线程与进程理解
1. 重要的概念?
- 程序: /bin/firefox是一个二进制程序, (eg:python, Java程序), 是一个真实存在的, 可以看到的实体;
进程: 执行程序的过程中产生的一系列内容,(计算机给进程分配了内存, cpu等…)
线程: 是执行进程
专业的总结:
- 进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,
是系统进行资源分配和调度的基本单位,是操作系统结构的基础。 - 线程,有时被称为轻量进程(Lightweight Process,LWP),是程序
执行流的最小单元。是被系统独立调度和分派的基本单位。
2. 线程状态
- 新建状态(New)
- 就绪状态(Runnable)
- 运行状态(Running)
- 阻塞状态(Blocked)
- 死亡状态(Dead)

创建线程
一个进程里面必然有一个主线程
操作线程的模块:
- thread
- threading
import _thread
import threading
import time
def job():
print("这是一个需要执行的任务。。。。。")
print("当前线程的个数:", threading.active_count() )
print("当前线程的信息:", threading.current_thread())
time.sleep(100)
if __name__ == '__main__':
job()

实现多线程的方法一
import threading
import time
import _thread
def job():
print("这是一个需要执行的任务。。。。。")
print("当前线程的个数:", threading.active_count() )
print("当前线程的信息:", threading.current_thread())
time.sleep(100)
if __name__ == '__main__':
# c创建多线程时, 需要制定该线程执行的任务
_thread.start_new_thread(job, ())
_thread.start_new_thread(job, ())
# job()
while True:
pass

实现多线程的方法二
import threading
import time
import _thread
def job():
print("这是一个需要执行的任务。。。。。")
print("当前线程的个数:", threading.active_count() )
time.sleep(1)
print("当前线程的信息:", threading.current_thread())
if __name__ == '__main__':
# c创建多线程时, 需要制定该线程执行的任务
t1 = threading.Thread(target=job )
t2 = threading.Thread(target=job)
t1.start()
t2.start()
print(threading.active_count())
# 出现的问题: 主线程执行结束, 但是子线程还在运行。
# 等待所有的子线程执行结束之后, 再执行主线程
t1.join()
t2.join()
print("程序执行结束.....")

实现多线程的方法三
import threading
import time
import _thread
class MyThread(threading.Thread):
def __init__(self, jobName):
super(MyThread, self).__init__()
self.jobName = jobName
# 重写run方法, 实现多线程, 因为start方法执行时, 调用的是run方法;
# run方法里面编写的内容就是你要执行的任务;
def run(self):
print("这是一个需要执行的任务%s。。。。。" %(self.jobName))
print("当前线程的个数:", threading.active_count() )
time.sleep(1)
print("当前线程的信息:", threading.current_thread())
if __name__ == '__main__':
t1 = MyThread("name1")
t2 = MyThread("name2")
t1.start()
t2.start()
t1.join()
t2.join()
print("程序执行结束.....")

未使用多线程案例
from urllib.request import urlopen
# 定义计时器
def timeit(f):
def wrapper(*args, **kwargs):
start_time = time.time()
res = f(*args, **kwargs)
end_time = time.time()
print("%s函数运行时间:%.2f" % (f.__name__, end_time - start_time))
return res
return wrapper
# 定义获取网页内容函数
def get_addr(ip):
url = "http://ip-api.com/json/%s" % (ip)
urlObj = urlopen(url)
# 服务端返回的页面信息, 此处为字符串类型
pageContent = urlObj.read().decode('utf-8')
# 2. 处理Json数据
import json
# 解码: 将json数据格式解码为python可以识别的对象;
dict_data = json.loads(pageContent)
print("""
%s
所在城市: %s
所在国家: %s
""" % (ip, dict_data['city'], dict_data['country']))
# 计算程序运行时间
@timeit
def main():
ips = ['12.13.14.%s' % (i + 1) for i in range(10)]
for ip in ips:
get_addr(ip)
if __name__ == '__main__':
main()

