相信很多喜欢看足球比赛的朋友都有过买足彩的经历,而且很多老彩民都会有自成一套的分析方法,如盘口分析,球员首发分析,大小球分析等等。(但是好像都不太凑效。。。)
那么接下我将会采集网易彩票网站里的数据,(其中包括欧洲五大联赛英超,意甲,西甲,德甲,法甲2010—2018年)
http://saishi.caipiao.163.com/
尝试从另一个角度看看球赛的赛果。
需要抓取的字段分别有如下7个:
比赛日期时间 day
主队名称 home_team
比分 score
客队名称 visiting_team
主队胜欧赔赔率 win
平欧赔赔率 draw
主队负欧赔赔率 lose
如下图红色方框中所示:

- 第一步,观察与分析,整个网站,右键查看源代码,看开发者工具,发现从主页面到显示详细数据的页面都是静态加载,因此决定用lxml来挖掘数据。五大联赛的首页分别为:
英超:http://saishi.caipiao.163.com/8.html
意甲:http://saishi.caipiao.163.com/13.html
西甲:http://saishi.caipiao.163.com/7.html
德甲:http://saishi.caipiao.163.com/9.html
法甲:http://saishi.caipiao.163.com/16.html - 先抓取一页的数据,代码如下(文件名为soccer_v1.py):
import requests
import uagent #一个我自己写的获取随机User-agent的函数
from lxml import etree
def get_page(url):
headers = {'User-Agent': uagent.get_ua()}
response = requests.get(url = url, headers = headers)
page = etree.HTML(response.text)
return page
#抓取日期时间字段
def p_day(page):
item = page.xpath('//table[@id="scoreLive"]/tr/td[1]/text()')
return item
#抓取主队名称字段
def p_home_team(page):
item = page.xpath('//td[@class="texRight"]/a/@title')
return item
#抓取比分字段
def p_score(page):
item = page.xpath('//td[@id="bfSam"]/text()')
return item
#抓取客队名称字段
def p_visiting_team(page):
item = page.xpath('//td[@class="texLeft"]/a/@title')
return item
#抓取主队胜欧赔赔率字段
def p_win(page):
item = page.xpath('//table[@id="scoreLive"]/tr/td[last()-3]/span/text()')
return item
#抓取平欧赔赔率字段
def p_draw(page):
item = page.xpath('//table[@id="scoreLive"]/tr/td[last()-2]/span/text()')
return item
#抓取主队负欧赔赔率字段
def p_lose(page):
item = page.xpath('//table[@id="scoreLive"]/tr/td[last()-1]/span/text()')
return item
def parse(page):
a = p_day(page)
b = p_home_team(page)
c = p_score(page)
d = p_visiting_team(page)
e = p_win(page)
f = p_draw(page)
g = p_lose(page)
for day, home_team, score, visiting_team, win, draw, lose in zip(a, b, c, d, e, f, g):
print((day, home_team, score, visiting_team, win, draw, lose))
if __name__ == '__main__':
url = 'http://saishi.caipiao.163.com/8.html'
page = get_page(url)
parse(page)
一个函数对应一个字段,如果以后有需要,可以方便添加或者减少字段。抓取效果如下图所示:
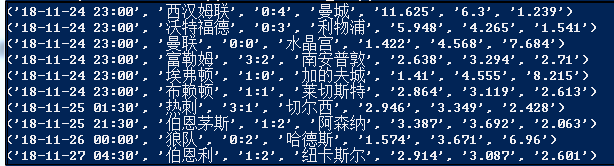
3.第三步,接下来抓取一个赛季的38轮比赛,一般这种静态加载的网站,相关内容的链接都能在HTML源代码中找到,如下图:

因此接下来添加一个获取链接的函数p_link()(文件名为soccer_v2.py):
#获取38轮比赛的链接
def p_link(page):
item = page.xpath('//div[contains(@class, "turnTime")]/dl/dd/a/@href')
return ['http://saishi.caipiao.163.com' + i for i in item]
- 再然后就是想办法把2010年到现在的数据全部挖下来,首先看一下url的变化。
2010/2011赛季 http://saishi.caipiao.163.com/8/5100.html
2011/2012赛季 http://saishi.caipiao.163.com/8/5983.html
2012/2013赛季 http://saishi.caipiao.163.com/8/7185.html
2013/2014赛季 http://saishi.caipiao.163.com/8/9641.html
这几个url看起来没什么规律,但是,同样的,这些5100,5983的数字,一般可以在网页的源代码中找到,果然,看下面的图:

