Oracle的笔记整理
使用CMD命令连接到oracle
sqlplus / as sysdba;
连接到oracle后的提示。

接着可以在sql>后面输入命令来执行添加用户操作
● 添加用户
create user xxx identified by 1234;
创建了一个name为xxx,密码为1234的用户
● 授权用户
grant resource,connect to xxx;
将资源和连接权限赋予给xxx用户
● 删除用户
drop user xxx cascade;
删除xxx用户
● 解除绑定
alter user xxx account unlock;
解除xxx用户的绑定
oracle的数据类型:
● number 数字类型,可以同时表示小数或整数
● number(5) 数字类型,表示5位整数
● number(5,2) 数字类型,表示3位整数,2位小数
● varchar(len) 字符串类型,len表示长度注:【英文占1个字节,中文占2个字节,实际占用的空间以实际字符为准】
● nvarchar(len) 字符串类型,len表示长度注:【每个字符占2个字节,中英文不区别。】
● char(len) 字符串类型,len表示长度注:【如果实际数据不够len,默认以空格填充】
● Date() 日期类型,精度精确到秒
● timestamp() 日期类型,精度精确到毫秒
● nclob() 二进制大容量类型,存储大文本,不可自己赋值
● clob() 二进制大容量类型,存储大文本,不可自己赋值
● blob() 二进制大容量类型,存储大文本,不可自己赋值
oracle的常用命令
● 创建表
create table student[表名]
(
sno[列名] number[数据类型];
sname[列名] nvarchar2(10)[数据类型];
sbirthday[列名] date[数据类型];
)
● 新增字段
alter table student[表名] add score[字段名] number(3)[数据类型]
● 修改字段
alter table student[表名] modify sname[字段名] nvarchar2(5)[新的数据类型]
● 删除字段
alter table student[表名] drop column score[字段名]
● 删除表
drop table student[表名]
● 删除表数据【删除表中所有数据,包括主外键】
truncate table student[表名]
● 插入数据
insert into student(sno,sname,sbirthday) values(1,'张三',sysdate)
insert into student values(2,'张三',sysdate)
● 修改数据
update student set sname='李四'[要修改的数据] where sno=2[条件]
● 删除数据
delete from student where sno = 2;
delete from student; [删除所有数据]
● 查询数据
select * from student[查询表中所有数据]
select sno,sname from student[查询sno和sname的数据]
Oracle的关键字
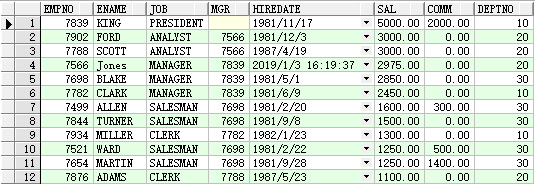
【oracle的scoot用户会自带emp表和Dept表】[以这两张表为例]
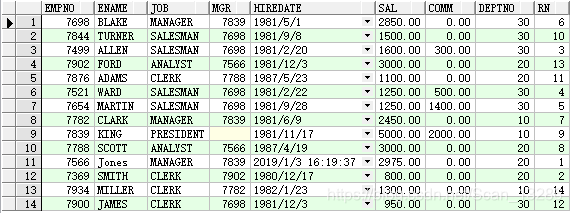
select * from emp;
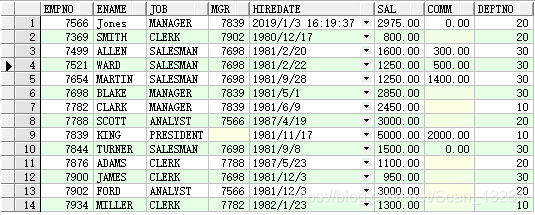
select * from dept;
● where
例:select * from emp where mgr= 7839
where 关键字表示条件,where后面接查询所需要的条件。

● and
例:select * from emp where mgr = 7839 and empno = 7698
and 用于连接两个条件【两个条件都必须满足】

● or
例:select * from emp where mgr = 7839 or empno = 7934
or 用于连接连个条件【满足任意一个条件】

● in
例:select * from emp where empno in (7369,7499,7902)
in 用于符合 ()内条件

● between…and…
例:select * from emp where empno between 7300 and 7700
between…and… 作用于两者之间的范围

● dual
例:select 1 from dual;
dual 是oracle中的虚拟表。用于表示常量或其他。

● sysdate
例:select sysdate from dual
sysdate 获取系统时间

查询今天是今年的第多少天
例:select to_char(sysdate,'ddd') from dual;
查询今天是当月的多少天
例:select to_char(sysdate,'dd') from dual;
查今天是这个星期的多少天
例:select to_char(sysdate,'d') from dual;
当前日期前5年的时间
例:select sysdate,sysdate-interval '5' year,'5' month from dual;
● add_months()
例:select add_months(sysdate,-10)from dual;
获取当前日期前10个月的日期
● last_day()
例:select last_day(sysdate) from dual;
获取当前时间最后一天
● to_date
例:select to_date('2018-12-31','yyyy-mm-dd') from dual
to_date 转换为日期类型

