Hadoop1.0
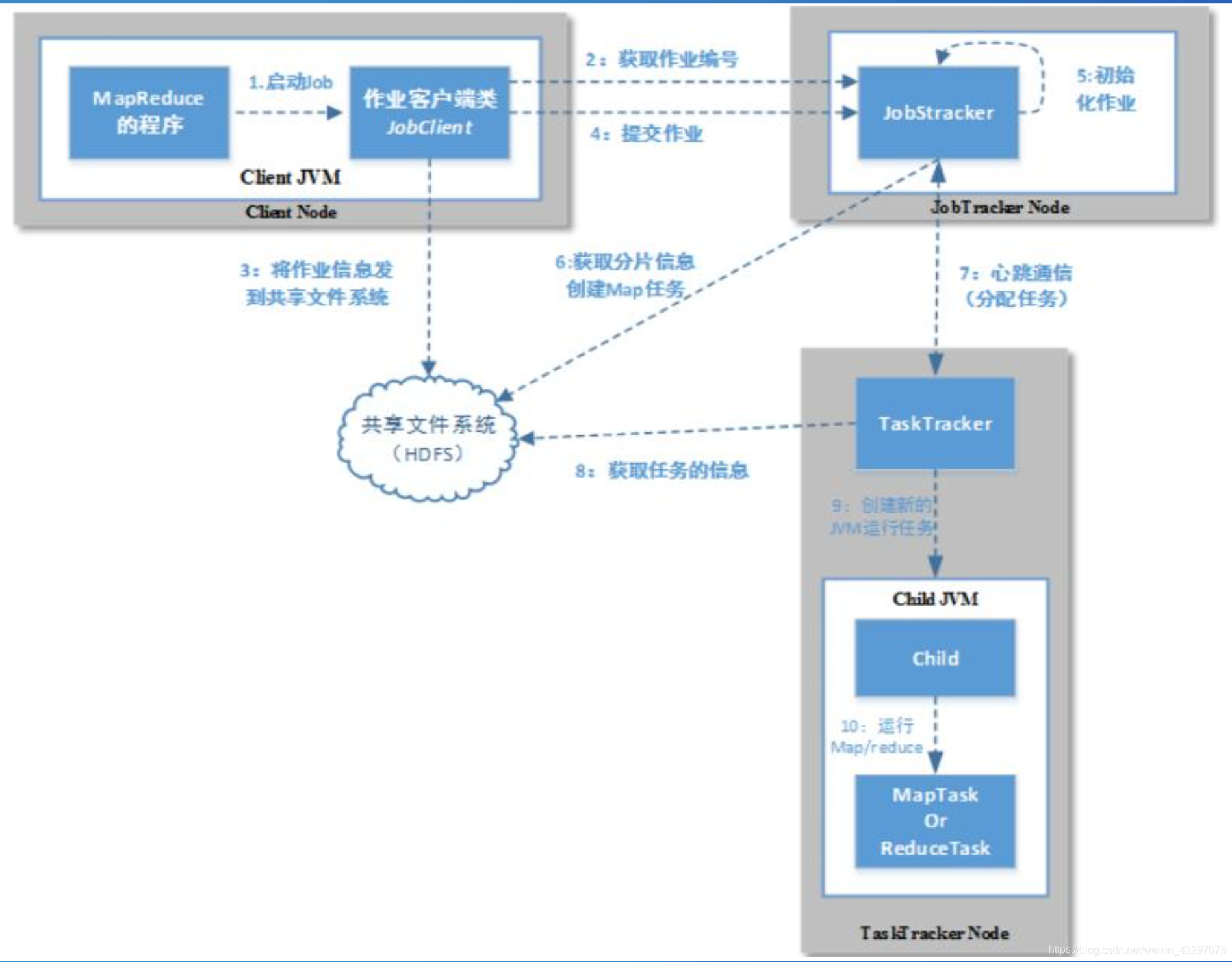
- 创建job,获取jobID。
- 检查作业的输出说明并计算作业的输入分片,然后将运行作业所需要的资源都复制
到以作业ID命名的目录下。
- 提交作业,告知jobtracker作业准备执行。(submitJob()方法)
- 初始化作业。创建一个表示正在运行作业的对象,用来封装任务和记录信息。
- 获取客户端计算好的输入分片,然后为每 个分片创建一个map任务。在此步骤的时候 还会创建reduce任务、作业创建任务、作业 清理任务。
- taskTraker发送心跳给JobTraker。
- 从共享文件系统把作业的JAR文件复制到tasktracker所在的文件系统。
- tasktracker创建一个TaskRunner实例。
- 启动一个新的JVM来运行map/reduce任务。
缺点
- **扩展性差:**在 MRv1 中,JobTracker 同时兼备 了资源管理和作业控制两个功能,这成为系统的 一个最大瓶颈,严重制约了 Hadoop 集群扩展性。
- 可靠性差:MRv1采用了master/slave结构,其中 master存在单点故障问题,一旦它出现故障将导 致整个集群不可用。
- 资源利用率低:MRv1采用了基于槽位的资源分配 模型,槽位是一种粗粒度的资源划分单位,通常 一个任务不会用完槽位对应的资源,其他任务也 无法使用这些空闲资源。此外,Hadoop将槽位分 为Map Slot和Reduce Slot两种,且不允许它们 之间共享, 常常会导致一种槽位资源紧张而另 外一种闲置(比如一个作业刚刚提交时,只会运 行Map Task,此时Reduce Slot闲置)。