那么接下来就好办了,再添加一个获取年份链接的函数就可以了。然后for循环一走就完事了。同理,5大联赛都能这么干,最后再增加一个save()函数,保存数据到csv文件中,下面直接贴完整代码(文件名为soccer_v3.py):
import requests
import uagent #一个我自己写的获取随机User-agent的函数
from lxml import etree
import csv
class soccer(object):
def __init__(self):
self.leagues = [
'http://saishi.caipiao.163.com/8/0000.html',#英超
'http://saishi.caipiao.163.com/13.html', #意甲
'http://saishi.caipiao.163.com/7.html', #西甲
'http://saishi.caipiao.163.com/9.html', #德甲
'http://saishi.caipiao.163.com/16.html', #法甲
]
def get_page(self, url):
headers = {'User-Agent': uagent.get_ua()}
response = requests.get(url = url, headers = headers)
page = etree.HTML(response.text)
return page
#抓取日期时间字段
def p_day(self, page):
item = page.xpath('//table[@id="scoreLive"]/tr/td[1]/text()')
return item
#抓取主队名称字段
def p_home_team(self, page):
item = page.xpath('//td[@class="texRight"]/a/@title')
return item
#抓取比分字段
def p_score(self, page):
item = page.xpath('//td[@id="bfSam"]/text()')
item = ["'" + i for i in item] #这里修改保存比分的形式,是因为在excel中显示类似1:0会出现问题
return item
#抓取客队名称字段
def p_visiting_team(self, page):
item = page.xpath('//td[@class="texLeft"]/a/@title')
return item
#抓取主队胜欧赔赔率字段
def p_win(self, page):
item = page.xpath('//table[@id="scoreLive"]/tr/td[last()-3]/span/text()')
return item
#抓取平欧赔赔率字段
def p_draw(self, page):
item = page.xpath('//table[@id="scoreLive"]/tr/td[last()-2]/span/text()')
return item
#抓取主队负欧赔赔率字段
def p_lose(self, page):
item = page.xpath('//table[@id="scoreLive"]/tr/td[last()-1]/span/text()')
return item
#获取38轮比赛的链接
def p_link(self, page):
item = page.xpath('//div[contains(@class, "turnTime")]/dl/dd/a/@href')
return ['http://saishi.caipiao.163.com' + i for i in item]
#抓取赛季url参数的字段
def p_option(self, page):
item = page.xpath('//div[contains(@class, "selBox")]//span[@class="optionList"]/a/@href')
#因为只要2010/2011赛季往后的数据,所以需要切片(年份太久远的比赛没有赔率的数据)
return ['http://saishi.caipiao.163.com' + i for i in item[:9]]
def parse(self, page):
a = self.p_day(page)
b = self.p_home_team(page)
c = self.p_score(page)
d = self.p_visiting_team(page)
e = self.p_win(page)
f = self.p_draw(page)
g = self.p_lose(page)
for day, home_team, score, visiting_team, win, draw, lose in zip(a, b, c, d, e, f, g):
yield (day, home_team, score, visiting_team, win, draw, lose)
def save(self, data):
with open('soccer.csv', 'a', newline = '', encoding = 'GB18030') as c:
writer = csv.writer(c)
for i in data:
writer.writerow(i)
if __name__ == '__main__':
spider = soccer()
urls = [] #这个空列表将会放入5大联赛2010年至今的url
for i in spider.leagues:
page = spider.get_page(i)
urls.append(spider.p_option(page))
links = [] #这个空列表将会放入5大联赛2010年至今包括每一轮比赛的url
for i in urls:
for k in i:
page = spider.get_page(k)
links.append(spider.p_link(page))
for i in links:
for k in i:
page = spider.get_page(k)
data = spider.parse(page)
spider.save(data)
print(k, '========>>>> ok')
这里封装成一个类,方便以后可以抓取其他更多的联赛,或者去抓取亚盘,大小球赔率的时候也可以通过继承来复用部分函数。还有就是通过yield关键字把parse()写出一个生成器函数,方便保存数据。
最后一共抓取了15270场比赛,抓取结果如下:

首先来看看2010年至今,主场作战获胜最多的10支球队分别是哪些:

都是一些家喻户晓的知名俱乐部了。这个排名看看就好。
下面来看一下在足彩里面非常受欢迎的一个东西:比分,买比分,也叫买波胆。
我首先对这15270场的比分进行一下统计,看看在5大联赛中,有没有什么比分是特别容易打出的。

可以看出,1:1和1:0是出现概率最高的比分。
在足彩里,还有一个很多人喜欢玩的,就是买‘大小球’,意思就是看看某一场比赛中,主客双方球队一共打进了几个球,是否大于或小于某一个数。接来下统计一下出现最多的进球数量是多少。

可以看出,双方一共打进2球的概率最大,但是如果买‘小球’,比如菠菜公司开出的盘口是2.5球,那么就需要把出现0球,1球和2球出现的概率加起来,而买‘大球’,就需要把出现大于2球的概率相加。
习惯看球赛的朋友应该都知道,有一个说法叫做‘主场优势’,究竟主场作战是不是真的有优势呢,所以,接下来看看,主队作战的胜率究竟是多少。


看来‘主场优势’确实存在,主队胜的概率比客队胜的概率整整高了17个百分点。
总结
这个网站的数据是静态加载,直接利用lxml中的xpath就能够定位到指定的标签,从而获取所需要的数据。保存数据用到了csv模块,然后数据分析使用了pandas,pandas其实就相当于excel一样,但是比excel要灵活得多。最后的数据可视化使用的matplotlib。