● to_char
例:select to_char(sysdate,'yyyy-mm-dd') from dual
to_char 转换为字符串

● to_number
例:select to_number(to_char(sysdate,'yyyy')) from dual
to_number 转换为数字类型

● like
例:select * from emp where ename like '_L%'
like 用于模糊查询,_代表一个字符,%代表多个字符

● not
例:select * from emp where job not in ('SALESMAN','CLERK');
not 相反 【和in一起用表示不包含】【和like一起用代表不像】

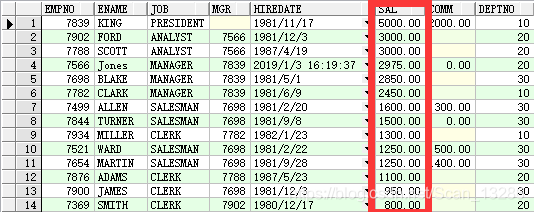
● order by
例:select * from emp order by sal desc;
order by 用于排序。desc表示降序,asc表示升序,默认升序
● distinct
例:select distinct job from emp;
distinct 用于去重[去除重复]

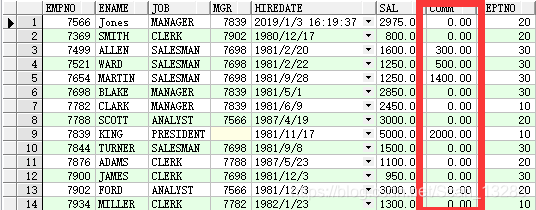
● nvl()
例:update emp set comm = nvl(comm,0) ;
nvl(列名,替换) 如上:判断comm字段是否都为null的值,如果有就替换成0
● nvl2(str,ture,false)
例:select nvl2(null,1,3) from dual;
判断str是否为null,如果是则为3,如果不是则为1
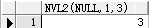
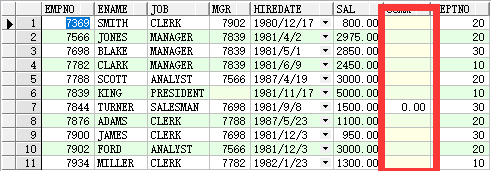
● is null
例:select * from emp where comm=0 or is null;
查询没有奖金的员工信息;
● 别名
例:select e.* from emp e
别名用于给比较长的字段或表名取个比较好输入的名字
直接在表名或字段名后面空格然后接别名就好
● length()
例:select length('asdaf') from dual
判断字符长度,中文算一个字符

● lengthb()
例:select lengthb('asdaf阿') from dual
判断字符长度,中文算两个字符
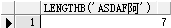
● upper
例:select upper('asdsafasf') from dual;
将字符串转换为大写

● lower
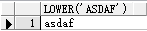
例:select lower('ASDAF') from dual;
将字符串转换为小写
● substr(str,start,num)
例:select substr('adas',1,2) from dual;
截取字符串,start表示开始位置,num表示截取数目

● instr(str,s,start,num)
例:select instr('asdasafas','as',1,1)from dual;
查找字符在字符串中的位置,start表示开始查找的文字,num表示第num个s出现的位置

● replace(str,new,old)
例:select replace('asdasafas','as','z') from dual;
替换字符

● trunc()
例:select trunc(4.7) from dual;
向下取整

● ceil()
例:select ceil(4.7) from dual;
向上取整

● decode
例:select decode(80,80,'良',70,'一般',60,'及格',50,'差','极差') from dual;
相当与switch语句

● 聚合函数
例:select count(sal),max(sal),min(sal),avg(sal),sum(sal) from emp;
count() 计数 \ max() 最大值 \ min() 最小值 \ avg() 平均值 \ sum() 求和

● group by
例:select deptno,max(sal),min(sal),avg(sal),sum(sal) from emp group by deptno;
–group by 用于排序–
–因为用于排序,所以不能查询所有字段,只能查询排序字段,或聚合函数–
–group by 后面不能用where,但是可以使用having–

● having
例:select deptno,count(1) from emp group by deptno having count(1) > 3;
和where用法相似,只能用于group by 之后
如下:求出人数多于3个的部门

