实时监控系统
1、 系统流程图
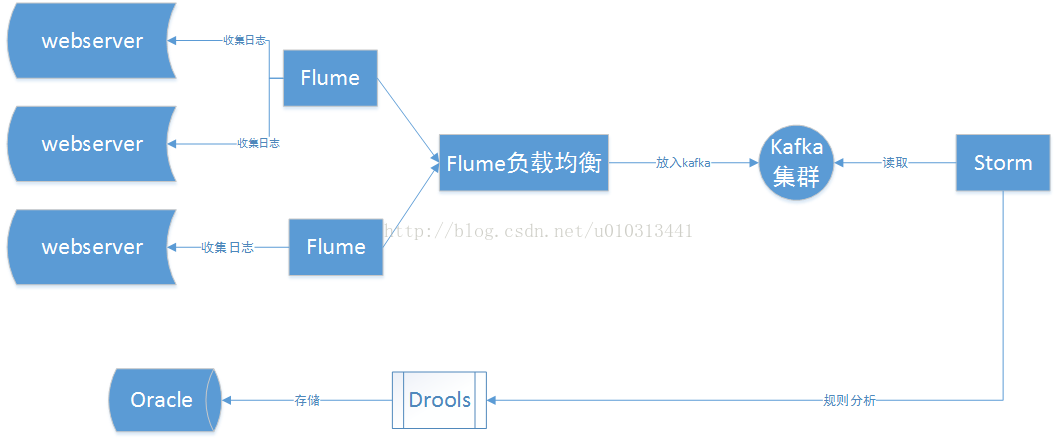
2、 Kafka
简介:Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。
特征:
i. 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
ii. 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
iii. 支持通过Kafka服务器和消费机集群来分区消息。
iv. 支持Hadoop并行数据加载。
相关术语:
i. Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker
ii. Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
iii. Partition:Partition是物理上的概念,每个Topic包含一个或多个Partition.
iv. Producer:负责发布消息到Kafka broker
v. Consumer:消息消费者,向Kafka broker读取消息的客户端。
vi. Consumer Group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
安装kafka:
1、修改配置文件/conf/server. Properties
broker.id=0port=9092host.name=192.168.20.7
num.network.threads=3num.io.threads=8socket.send.buffer.bytes=102400socket.receive.buffer.bytes=102400socket.request.max.bytes=104857600log.dirs=/usr/saaspay_test/storm/logs/kafka
num.partitions=1num.recovery.threads.per.data.dir=1log.retention.hours=168log.segment.bytes=1073741824log.retention.check.interval.ms=300000log.cleaner.enable=falsezookeeper.connect=192.168.20.208:2181
zookeeper.connection.timeout.ms=60002、启动broker
nohup bin/kafka-server-start.shconfig/server.properties &
3、查看进程是否正常
ps -ef | grep kafka4、检查端口9092是否开放
netstat -tlnup | grep 90925、创建topic
bin/kafka-topics.sh --create --topicaccountlog --partitions 1 --replication-factor 1 --zookeeper192.168.20.208:2181
6、查看topic详情
bin/kafka-topics.sh --describe --topicaccountlog --zookeeper192.168.20.208:2181
7、启动console消息生产者,发送消息到kafka的topic上
nohup bin/kafka-console-producer.sh--broker-list 192.168.20.7:9092 --topic accountlog &
8、启动console消息消费者,读取kafka上topic的消息
bin/kafka-console-consumer.sh --zookeeper192.168.20.208:2181 --topic accountlog --from-beginning
3、Apache flume
简介:Flume是Apache提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
数据处理:Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力 Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力。
工作方式: Flume-ng读入数据和写出数据现在由不同的工作线程处理(称为 Runner)。 在 Flume-og 中,读入线程同样做写出工作(除了故障重试)。如果写出慢的话(不是完全失败),它将阻塞 Flume 接收数据的能力。这种异步的设计使读入线程可以顺畅的工作而无需关注下游的任何问题。
Source:负责收集,channel:负责通信,sink:负责处理
安装Flume:
