所谓容错就是一个系统的部分出现错误的情况还能够持续地提供服务,不会因为一些错误而导致系统性能严重下降或出现系统瘫痪。在一个集群中出现机器故障、网络问题等常态,尤其集群达到较大规模后,很可能较频繁的出现机器故障等不能进行提供服务,因此分布性集群需要进行容错设计。
1. Executor容错
Spark支持多种运行模式,这些运行模型中的集群管理器会为任务分配运行资源,在运行资源中启动Executor,由Executor执行任务的运行,最终把任务运行状态发送给Driver。

(1)首先看Exeucutord的启动过程:在集群中由Master给应用程序分配运行资源后,然后再Worker中启动ExecutorRunner,而ExecutorRunner根据当前的运行模式启动CoarseGrainedExecutorBackend进程,当该进程会向Driver发送注册Executor信息,如果注册成功,则CoarseGrainedExecutorBackend在其内部启动Executor。Executor由ExecutorRunner进行管理,当Executor出现异常的时候(如所运行容器CoarseGrainedExecutorBackend进程异常退出等)由ExecutorRunner捕获当前异常并且发送ExecutorStateChanged消息给Worker进程。
(2)Worker进程接受到ExecutorStateChanged消息时,在Worker的handleExecutorStateChanged方法中,根据Executor状态消息更新,同时把Executor状态发送给Master。
(3)Master接收到Executor状态变化消息后,如果发现Executor出现异常退出,则调用Master.schedule方法,尝试获取可用的Worker节点并启动Executor,而这个Worker很可能不是失败之前运行的Executor的Worker节点。该尝试系统会进行10次,如果超过10次,则标记该应用运行失败并移除集群中该应用。
2. Worker异常
Spark独立运行模式采用的是Master/Slave的结构,其中Slave是由Worker来担任的,在运行的时候会发送心跳信息给Master,让Master知道Worker的实时状态,另一方面也会检测注册的Worker是否超时,因为在集群运行过程中,可能由于机器宕机或者进程被杀死等原因造成Worker进程异常退出
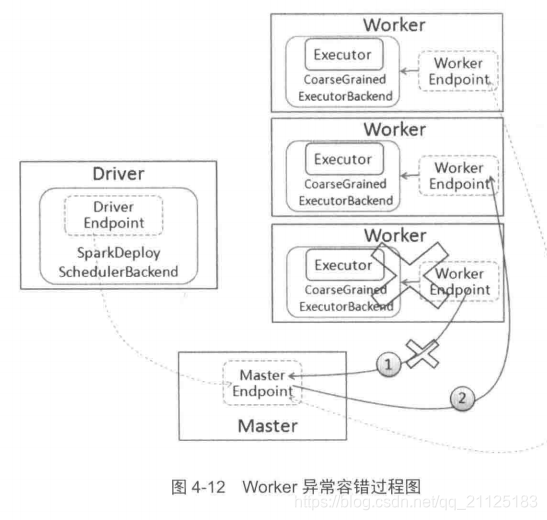
当Worker出现超时时,Master调用timeOutDeadWorker方法进行处理,在处理时根据Worker运行的是Executor和Driver进行分别处理。
- 如果是Executor,Master先把该Worker上运行的Executor发送消息ExecutorUpdate给对应的Driver,告知Exeucotr已经丢失,同时把这些Executor从其应用程序中删除。
- 如果是Drvier,则判断是否要重新启动。如果需要,则调用Master.schedule方法进行调度,分配合适节点重启Driver。
3. Master异常
Master作为Spark独立运行模式的核心,如果Master出现异常,则整个集群的运行资源将无法进行管理,整个集群将处于“群龙无首”的状态。很幸运的是,Spark在设计的时候考虑这个情况,在集群运行的时候,Master将启动一个或者多个StandBy Mster,当Master异常的时候,StandBy Mster将根据一定的规则确定其中一个为Master接管。