使用多线程案例
import threading
import time
from urllib.request import urlopen
def timeit(f):
def wrapper(*args, **kwargs):
start_time = time.time()
res = f(*args, **kwargs)
end_time = time.time()
print("%s函数运行时间:%.2f" % (f.__name__, end_time - start_time))
return res
return wrapper
def get_addr(ip):
url = "http://ip-api.com/json/%s" % (ip)
urlObj = urlopen(url)
# 服务端返回的页面信息, 此处为字符串类型
pageContent = urlObj.read().decode('utf-8')
# 2. 处理Json数据
import json
# 解码: 将json数据格式解码为python可以识别的对象;
dict_data = json.loads(pageContent)
print("""
%s
所在城市: %s
所在国家: %s
""" % (ip, dict_data['city'], dict_data['country']))
@timeit
def main():
ips = ['12.13.14.%s' % (i + 1) for i in range(10)]
threads = []
for ip in ips:
t = threading.Thread(target=get_addr, args=(ip, ))
threads.append(t)
t.start()
[thread.join() for thread in threads]
if __name__ == '__main__':
main()

import threading
import time
from urllib.request import urlopen
def timeit(f):
def wrapper(*args, **kwargs):
start_time = time.time()
res = f(*args, **kwargs)
end_time = time.time()
print("%s函数运行时间:%.2f" % (f.__name__, end_time - start_time))
return res
return wrapper
class MyThread(threading.Thread):
def __init__(self, ip):
super(MyThread, self).__init__()
self.ip = ip
def run(self):
url = "http://ip-api.com/json/%s" % (self.ip)
urlObj = urlopen(url)
# 服务端返回的页面信息, 此处为字符串类型
pageContent = urlObj.read().decode('utf-8')
# 2. 处理Json数据
import json
# 解码: 将json数据格式解码为python可以识别的对象;
dict_data = json.loads(pageContent)
print("""
%s
所在城市: %s
所在国家: %s
""" % (self.ip, dict_data['city'], dict_data['country']))
@timeit
def main():
ips = ['12.13.14.%s' % (i + 1) for i in range(10)]
threads = []
for ip in ips:
t = MyThread(ip)
threads.append(t)
t.start()
[thread.join() for thread in threads]
if __name__ == '__main__':
main()

GIL(全局解释器锁)
python使用多线程, 一定运行速度快么? 为什么?
- GIL(global interpreter lock)
- python解释器中任意时刻都只有一个线程在执行;
- GIL执行过程:
- 1). 设置一个GIL;
- 2). 切换线程去准备执行任务(Runnale就绪状态);
- 3). 运行;
- 4). 可能出现的状态:
- 线程任务执行结束;
- time.sleep()
- 需要获取其他的信息才能继续执行(eg: 读取文件, 需要从网络下载html网页) - 5). 将线程设置为睡眠状态;
- 6). 解GIL的锁;
import threading
import time
def timeit(func):
def wrapper(*args,**kwargs):
start_time=time.time()
res=func(*args,**kwargs)
end_time=time.time()
print('%s 运行时间:%.8f' %(func.__name__,end_time-start_time))
return res
return wrapper
def job(li):
return sum(li)
@timeit
def use_thread():
li = range(1, 10001)
# create 5 threads
threads = []
for i in range(5):
t = threading.Thread(target=job, args=(li, ))
t.start()
threads.append(t)
[thread.join() for thread in threads]
@timeit
def use_no_thread():
li = range(1, 10001)
for i in range(5):
job(li)
if __name__ == "__main__":
use_thread()
use_no_thread()
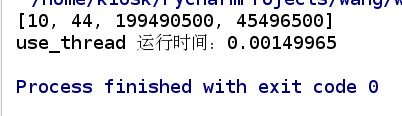
## 从运行结果来看,没有使用多线程的程序运行时间更短

