版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_40042143/article/details/85319390
paper的实验一个想法是对fp-tree进行改进,所以对spark里面的 fp-tree源码进行理解。记录一下。
资料:https://blog.csdn.net/LULIN60/article/details/52255242?utm_source=blogxgwz0
关于fp-tree的结点
/** Representing a node in an FP-Tree. */
class Node[T](val parent: Node[T]) extends Serializable {
var item: T = _//结点中包含的项(v)
var count: Long = 0L//对应的计数
/**
*children:表示孩子结点,用一个item->Node[item]的映射表示
*根据fp-tree的特点,一个结点的孩子结点中包含的item肯定是互不相同的;
*或者一个item在树的每一层最多只能出现一次,在树的每个分支也可能只出现一次
*/
val children: mutable.Map[T, Node[T]] = mutable.Map.empty
def isRoot: Boolean = parent == null//判断是否到达根结点
}结点链
/** Summary of an item in an FP-Tree.同一个项item对应的结点链 */
private class Summary[T] extends Serializable {
var count: Long = 0L//item在数据样本中(transactions)中出现的次数
val nodes: ListBuffer[Node[T]] = ListBuffer.empty//fp-tree中包含该Item的所有结点列表
}对于scala也是处于了解的阶段,在此做了一点笔记
ListBuffer:是scala里面的一种可变的容器,内部实现是链表。
顺便多了解了另一个容器:哈希表
HashTable用一个底层数组来存储元素,每个数据项在数组中的存储位置由这个数据项的Hash Code来决定。
解读fp-tree类
该类有两个成员变量:
root
summaries
/** Adds a transaction with count. */
def add(t: Iterable[T], count: Long = 1L): this.type = {
require(count > 0)
var curr = root//从根结点开始,将事务中的项依次添加到当前结点的孩子结点中
curr.count += count
/**
*将一个transaction 看作是树的一个分枝
*接下来就是将这个分枝添加到树中,对应成上包含有相同item的Node时,就只更新count
*否则,就要生成新的结点
*/
t.foreach { item =>
val summary = summaries.getOrElseUpdate(item, new Summary)//如果item在树中已经存在,获取其结点链,否则生成一个
summary.count += count
val child = curr.children.getOrElseUpdate(item, {//从当前结点的孩子结点中看item是否存在
val newNode = new Node(curr)//如果不存在,生成一个新的以curr为父节点的newNode
newNode.item = item
summary.nodes += newNode
newNode
})
child.count += count
curr = child//得到孩子结点之后,将孩子结点看作当前结点向下遍历
}//foreach过程执行结束
this
} /** Gets a subtree with the suffix.
*以事务中某项item为后缀,向上遍历fptree
*得到一颗以包含Item的Node为叶子结点的子树
*该方法是从item的父节点开始的,所以子树中不包含Item
*/
private def project(suffix: T): FPTree[T] = {
val tree = new FPTree[T]
if (summaries.contains(suffix)) {//判断结点链中是否包含该后缀项
val summary = summaries(suffix)//获取该suffix对应的结点链
summary.nodes.foreach { node =>
var t = List.empty[T]
var curr = node.parent//从父节点开始
while (!curr.isRoot) {//一直向上遍历直到根结点
t = curr.item :: t
curr = curr.parent
}
//t中是一条以item为结点的分枝
tree.add(t, node.count)
}
}
tree
}
project方法实列,图片来源:https://blog.csdn.net/LULIN60/article/details/52255242?utm_source=blogxgwz0
从l5向上递归遍历的
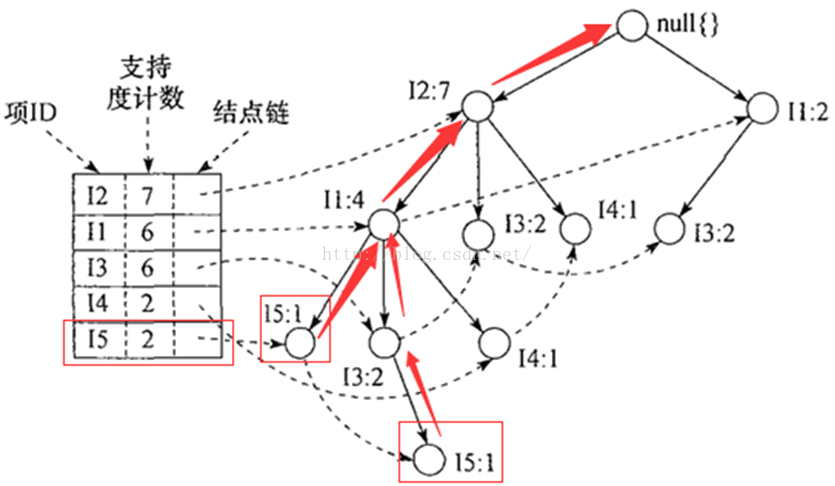
extract遍历fp-tree
/** Extracts all patterns with valid suffix and minimum count.
