YARN的架构
YARN:
YARN的最基本思想是将JobTracker的两个主要职责:资源管理和Job调度管理分别交给两个角色负责。一个是全局的ResourceManager,一个是每个应用一个的ApplicationMaster。ResourceManager以及每个节点一个的NodeManager构成了新的通用系统,实现以分布式方式管理应用。
YARN的架构图
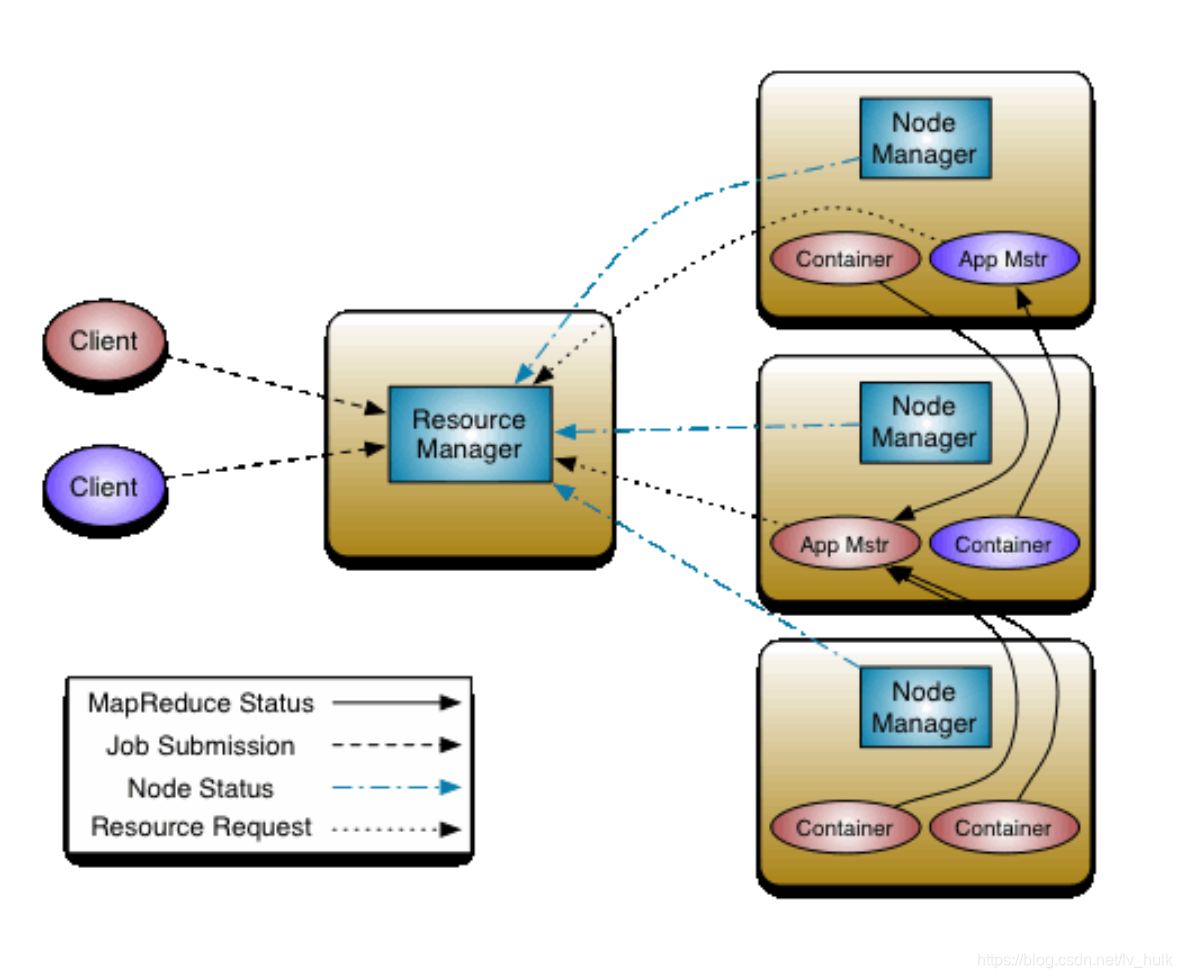
各角色职责:
ResouceManager
每个Hadoop集群只会有一个ResourceManager(如果是HA的话会存在两个,但是有且只有一个处于active状态),它负责管理整个集群的计算资源,并将这些资源分别给应用程序。
NodeManager
NodeManager是YARN中每个节点上的代理,它管理Hadoop集群中单个计算节点,根据相关的设置来启动容器的。NodeManager会定期向ResourceManager发送心跳信息来更新其健康状态。同时其也会监督Container的生命周期管理,监控每个Container的资源使用(内存、CPU等)情况,追踪节点健康状况,管理日志和不同应用程序用到的附属服务(auxiliary service)
ApplicationMaster
ApplicationMaster是应用程序级别的,每个ApplicationMaster管理运行在YARN上的应用程序。YARN 将 ApplicationMaster看做是第三方组件,ApplicationMaster负责和ResourceManager scheduler协商资源,并且和NodeManager通信来运行相应的task。ResourceManager 为 ApplicationMaster 分配容器,这些容器将会用来运行task。ApplicationMaster 也会追踪应用程序的状态,监控容器的运行进度。当容器运行完成, ApplicationMaster 将会向 ResourceManager 注销这个容器;如果是整个作业运行完成,其也会向 ResourceManager 注销自己,这样这些资源就可以分配给其他的应用程序使用了。
Container
Container是与特定节点绑定的,其包含了内存、CPU磁盘等逻辑资源。不过在现在的容器实现中,这些资源只包括了内存和CPU。容器是由 ResourceManager scheduler 服务动态分配的资源构成。容器授予 ApplicationMaster 使用特定主机的特定数量资源的权限。ApplicationMaster 也是在容器中运行的,其在应用程序分配的第一个容器中运行
YARN的优点
可扩展性
MapReduce 1 最多可支持4000个节点的集群.因为JobTracker负责的职责太多而成为瓶颈
Yarn 可以支持10000个节点,并行100000个task
可靠性
Yarn的ResourceManager职责很简单,很容易实现HA;
MapReduce 1 的JobTracker的状态变化非常迅速(想象下每个Task过几秒都会想它报告状态). 这使得JotTracker很难实现HA(高可用性).通常HA都是通过备份当前系统的状态然后当系统失败备用系统用备份的状态来继续工作.
并行性
MapReduce 1只能运行MapReduce应用Yarn最大的好处之一就是职称很多其他类型的分布式Application.