队列与线程
1). 理论上多线程执行任务是不能获取返回结果的, 因此需要一个容器来存储产生的数据;
2). 容器该如何选择? list(栈, 队列), tuple(元组是不可变的, 不可使用),set(集合默认会去重, 所以不选择), dict
选择队列类型存储(FIFO===first input first output)
扫描二维码关注公众号,回复:
5290329 查看本文章

import threading
from mytimeit import timeit
from queue import Queue
def job(li, queue):
queue.put(sum(li)) # 将任务的执行结果存储到队列中;
@timeit
def use_thread():
# 实例化一个队列, 用来存储每个线程执行的结果
q = Queue()
# q.get() -- 出队
# q.put(value) -- 入队
lis = [range(5), range(2,10), range(1000, 20000), range(3000, 10000)]
# 创建5个线程
threads = []
for li in lis:
t = threading.Thread(target=job, args=(li, q))
t.start()
threads.append(t)
[thread.join() for thread in threads]
# 从队列中拿出所有线程执行的结果;
results = [q.get() for li in lis]
print(results)
if __name__ == "__main__":
use_thread()
生产者_消费者模型_类的继承实现
什么是生产者-消费者模型?
某个模块专门负责身缠数据, 可以认为是工厂;
另外一个模块负责对生产的数据进行处理的, 可以认为是消费者.
在生产者和消费者之间加个缓冲区(队列queue实现), 可以认为是商店.
生产者 -----》缓冲区 -----》 消费者
优点:
- 解耦:生产者和消费者的依赖关系减少;
- 支持并发;是两个独立的个体, 可并发执行;
# 需求1: 给定200个ip地址, 可能开放端口为80, 443, 7001, 7002, 8000, 8080,
9000(flask), 9001
以http://ip:port形式访问页面以判断是否正常访问.
1). 构建所有的url地址;===存储到一个数据结构中
2). 依次判断url址是否可以成功访问
实现多线程:
1). 实例化对象threading.Thread;
2). 自定义类, 继承threading.Thread, 重写run方法(存储任务程序);
def create_data():
"""创建测试数据, 文件中生成200个IP"""
with open('doc/ips.txt', 'w') as f:
for i in range(200):
f.write('172.25.254.%s\n' % (i + 1))
print("测试数据创建完成!")
import time
import threading
from queue import Queue
from urllib.request import urlopen
class Producer(threading.Thread):
def __init__(self, queue):
super(Producer, self).__init__()
self.q = queue
def run(self):
"""生产测试需要的url地址http://ip:port"""
ports = [80, 443, 7001, 7002, 8000, 8080, 9000, 9001]
with open('doc/ips.txt') as f:
for line in f:
ip = line.strip()
for port in ports:
url = "http://%s:%s" %(ip, port)
time.sleep(1)
self.q.put(url)
print("生产者生产url:%s" %(url))
class Consumer(threading.Thread):
def __init__(self, queue):
super(Consumer, self).__init__()
self.q = queue
def run(self):
url = self.q.get()
try:
urlObj = urlopen(url)
except Exception as e:
print("%s不可访问" %(url))
else:
pageContentSize = len(urlObj.read().decode('utf-8'))
print("%s可以访问, 页面大小为%s" %(url, pageContentSize))
def main():
q = Queue()
p = Producer(q)
p.start()
for i in range(400):
c = Consumer(q)
c.start()
if __name__ == '__main__':
# create_data()
main()

实例化对象方式_实现线程同步之线程锁
1. 为什么需要线程锁?
- 多个线程对同一个数据进行修改时, 可能会出现不可预料的情况.
2. 如何实现线程锁?
- 实例化一个锁对象;
lock = threading.Lock() - 操作变量之前进行加锁
lock.acquire() - 操作变量之后进行解锁
lock.release()
未使用线程锁:
import threading
# 银行存钱和取钱
def add():
global money # 生命money为全局变量
for i in range(1000000):
money += 1 # money; money+1; money=money+1;
def reduce():
global money
for i in range(1000000):
money -= 1
if __name__ == '__main__':
money = 0
t1 = threading.Thread(target=add)
t2 = threading.Thread(target=reduce)
t1.start()
t2.start()
t1.join()
t2.join()
print("当前金额:", money)