*分别以summaries一个item为后缀,递归输出所有频繁项
*/
def extract(
minCount: Long,
validateSuffix: T => Boolean = _ => true): Iterator[(List[T], Long)] = {
summaries.iterator.flatMap { case (item, summary) =>//每一项和它对应结点链
if (validateSuffix(item) && summary.count >= minCount) {
Iterator.single((item :: Nil, summary.count)) ++//单item为频繁一项集的一个
project(item).extract(minCount).map { case (t, c) =>//递归的抽取item所在分枝上所有大于minCount的项集
(item :: t, c)
}
} else {
Iterator.empty
}
}
}FP-Growth解读
程序入口:run
def run[Item: ClassTag](data: RDD[Array[Item]]): FPGrowthModel[Item] = {
if (data.getStorageLevel == StorageLevel.NONE) {
logWarning("Input data is not cached.")
}
val count = data.count()
val minCount = math.ceil(minSupport * count).toLong
val numParts = if (numPartitions > 0) numPartitions else data.partitions.length//获取分区数(PFP算法中的分组)
val partitioner = new HashPartitioner(numParts)
val freqItems = genFreqItems(data, minCount, partitioner)//生成频繁项
val freqItemsets = genFreqItemsets(data, minCount, freqItems, partitioner)//生成频繁项集
new FPGrowthModel(freqItemsets)
}
生成频繁项---此处对paper有***---项头表
private def genFreqItems[Item: ClassTag](
data: RDD[Array[Item]],
minCount: Long,
partitioner: Partitioner): Array[Item] = {
data.flatMap { t =>
val uniq = t.toSet
if (t.length != uniq.size) {//一条事务的项不能有重复,否则会报错
throw new SparkException(s"Items in a transaction must be unique but got ${t.toSeq}.")
}
t
}.map(v => (v, 1L))
.reduceByKey(partitioner, _ + _)//将每一个item根据hash分配到各个分区上,并求其频次
.filter(_._2 >= minCount)
.collect()
.sortBy(-_._2)//按按频次降序排列---*******
.map(_._1)
}生成条件事务
/**
* Generates conditional transactions.
*生成条件事务的时候,itemToRan将freqItemset用对应的下标来映射。
*所以每条事务经过筛选并按freqItemset中的频次重排之后,以item对应的下标来输出。
* @param transaction a transaction
* @param itemToRank map from item to their rank
* @param partitioner partitioner used to distribute transactions
* @return a map of (target partition, conditional transaction)
*/
private def genCondTransactions[Item: ClassTag](
transaction: Array[Item],
itemToRank: Map[Item, Int],
partitioner: Partitioner): mutable.Map[Int, Array[Int]] = {
val output = mutable.Map.empty[Int, Array[Int]]
// Filter the basket by frequent items pattern and sort their ranks.
val filtered = transaction.flatMap(itemToRank.get)
ju.Arrays.sort(filtered)//按照itemToRank重新排序
val n = filtered.length
var i = n - 1
while (i >= 0) {
val item = filtered(i)
val part = partitioner.getPartition(item)
if (!output.contains(part)) {
output(part) = filtered.slice(0, i + 1)
}
i -= 1
}
output
}生成频繁项集
/**
* Generate frequent itemsets by building FP-Trees, the extraction is done on each partition.
* @param data transactions
* @param minCount minimum count for frequent itemsets
* @param freqItems frequent items
* @param partitioner partitioner used to distribute transactions
* @return an RDD of (frequent itemset, count)
*/
private def genFreqItemsets[Item: ClassTag](
data: RDD[Array[Item]],
minCount: Long,
freqItems: Array[Item],
partitioner: Partitioner): RDD[FreqItemset[Item]] = {
val itemToRank = freqItems.zipWithIndex.toMap
data.flatMap { transaction =>
genCondTransactions(transaction, itemToRank, partitioner)//条件事务
//aggregateByKey的作用是对每个分区及其包含的所有事务,构建一颗fp-tree
}.aggregateByKey(new FPTree[Int], partitioner.numPartitions)(
(tree, transaction) => tree.add(transaction, 1L),//一条事务作为只有一条分枝分树
(tree1, tree2) => tree1.merge(tree2))//所有单分枝树进行合并成为一棵树(各个分区分别进行这两个操作)
.flatMap { case (part, tree) =>
//分别从各个分区对应树进行频繁模式抽取
tree.extract(minCount, x => partitioner.getPartition(x) == part)
}.map { case (ranks, count) =>
new FreqItemset(ranks.map(i => freqItems(i)).toArray, count)//将下标转换成其对应的Item
}
}