- 无法支持多种计算框架:随着互联网高速发展, MapReduce这种基于磁盘的离线计算框架已经不 能满足应用要求,从而出现了一些新的计算框架 包括内存计算框架、流式计算框架和迭代式计算 框架等,而MRv1不能支持多种计算框架并存。
因此,有了Hadoop2.0,在HDFS之上添加资源管理器YARN

Yarn基本架构
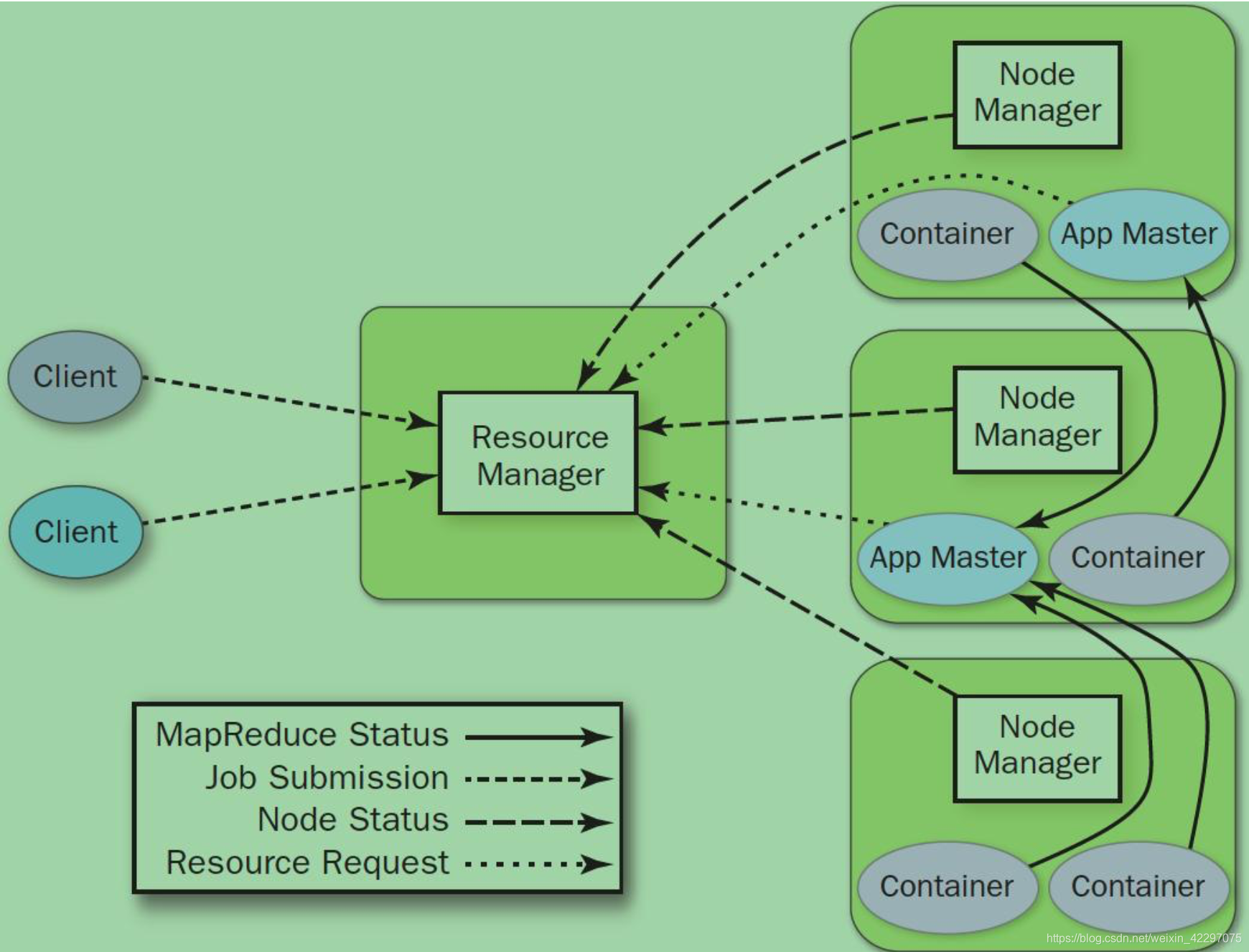
ResourceManager(RM)
全局的资源管理器,负责整 个系统资源的管理和分配。由调度器(Scheduler) 和应用程序管理器(Applications Manager ASM)组 成。调度器是纯调度器,只负责资源分配。资源分 配单位抽象为Container。ASM用于应用提交,启动 ApplicationMaster、监控AM运行状态并在失败时重 启它。
NodeManager(NM)
NM是每个节点上的资源和任务 管理器,一方面定时向RM汇报本节点的资源使用 情况和各个Container的运行状态,另一方面,接受 来自AM的Container启停请求。
ApplictionMaster(AM)
每个应用程序对应一个AM。 主要负责向RM请求资源、与NM通信来启停任务、 监控所有任务的运行状态,并在任务运行失败时重 新为任务申请资源并重启。
Container
是YARN的资源抽象,封装了某节点的多维度资源,例如内存、CPU、网络、磁盘等(目前只支持CPU和内存)。
Yarn的工作流程