import threading
# 银行存钱和取钱
def add(lock):
global money # 生命money为全局变量
for i in range(1000000):
# 2. 操作变量之前进行加锁
lock.acquire()
money += 1 # money; money+1; money=money+1;
# 3. 操作变量之后进行解锁
lock.release()
def reduce(lock):
global money
for i in range(1000000):
# 2. 操作变量之前进行加锁
lock.acquire()
money -= 1
# 3. 操作变量之后进行解锁
lock.release()
if __name__ == '__main__':
money = 0
# 1. 实例化一个锁对象;
lock = threading.Lock()
t1 = threading.Thread(target=add, args=(lock,))
t2 = threading.Thread(target=reduce, args=(lock,))
t1.start()
t2.start()
t1.join()
t2.join()
print("当前金额:", money)

继承方式_实现线程同步之线程锁
import threading
class AddThread(threading.Thread):
def __init__(self, lock):
super(AddThread, self).__init__()
self.lock = lock
def run(self):
for i in range(1000000):
# 2. 操作变量之前进行加锁
self.lock.acquire()
global money
money += 1 # money; money+1; money=money+1;
# 3. 操作变量之后进行解锁
self.lock.release()
class ReduceThread(threading.Thread):
def __init__(self, lock):
super(ReduceThread, self).__init__()
self.lock = lock
def run(self):
global money
for i in range(1000000):
# 2. 操作变量之前进行加锁
lock.acquire()
money -= 1
# 3. 操作变量之后进行解锁
lock.release()
if __name__ == '__main__':
money = 0
# 1. 实例化一个锁对象;
lock = threading.Lock()
t1 = AddThread(lock)
t2 = ReduceThread(lock)
t1.start()
t2.start()
t1.join()
t2.join()
print("当前金额:", money)

下载器
from urllib.request import urlopen
# url = "http://imgsrc.baidu.com/forum/w%3D580/sign=16d420cb8b01a18bf0eb1247ae2e0761/22a4462309f790520522e1d900f3d7ca7bcbd51c.jpg"
# urlObj = urlopen(url)
# imgContent = urlObj.read()
# with open("doc/teiba.jpg", 'wb') as f:
# f.write(imgContent)
DOWNLOAD_DIR = 'doc'
def download(url):
try:
urlObj = urlopen(url, timeout=3)
except Exception as e:
print("download %s error" % (url))
imgContent = None
else:
# http://imgsrc.baidu.com/forum/w%3D580/sign=16d420cb8b01a18bf0eb1247ae2e0761/22a4462309f790520522e1d900f3d7ca7bcbd51c.jpg
filename = url.split("/")[-1]
# 'wb' === 写的是二进制文件(图片, 视频, 动图, .pdf)
# 'ab'
with open("%s/%s" % (DOWNLOAD_DIR, filename), 'ab') as f:
# 如果文件特别大的时候, 建议分块下载;每次只读取固定大小, 防止占用内存过大.
while True:
imgContentChunk = urlObj.read(1024 * 3)
if not imgContentChunk:
break
f.write(imgContentChunk)
# 可以添加下载的程度(百分率);
print("%s下载成功" % (filename))
url = 'http://imgsrc.baidu.com/forum/w%3D580/sign=3cf8899b5d0fd9f9a0175561152cd42b/74094b36acaf2edd74ccef0e811001e93901931c.jpg'
download(url)

