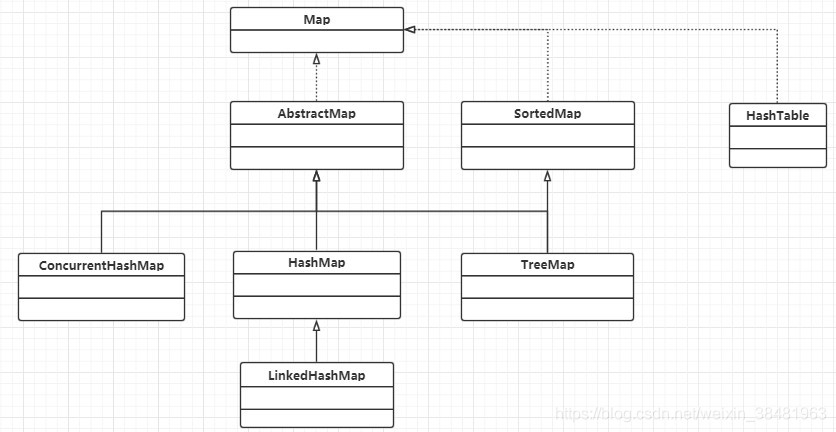
首先看一下这几个类的继承类图
1、HashMap
public class HashMap<K, V>
extends AbstractMap<K, V> implements Map<K, V>, Cloneable, Serializable {
...
}
底层实现是:数组+链表+红黑树
当出现冲突时,将节点放在冲突节点的后面形成链表,当链表的长度超过一定值时,将链表转换为红黑树进行存储。
HashMap键和值均可为null,键只能有一个值为null
HashMap是非线程安全的
如何将HashMap变成线程安全的?
Collections.synchronizedMap(map);
HashMap存储的是键值对
HashMap的put和get方法的过程
(1)put()
1.判断表是否为空,如果是,初始化表
2.通过key的hash值计算索引,若索引下节点为空,将新节点放在索引位置
3.如果索引不为空,则判断该索引节点和新节点的hash值是否相等,之后判断key值是否相等,如果相等该节点即为要查找的节点。
4.如果索引节点不是新节点,则判断是否是TreeNode,若是,则调用putTreeVal
5.如果不是,则进行普通链表查询
6.判断e是否为空,若为空则插入新值,若不为空,则更新节点的value
7.判断节点数量是否超过阈值,若超过阈值则进行扩容
(2)get()
1.对table进行验证,table是否为空,长度是否大于0,通过key的hash值计算出的索引处是否为空
2.如果上面条件都满足
3.判断first节点的hash值和key的是否一致,若一致,则用equals方法判断,若相等找到目标节点,返回。
4.判断first的下一个节点是否存在
5.若存在判断是否为TreeNode,若为TreeNode,调用getTreeNode方法
6.若不是TreeNode,则遍历链表,找到返回value
7.找不到,返回null
重写equals时也要同时覆盖hashcode。
举个例子
public class People{
private String name;
private int age;
public People(String name, int age){
this.name = name;
this.age = age;
}
public boolean equals(Object obj){
if(this == obj){
return true;
}
if(obj == null){
return false;
}
if(this.getClass()!=obj.getClass()){
return false;
}
People p = (People)obj;
return this.name.equals(p.name) && this.age == p.age;
}
public static void main(String[]args){
People p = new People("Marry",18);
People q = new People("Marry",18);
System.out.println(p.equals(q)); //判断两个对象是否相等
System.out.println(p.hashCode()); //输出对象的hash码
System.out.println(q.hashCode());
HashMap<People,Integer> map = new HashMap<>();
map.put(p,1); //将p对象放入map
System.out.println(map.get(q)); //用q对象将其取出
}
}
/*
true
1053782781
1211888640
null
*/
这段代码的含义是:创建两个name和age均为Marry,18的对象,从重写的equals方法来判断,这两个对象是一样的,结果应当是返回这个对象,但是返回值却是null,表示未找到 ,为什么?因为这两个对象的hashcode不一致,因此被判断为不同的对象。这就是为什么equals方法重写后,应当重写hashCode方法。
注:这里应当了解HashMap的查找方法,HashMap首相会生成查找对象的hash值,先通过hash值判断是否存在这个对象,如果存在之后用equals方法判断两个对象是否相等,如果相等返回该对象,反之,返回null。相同的hash值可能表示不同的对象,所以需要再hash值相同的情况下再用equals判断。
我们重写hashCode方法:
public int hashCode(){
return name.hashCode()+age;
}
之后结果为:
true
74114071
74114071
1
最后结果为1,取到了这个对象。
2、LinkedHashMap
public class LinkedHashMap<K, V>
extends HashMap<K, V> implements Map<K, V> {
....
}
LinkedHashMap继承自HashMap,具备HashMap的特性
区别:LinkedHashMap保证插入顺序
LinkedHashMap增加了一个链表来保持元素的插入顺序,所以遍历时和插入时的顺序是一样的。代码实现是在Node节点类中添加了before和after两个指针,确保元素的插入顺序。
static class Entry<K, V> extends Node<K, V> {
LinkedHashMap.Entry<K, V> before;
LinkedHashMap.Entry<K, V> after;
Entry(int hash, K key, V value, Node<K, V> next) {
super(hash, key, value, next);
}
}
3、HashTable
public class Hashtable<K, V>
extends Dictionary<K, V> implements Map<K, V>, Cloneable, Serializable {
.....
}
HashTable继承自Dictionary,实现了Map接口。
HashTable不是继承自AbstractMap,这一点要注意。
HashTable是线程安全的
但是HashTable是对所有字段加锁,所以性能上不是很好。他的改进是ConcurrentHashMap。
4、ConcurrentHashMap
public class ConcurrentHashMap<K, V>
extends AbstractMap<K, V> implements ConcurrentMap<K, V>, Serializable {
...
}
ConcurrentHashMap是线程安全的
他是HashTable的改进版,HashTable是对所有数据进行加锁,而ConcurrentHashMap是将数据进行分段,然后对每一段单独加锁,这样就可以多个线程同时更改这张表的不同段,提高了性能。
5、TreeMap
public class TreeMap<K, V>
extends AbstractMap<K, V> implements NavigableMap<K, V>, Cloneable, Serializable {
...
}
TreeMap的底层实现是红黑树
TreeMap不是线程安全的
他的主要特点是能够对节点进行排序。
TreeMap 默认排序规则:按照key的字典顺序来排序(升序)
自定义排序规则:要实现Comparator接口。