1、编写flume agen配置文件flume-kafka-storm.properties
# The configuration file needs to define thesources,
# the channels and the sinks.
# Sources, channels and sinks are defined peragent,
# in this case called 'agent'
a1.sources =s1
a1.channels =c1
a1.sinks = kafka_sink
#define sources
a1.sources.s1.type = exec
a1.sources.s1.command =tail -F/usr/saaspay_test/logs/saaspay_accounts/accounts_info.log
#definechannels
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000000
a1.channels.c1.transactionCapacity = 1000000
#definekafka sinks
a1.sinks.kafka_sink.type =org.apache.flume.sink.kafka.KafkaSink
a1.sinks.kafka_sink.topic=accountlog
a1.sinks.kafka_sink.brokerList=192.168.20.7:9092,192.168.20.30:9092
a1.sinks.kafka_sink.requireAcks=1
a1.sinks.kafka_sink.batch=20
#Bind the source and sink to the channel
a1.sources.s1.channels = c1
a1.sinks.kafka_sink.channel = c1
2、启动flume agent
nohup bin/flume-ng agent -n a1 -c conf/ --conf-fileconf/flume-kafka-storm.properties -Dflume.root.logger=INFO,LOGFILE &
3、启动kakfa的console消费者查看是否有日志产生
bin/kafka-console-consumer.sh--zookeeper 192.168.20.208:2181 --topic accountlog --from-beginning
4、Apache Storm
简介:是一个分布式的、容错的实时处理系统
相关术语:
1、Nimbus
Storm集群主节点,负责资源分配和任务调度。
2、Supervisor
Storm集群工作节点,接受Nimbus分配任务,管理Worker。
3、Worker
Supervisor下的工作进程,具体任务执行。
4、Task
Worker下的工作线程,0.8版本之后表示逻辑线程。
5、Topology
实时计算逻辑,计算拓扑,由Spout和Bolt组成的图状结构。
6、Spout
Storm编程模型中的消息源,可进行可靠传输(ack/fail机制)。
7、Bolt
Storm编程模型中的处理组件,定义execute方法进行实际的数据逻辑处理。
8、Stream
拓扑中的消息流,传输的对象是Tuple。
9、Tuple
一次消息传递的基本单元。
10、Stream Groupings 数据流分组策略
1)Shuffle Grouping: 随机分组,保证bolt接受的tuple数据相同。
2)Fields Grouping: 按字段分组,相同tuple会分到同一个bolt中。
3)All Grouping: 广播发送,每个tuple会发送所有bolt中。
4)Global Grouping: 全局分组,所有tuple发送给task_id最小的bolt。
5)Non Grouping: 不分组,效果与Shuffle相似,发布订阅同一个线程。
6)Direct Grouping: 直接分组,需要手动指定bolt。
7)Custom Grouping: 自定义分组,自己实现分组方式。
集群框架:
数据处理流程图:
拓扑图分析:
安装Storm:
1、 配置conf/ storm.yaml
storm.zookeeper.servers:
- "192.168.20.208"
ui.port : 8090
storm.local.dir:"/usr/saaspay_test/storm/logs/storm"
nimbus.host: "192.168.20.30"
nimbus.thrift.port: 6628
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
2、启动nimbus主节点
./storm nimbus >/dev/null 2>&1&
3、 启动supervisor从节点
./storm supervisor >/dev/null2>&1 &
4、启动strom ui管理界面
./storm ui >/dev/null 2>&1 &
5、 kill 拓扑
./storm kill saaspay
6、 运行jar
./storm jar ~/storm/jars/saaspay_bigdata-0.0.1-SNAPSHOT.jarcom.mobo360.storm.account.main.AccountTopology saaspay_kafka_account
结束storm进程:
kill -9 $(ps-ef|grep nimbus|gawk '$0 !~/grep/ {print $2}' |tr -s '\n' ' ')
kill -9 $(ps-ef|grep supervisor|gawk '$0 !~/grep/ {print $2}' |tr -s '\n' ' ')
kill -9 $(ps-ef|grep ui|gawk '$0 !~/grep/ {print $2}' |tr -s '\n' ' ')
5、Drools
简介:具有一个易于访问企业策略、易于调整以及易于管理的开源业务规则引擎。