实现多线程的下载器
优势:
当你创建用户界面并想保持界面的可用性时,线程就特别有用。
没有线程,用户界面将变得迟钝,当你下载一个大文件或者执
行一个庞大的数据库查询命令时用户界面会长时间无响应。为
了防止这样情况发生,你可以使用多线程来处理运行时间长的
进程并且在完成后返回界面进行交互。
import threading
from urllib.request import urlopen
DOWNLOAD_DIR = 'doc'
class DownloadThread(threading.Thread):
def __init__(self, url):
super(DownloadThread, self).__init__()
self.url = url
def run(self):
try:
urlObj = urlopen(self.url, timeout=3)
except Exception as e:
print("download %s error\n" % (self.url), e)
imgContent = None
else:
# http://imgsrc.baidu.com/forum/w%3D580/sign=16d420cb8b01a18bf0eb1247ae2e0761/22a4462309f790520522e1d900f3d7ca7bcbd51c.jpg
filename = self.url.split("/")[-1]
# 'wb' === 写的是二进制文件(图片, 视频, 动图, .pdf)
# 'ab'
with open("%s/%s" % (DOWNLOAD_DIR, filename), 'ab') as f:
# 如果文件特别大的时候, 建议分块下载;每次只读取固定大小, 防止占用内存过大.
while True:
imgContentChunk = urlObj.read(1024 * 3)
if not imgContentChunk:
break
f.write(imgContentChunk)
# 可以添加下载的程度(百分率);
print("%s下载成功" % (filename))
url1 = "ftp://172.25.254.250/pub/book/python/01_MIT.Introduction.to.Computation.and.Programming.Using.Python%20revised%20and%20expanded%20edition.pdf"
# url2 = "ftp://172.25.254.250/pub/book/python/01_python%E6%A0%B8%E5%BF%83%E7%BC%96%E7%A8%8B.pdf"
# url3 = "ftp://172.25.254.250/pub/book/python/02_Python%20Cookbook%EF%BC%88%E7%AC%AC3%E7%89%88%EF%BC%89%E4%B8%AD%E6%96%87%E7%89%88.pdf"
url2 = 'ftp://172.25.254.250/pub/book/python/02_interview_exercise.pdf'
url3 = "ftp://172.25.254.250/pub/book/python/02_python-data-structure-cn.pdf"
urls = [url1, url2, url3]
for url in urls:
thread = DownloadThread(url)
thread.start()
多线程实现获取地理位置
import threading
import time
from urllib.request import urlopen
def timeit(f):
def wrapper(*args, **kwargs):
start_time = time.time()
res = f(*args, **kwargs)
end_time = time.time()
print("%s函数运行时间:%.2f" % (f.__name__, end_time - start_time))
return res
return wrapper
class MyThread(threading.Thread):
def __init__(self, ip):
super(MyThread, self).__init__()
self.ip = ip
def run(self):
url = "http://ip-api.com/json/%s" % (self.ip)
urlObj = urlopen(url)
# 服务端返回的页面信息, 此处为字符串类型
pageContent = urlObj.read().decode('utf-8')
# 2. 处理Json数据
import json
# 解码: 将json数据格式解码为python可以识别的对象;
dict_data = json.loads(pageContent)
print("""
%s
所在城市: %s
所在国家: %s
""" % (self.ip, dict_data['city'], dict_data['country']))
@timeit
def main():
ips = ['12.13.14.%s' % (i + 1) for i in range(1000)]
threads = []
# 线程在创建和销毁过程中需要耗费资源和时间;
for ip in ips:
t = MyThread(ip)
threads.append(t)
t.start()
[thread.join() for thread in threads]
if __name__ == '__main__':
main()
线程池submit
# python3.2版本之后才有的;
from concurrent.futures import ThreadPoolExecutor
def job(num):
# 需要执行的任务
print("这是一个%s任务" %(num))
return "执行结果:%s" %(num)
if __name__ == '__main__':
# 1. 实例化线城池对象,线城池里面包含5个线程执行任务;
pool = ThreadPoolExecutor(max_workers=5)
futures = []
for i in range(1000):
# 往线程池里面扔需要执行的任务, 返回的是一个对象(_base.Future()),
f1 = pool.submit(job, i)
futures.append(f1)
# 判断第一个任务是否执行结束;
futures[0].done()
# 获取任务的执行结果;
print(futures[0].result())

