每个follower维护一个nextIndex(比如上图的1到12),表示leader给各个follower发送的下一条log entry在log中的index,初始化为leader的最后一条log entry的下一个位置。
leader给follower发送AppendEntriesRPC消息,带着(term_id, (nextIndex-1)), term_id即(nextIndex-1)这个槽位的log entry的term_id,
follower接收到AppendEntriesRPC后,会从自己的log中找是不是存在这样的log entry,如果不存在,就给leader回复拒绝消息,然后leader则将nextIndex减1,再重复,直到AppendEntriesRPC消息被接收。
以leader和b为例:
初始化,nextIndex为11,leader给b发送AppendEntriesRPC(6,10),
b在自己log的10号槽位中没有找到term_id为6的log entry。则给leader回应一个拒绝消息。
接着,leader将nextIndex减一,变成10,然后给b发送AppendEntriesRPC(6, 9),
b在自己log的9号槽位中同样没有找到term_id为6的log entry。
循环下去,直到leader发送了AppendEntriesRPC(4,4),
b在自己log的槽位4中找到了term_id为4的log entry,接收了消息。
随后,leader就可以从槽位5开始给b推送日志。
最后附上raft协议的原论文和中文翻译
原文:https://ramcloud.atlassian.net/wiki/download/attachments/6586375/raft.pdf
翻译:https://blog.csdn.net/chenhaifeng2016/article/details/54880091 (翻译难免会附加译者的思想,建议最好还是看原文,能感受到原作者的思想)