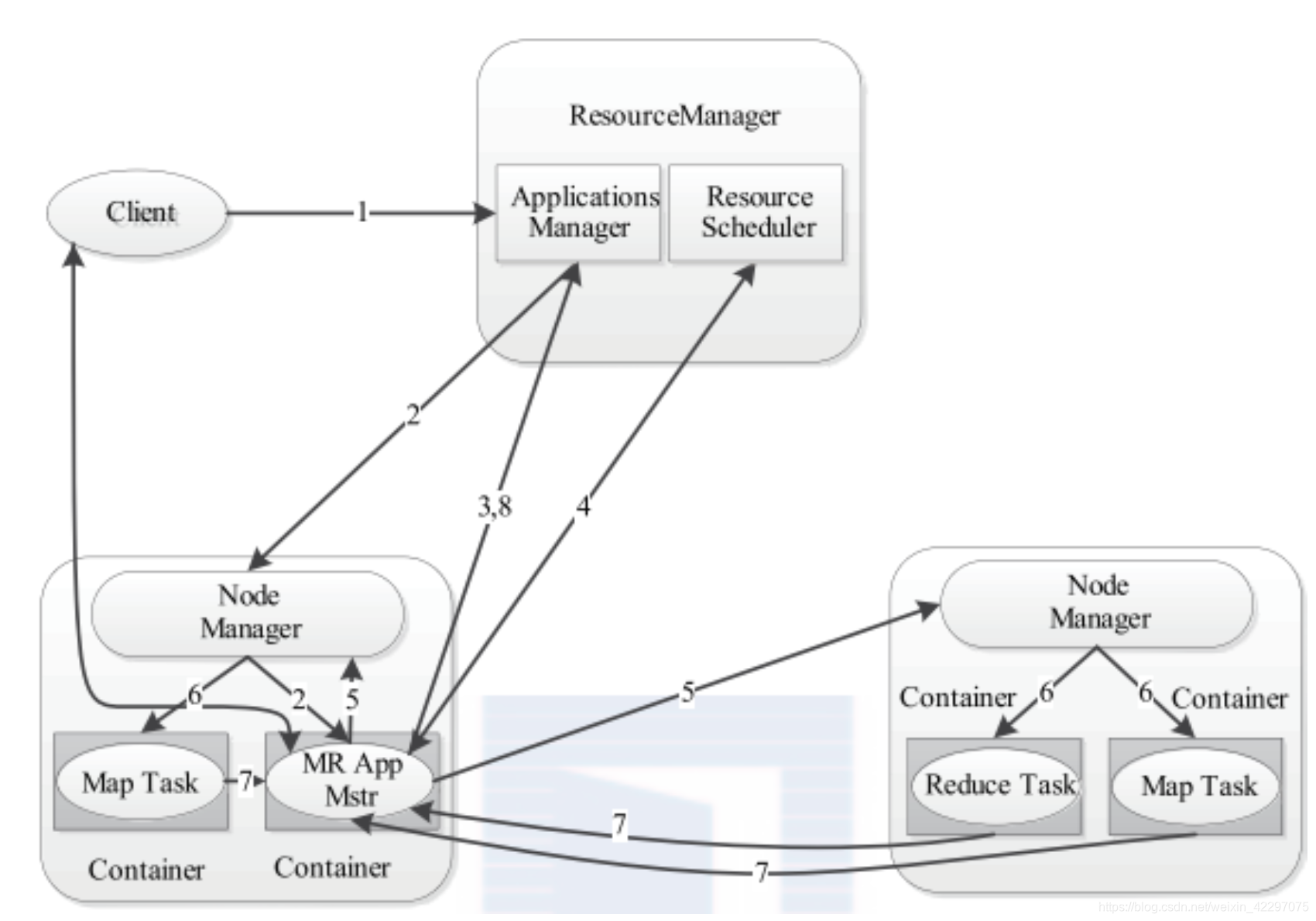
- 用户向YARN提交应用程序,其中包括 ApplicationMaster程序,启动AM的命令,用户程序。
- RM为该应用程序分配第一个Container,并与对应的NM通信,要求它在这个Container中启动应用程序对应的AM。
- AM启动后向RM注册,用户可以直接通过RM查看应 用程序的运行状态。重复4~7。
- AM采用轮询的方式通过RPC协议向RM申请和领取资源。
- 一旦AM申请到资源后,与对应的NM通信,要求它 启动任务。
- NM为任务设置好运行环境(包括环境变量、JAR包、 二进制程序等)后,将任务启动命令写入一个脚本中, 通过该脚本启动任务。
- 各个任务通过RPC协议向AM汇报自己的状态和进度, 以让AM随时掌握任务的运行状态,从而可以在任务失 败时重启任务。
- 任务运行完成后,AM向RM注销并关闭自己。
Yarn的容错
ResourceManager的单点故障
ResourceManager有备份节点,当主节点出现故障,将切换到从节点继续工作。
NodeManager
- 失败之后,ResourceManager将失败任务告诉对应的ApplicationMaster
- ApplicationMaster 决定如何去处理失败任务。
ApplicationMaster
- 失败后,由ResourceManager负责重启。
- ApplicationMaster需要处理内部任务的容错问题。
- ResourceManager会保存已经运行的task,重启后无需重新运行。
