解析页面之xpath
xpath: XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言,是一种小型的查询语言。
xpath支持的解析:
- XML格式
- html格式
- 通过元素,和属性进行导航
解析页面模块: 正则表达式、xpath、Beautifulsoup
1.模块比较:
-
正则表达式是进行内容匹配,将符合要求的内容全部获取;
-
xpath( )能将字符串转化为标签,它会检测字符串内容是否为标签,但是不能检
测出内容是否为真的标签; -
Beautifulsoup是Python的一个第三方库,它的作用和 xpath 作用一样,都是用来解析html数据的。相比之下,xpath的速度会快一点,因为xpath底层是用c语言来实现的。
2.三者语法不同:
- 正则表达式使用元字符,将所有获得内容与匹配条件进行匹配;
- xpath和bs4将获取的解析后的源码进行按条件筛选,筛选出想要的标签即根据标签属性来找到指定的标签,之后对标签进行对应内容获取。
xpath语法
选取节点 XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
下面列出了最有用的路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性。 |
xpath使用方法:
import lxml.etree as etree
html = """
<!DOCTYPE html>
<html>
<head lang="en">
<title>xpath??</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>
</head>
<body>
<div id="content">
<ul id="ul">
<li>NO.1</li>
<li>NO.2</li>
<li>NO.3</li>
</ul>
<ul id="ul2">
<li>one</li>
<li>two</li>
</ul>
</div>
<div id="url">
<a href="http:www.58.com" title="58">58</a>
<a href="http:www.csdn.net" title="CSDN">CSDN</a>
</div>
</body>
</html>
"""
# 1). 将html内容转化成xpath可以解析/匹配的格式
selector = etree.HTML(html)
# 2). 获取需要的信息
# //: 对全文进行扫描
# //div[@id="content"]:在全文查找id="content"的div标签
str = selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()')
print(str)
运行结果为:
[‘NO.1’, ‘NO.2’, ‘NO.3’]
需求: 获取文件中div的属性id为”url“里面的所有a标签的href属性
str = selector.xpath('//div[@id="url"]/a/@href')
print(str)
运行结果为:
[‘http:www.58.com’, ‘http:www.csdn.net’]
案例_爬取mooc课程:
爬取mooc网的课程信息,包括:课程链接,课程图片链接,课程名称,学习人数,课程描述
import csv
import json
import requests
import lxml.etree as etree
def get_content(url):
"""获取页面内容"""
try:
user_agent = 'Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0'
response = requests.get(url, headers={'User-Agent': user_agent})
response.raise_for_status() # 如果返回的状态码不是200,则抛出异常
response.encoding = response.apparent_encoding # 根据响应信息判断网页的编码格式,便于response.text知道如何解码
except Exception as e:
print('爬取错误')
else:
print('爬取成功')
return response.text
def parser_content(html):
"""解析页面内容,获取需要的信息:课程链接,课程图片链接,课程名称,学习人数,课程描述"""
# 1. 将html内容转化为xpath可以解析/匹配的格式
selector = etree.HTML(html)
# 2.获取每个课程的信息:<div class="course-card-container">
courseDetails = selector.xpath('//div[@class="course-card-container"]')
courseInfos = []
for courseDetail in courseDetails:
# 课程名称:<h3 class="course-card-name">初识HTML+CSS</h3>
courseName = courseDetail.xpath('.//h3[@class="course-card-name"]/text()')[0]
# 学习人数:<span>入门</span><span><i class="icon-set_sns"></i>1000169</span>
studyNum = courseDetail.xpath('.//span/text()')[1]
# 课程描述:<p class="course-card-desc">HTML+CSS基础教程8小时带领大家步步深入学习标签用法和意义</p>
courseDesc = courseDetail.xpath('.//p[@class="course-card-desc"]/text()')[0]
# 课程链接:先获取 /learn/9 ----> https://www.imooc.com/learn/9
# <a target="_blank" href="/learn/9" class="course-card">
courseUrl = 'https://www.imooc.com' + courseDetail.xpath('.//a/@href')[0]
# 课程图片链接:http://img.mukewang.com/529dc3380001379906000338-240-135.jpg
"""
<img class="course-banner lazy" data-original="//img.mukewang.com/529dc3380001379906000338-240-135.jpg"
src="//img.mukewang.com/529dc3380001379906000338-240-135.jpg" style="display: inline;">
"""
courseImgUrl = 'http:' + courseDetail.xpath('.//img/@src')[0]
courseInfos.append((courseName,studyNum,courseDesc,courseUrl,courseImgUrl))
return courseInfos
def save_csv(courseInfos):
with open('doc/mooc.csv','w') as f:
writer = csv.writer(f)
writer.writerows(courseInfos)
print('csv文件保存成功......')