线程池submit应用
线程池里面的线程越多越好?
当测试数据很少时,创建线程消耗时间会影响测试数据的时间,此时线程数越少越好
import time
def timeit(f):
def wrapper(*args, **kwargs):
start_time = time.time()
res = f(*args, **kwargs)
end_time = time.time()
print("%s函数运行时间:%.2f" % (f.__name__, end_time - start_time))
return res
return wrapper
# python3.2版本之后才有的;
import threading
from concurrent.futures import ThreadPoolExecutor, wait
from urllib.request import urlopen
def get_area(ip):
url = "http://ip-api.com/json/%s" % (ip)
urlObj = urlopen(url)
# 服务端返回的页面信息, 此处为字符串类型
pageContent = urlObj.read().decode('utf-8')
# 2. 处理Json数据
import json
# 解码: 将json数据格式解码为python可以识别的对象;
dict_data = json.loads(pageContent)
print("""
%s
所在城市: %s
所在国家: %s
""" % (ip, dict_data['city'], dict_data['country']))
@timeit
def use_ten_thread():
# 1. 实例化线城池对象,线城池里面包含5个线程执行任务;
pool = ThreadPoolExecutor(max_workers=10)
futures = []
for i in range(30):
print("当前线程数:", threading.activeCount())
ip = '12.13.14.%s' %(i+1)
# 往线程池里面扔需要执行的任务, 返回的是一个对象(_base.Future()),
f1 = pool.submit(get_area, ip)
futures.append(f1)
# 等待futures里面所有的子线程执行结束, 再执行主线程(join())
wait(futures)
@timeit
def use_hundred_thread():
# 1. 实例化线城池对象,线城池里面包含5个线程执行任务;
pool = ThreadPoolExecutor(max_workers=100)
futures = []
for i in range(30):
print("当前线程数:", threading.activeCount())
ip = '12.13.14.%s' %(i+1)
# 往线程池里面扔需要执行的任务, 返回的是一个对象(_base.Future()),
f1 = pool.submit(get_area, ip)
futures.append(f1)
wait(futures)
if __name__ == '__main__':
use_ten_thread()
use_hundred_thread()
# 理论上用少量数据测试时
# 使用一百个线程所消耗的时间长
# 由于网络有延迟使得十个线程消耗时间长


线程池map的应用
import time
def timeit(f):
def wrapper(*args, **kwargs):
start_time = time.time()
res = f(*args, **kwargs)
end_time = time.time()
print("%s函数运行时间:%.2f" % (f.__name__, end_time - start_time))
return res
return wrapper
# python3.2版本之后才有的;
import threading
from concurrent.futures import ThreadPoolExecutor, wait
from urllib.request import urlopen
def get_area(ip):
url = "http://ip-api.com/json/%s" % (ip)
urlObj = urlopen(url)
# 服务端返回的页面信息, 此处为字符串类型
pageContent = urlObj.read().decode('utf-8')
# 2. 处理Json数据
import json
# 解码: 将json数据格式解码为python可以识别的对象;
dict_data = json.loads(pageContent)
print("""
%s
所在城市: %s
所在国家: %s
""" % (ip, dict_data['city'], dict_data['country']))
@timeit
def use_ten_thread():
# 1. 实例化线城池对象,线城池里面包含5个线程执行任务;
pool = ThreadPoolExecutor(max_workers=10)
# futures = []
# for i in range(30):
# print("当前线程数:", threading.activeCount())
# ip = '12.13.14.%s' %(i+1)
# # 往线程池里面扔需要执行的任务, 返回的是一个对象(_base.Future()),
# f1 = pool.submit(get_area, ip)
# futures.append(f1)
#
# # 等待futures里面所有的子线程执行结束, 再执行主线程(join())
# wait(futures)
ips = ['12.13.14.%s' % (ip + 1) for ip in range(30)]
pool.map(get_area, ips)
@timeit
def use_hundred_thread():
# 1. 实例化线城池对象,线城池里面包含5个线程执行任务;
pool = ThreadPoolExecutor(max_workers=100)
# futures = []
# for i in range(30):
# print("当前线程数:", threading.activeCount())
# ip = '12.13.14.%s' % (i + 1)
# # 往线程池里面扔需要执行的任务, 返回的是一个对象(_base.Future()),
# f1 = pool.submit(get_area, ip)
# futures.append(f1)
#
# wait(futures)
ips = ['12.13.14.%s' % (ip + 1) for ip in range(30)]
pool.map(get_area, ips)
if __name__ == '__main__':
use_ten_thread()
use_hundred_thread()
# 缺点:主线程不能等待子线程全部运行完毕再执行