YARN的调度器-资源调度模型
双层资源调度模型
YARN采用了双层资源调度模型:
- 在第一层中,ResourceManager中的资源调度器将资源分配给各个 ApplicationMaster;
- 在第二层中,ApplicationMaster再进一步将资源分配给它内部的各个任务。
这里资源调度器主要关注的是第一层的调度问题,至于第二层的调度策略,完全由用户应用程序自己决定。
YARN采用的是pull-base通信模型,而不是push-base通信模型。资源调度器将资源分配给一个应用程 序后,它不会立刻push给对应的ApplicationMaster,而是暂时放到一个缓冲区中,等待ApplicationMaster 通过周期性的心跳主动来取。
YARN的调度器-资源保证机制
增量资源分配
当应用程序申请的资源暂时无法保证时,是优先为应用程序预留一个节点上的资源直到累计释放的空闲资 源满足应用程序的需求。这种资源分配方式,预留资源会造成资源的浪费,降低集群资源利用率。
一次性资源分配
当应用程序申请的资源暂时无法保证时,会放弃当前资源,直到出现一个节点剩余资源一次性满足应用程序需求。这种资源分配方式会出现饿死现象。即应用程序可能永远也等不到满足资源需求的节点出现。
YARN采用增量资源分配机制,尽管这种机制会造成浪费,但不会造成饿死现象。(假设应用程序不会永久占用某个资源,它会在一定时间内释放占用的资源)。
YARN的调度器-资源抢占模型
在资源调度器中,每个队列可设置一个最小资源量和最大资源量,其中,最小资源量是资源紧缺情况 下每个队列需保证的资源量,而最大资源量则是极端情况下队列也不能超过的资源使用量。