def save_json(courseInfos):
with open('doc/mooc.json','w') as f:
for item in courseInfos:
item = {
'courseName':item[0],
'studyNum':item[1],
'courseDesc':item[2],
'courseUrl':item[3],
'courseImgUrl':item[4],
}
# ensure_ascii=False:如果有中文,则设置为False,表示使用Unicode编码,中文不会乱码
# indent=4:缩进为4个空格,便于阅读
jsonitem = json.dumps(item,ensure_ascii=False,indent=4)
f.write(jsonitem + '\n')
print('json文件保存成功......')
def moocSpider():
url = 'https://www.imooc.com/course/list'
html = get_content(url)
courseInfos = parser_content(html) # 列表,保存第一页的页面信息
while True:
# 获取是否拥有下一页
selector = etree.HTML(html)
# 什么时候爬取结束? ----> 没有下一页的时候
# 有下一页:<a href="/course/list?page=2">下一页</a>
# 没有下一页:<span class="disabled_page">下一页</span>
# a[contains(text(),"下一页")] ----> 获取包含“下一页”文本的a标签
nextPage = selector.xpath('//a[contains(text(),"下一页")]/@href')
if nextPage:
# url规则:http://www.imooc.com/course/list?page=2
url = 'https://www.imooc.com' + nextPage[0]
html = get_content(url)
otherCourseInfos = parser_content(html) # 将其他页获去的页面信息追加到
courseInfos += otherCourseInfos
else:
print('全部爬取结束......')
break
save_csv(courseInfos)
save_json(courseInfos)
if __name__ == '__main__':
moocSpider()
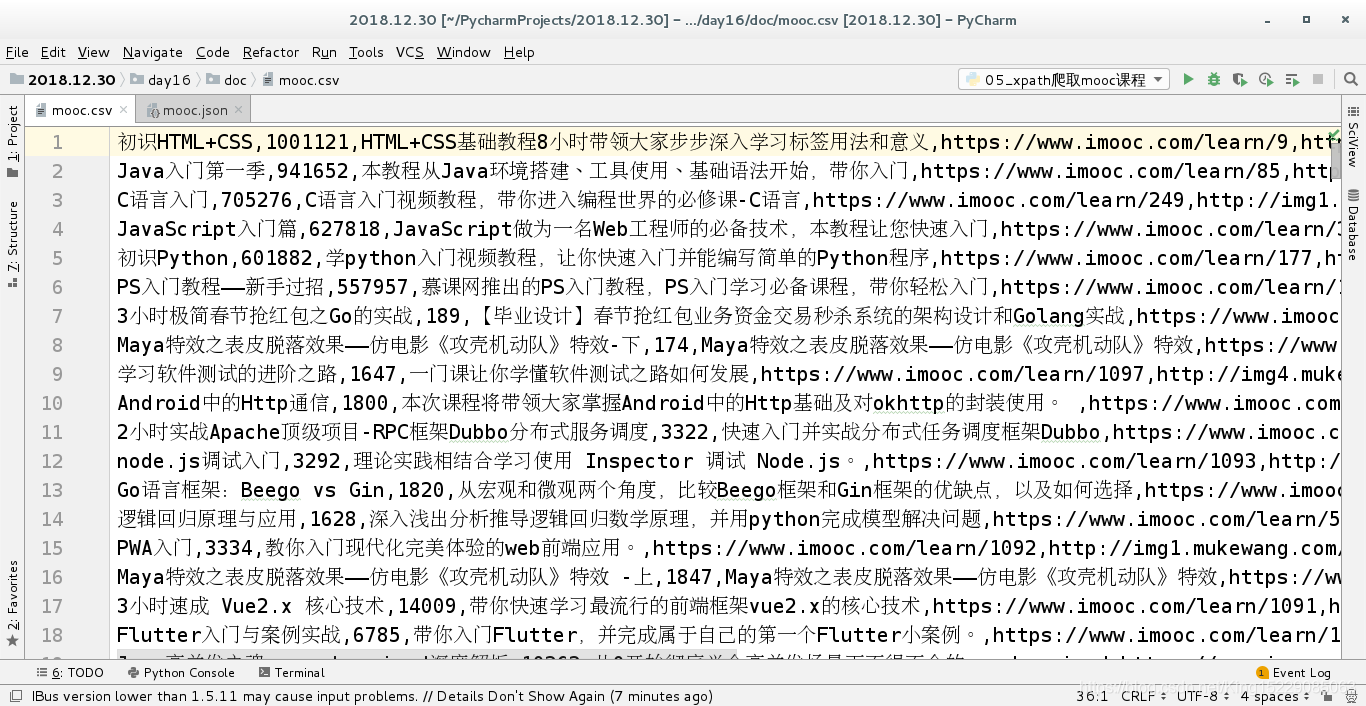
将爬取的信息保存到csv文件:
将爬取的信息保存到json文件:
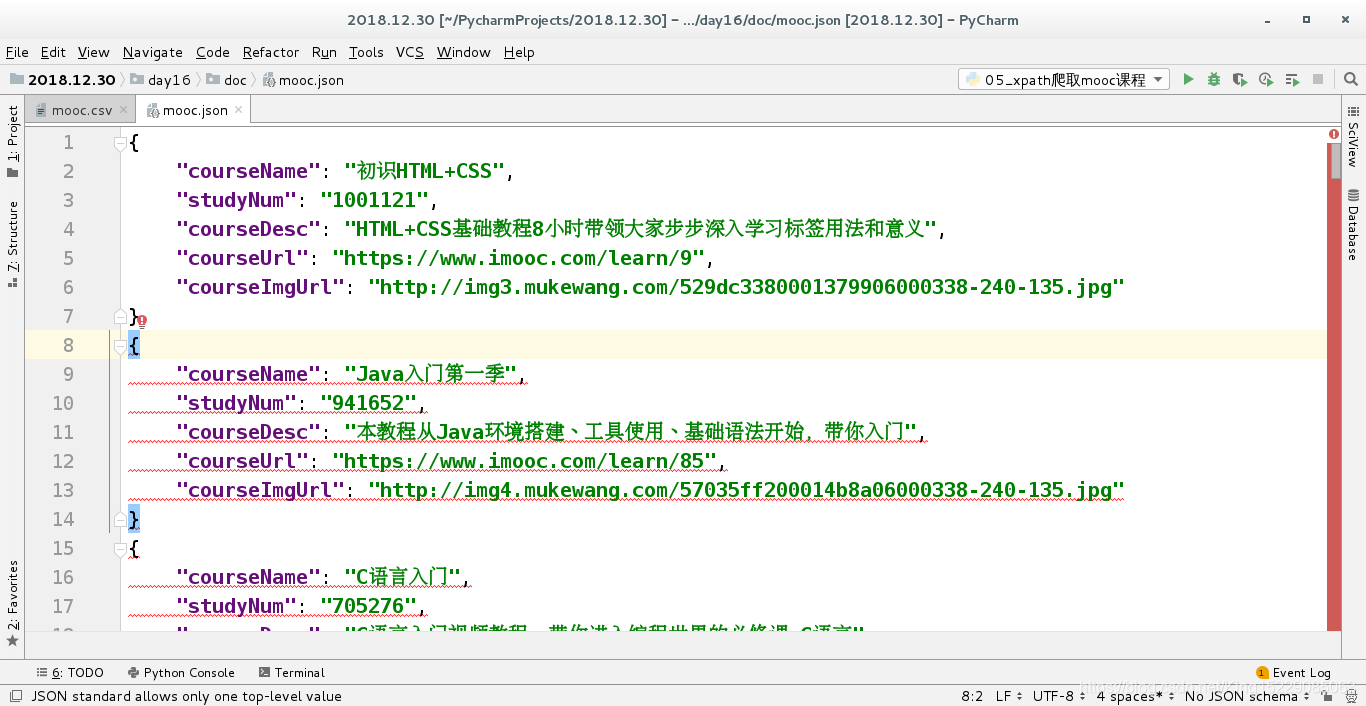
由于pycharm还没有.json格式,所以会有报错(不影响实验结果)。