YARN的资源管理
1、资源调度和隔离是yarn作为一个资源管理系统,最重要且最基础的两个功能。资源调度由resourcemanager完成,而资源隔离由各个nodemanager实现。
2、ResourceManager将某个nodemanager上资源分配给任务(这就是所谓的“资源调度”)后,nodemanager需按照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础和保证,这就是所谓的资源隔离。
3、当谈及到资源时,我们通常指内存、cpu、io有一种资源。Hadoop yarn目前为止仅支持cpu和内存两种资源管理和调度。
4、内存资源多少决定任务的生死,如果内存不够,任务可能运行失败;相比之下,cpu资源则不同,它只会决定任务的快慢,不会对任务的生死产生影响。
Yarn的内存管理:
yarn允许用户配置每个节点上可用的物理内存资源,注意,这里是“可用的”,因为一个节点上的内存会被若干个服务共享,比如一部分给了yarn,一部分给了hdfs,一总价给了hbase等,yarn配置的啥时自己可用的,配置参数如下:
yarn.nodemanager.resource.memory-mb
表示该节点上yarn可以使用的物理内存总量,默认是8192m,注意,如果你的节点内存资源不够8G,则需要减小这个值,yarn不会智能地探测节点物理内存总量。
yarn.nodemanager.vmem-pmem-ratio
任务使用1m物理内存最多 可用使用虚拟内存量,默认是2.1
yarn.nodemanager.pmem-check-enabled
是否启用一个线程检查每个任务正使用的物理内存量,如果任务超出了分配值,则直接将其kill,默认是true。
yarn.nodemanager.vmem-check-enabled
是否启用一个线程检查每个任务正使用的虚拟内存量,如果任务超出了分配值,则直接将其kill,默认是true。
yarn.scheduler.minimum-allocation-mb
单个任务可以使用最小物理内存量,默认1024m,如果一个任务申请物理内存量少于该值,则该对应值改为这个数。
yarn.scheduler.maximum-allocation-mb
单个任务可以申请的最多的内存量,默认8192m
Yarn cpu管理:
目前cpu被划分为虚拟cpu,这里的虚拟cpu是yarn自己引入的概念,初衷是考虑到不同节点cpu性能可能不同,每个cpu具有计算能力也是不一样的,比如,某个物理cpu计算能力可能是另外一个物理cpu的2倍,这时候,你可以通过为第一个物理cpu多配置几个虚拟cpu弥补这种差异。用户提交作业时,可以指定每个任务需要的虚拟cpu个数。在yarn中,cpu相关配置参数如下:
yarn.nodemanager.resource.cpu-vcores
表示该节点上yarn可使用的虚拟cpu个数,默认是8个,注意,目前推荐将该值设置为与物理cpu核数相同。如果你的节点cpu核数不够8个,则需要减小这个值,而yarn不会智能的探测节点物理cpu总数。
yarn.scheduler.minimum-allocation-vcores
单个任务可申请最小cpu个数,默认1,如果一个任务申请的cpu个数少于该数,则该对应值被修改为这个数
yarn.scheduler.maximum-allocation-vcores
单个任务可以申请最多虚拟cpu个数,默认是32