资源抢占:最小资源并不是硬资源保证,当一个队列资源负载较轻时,会将空闲资源分配给需要的队列,当负载较轻队列需要资源时,往往资源还在使用,在等待一段时间后将资源进行抢占。
YARN的调度器-Capacity Shedule
容量保证
每个队列可以设定最低资源保证和最高资源使用上限,而提交到该队列的任务则共享该队列的资源。
灵活性
如果一个队列资源有剩余,而其他队列资源紧张,可以先借用资源给其他队列。而一旦该队列有应用程序 提交,则其他队列释放资源后会归还给该队列。
多种租赁
支持多用户共享集群和多应用程序同时运行。管理员可以为之增加多种约束(某队列最大运行的任务数 等)。
安全保证
每个队列都有严格的ACL列表规定它的访问用户,每个用户可以指定哪些用户可以查看自己应用程序的状 态或者控制应用程序(例如杀死应用程序)。管理员可以指定队列管理员和系统管理员。
动态配置更新
管理员可以根据需要动态修改配置参数。
子对列
- 队列可以嵌套,每个队列可以有子队列。
- 用户只能讲应用程序提交到最底层队列,即叶子队列。
最少最大容量
- 每个队列配置最小和最大容量。
- 调度器总会选择当前资源使用率最低的队列,并为之分配资源。例如同级的队列A1,A2。它们最小容量均为30。而A1使用了12,A2使用了10,则调度器会优先将资源分给A2。
- 最小容量不是“总会保证最低容量”。
- 最小容量>=0,且不能大于最大容量。
- 最大容量限制了队列使用容量的极限值。
叶子节点内部使用多种策略
- FIFO,user limit ,application limit ,etc.