Oracle中行转列
● 首先先创建一张表Score
create table score
(
course nvarchar2(20),
sname nvarchar2(20),
score number
)
insert into score values('语文','张三',87);
insert into score values('数学','张三',88);
insert into score values('英语','张三',64);
insert into score values('语文','李四',64);
insert into score values('数学','李四',75);
insert into score values('英语','李四',87);
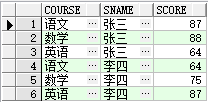
● 表大概这个样子
例:select * from score
● 然后进行行转列操作
例:select sname,max(decode(course,'语文',score)) 语文,max(decode(course,'数学',score)) 数学,max(decode(course,'英语',score))英语 from test group by sname;
然后就上表就变成了下面这个样子了

多表查询
例:select * from emp,dept
两张表同时查询,则两表的关系结构为
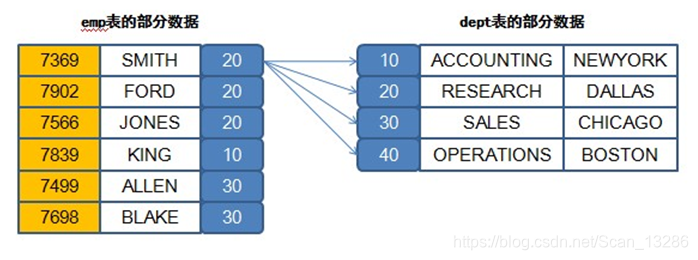
所以直接查的话,emp表有14条数据,dept表有4条数据,则会生成14x4 = 56条数据
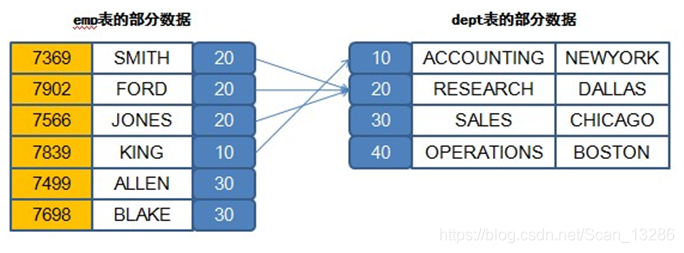
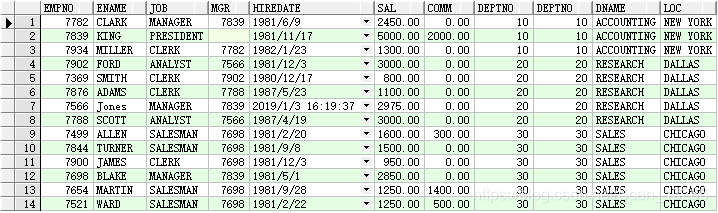
● where 关联
例:select * from emp,dept where emp.deptno = dept.deptno;
使用where关联,emp表的deptno与dept表的deptno相同则关联,关系结构就是
结果:
● natural join
例:select * from emp natural join dept;
使用 natural join 和where 关联相似,不过natural join 会自动识别相同的字段。

● cross join
例:select * from emp cross join dept;
cross join和直接连接一样,会生成 54条数据,数据量比较大,不截图了
● inner join … on …
例:select * from emp inner join dept on emp.deptno = dept.deptno;
和 where 关联 同样作用,只是写法不同
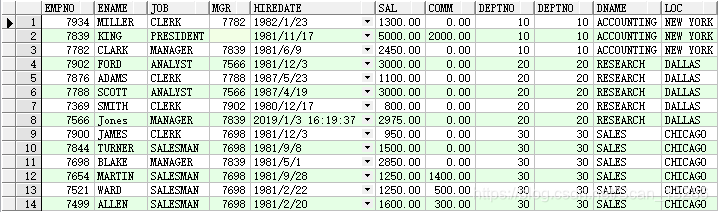
● left join
例:select * from emp left join dept on emp.deptno = dept.deptno;
左外连接 【以左表为主表进行关联】
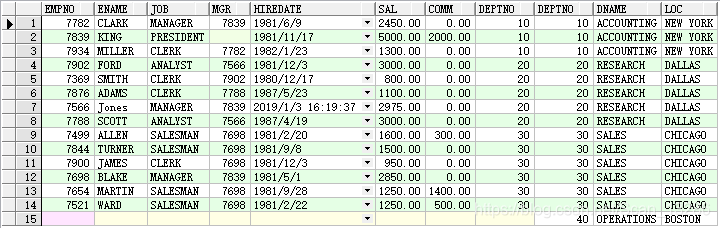
● right join
例:select * from emp right join dept on emp.deptno = dept.deptno;
右外连接 【以右表为主表进行关联】,同上表相比,多出了deptno为40的部门,即使没有匹配元素,也是会显示出来
嵌套查询
● 显示与SMITH同以部门的员工
例:select * from emp where deptno = (select deptno from emp where ename = 'SMITH');
先执行“select deptno from emp where ename = ‘SMITH’)”,可以看出结果是

之后可以把它的查询结果将当作条件查询。得到结果

● union
例:(select sname,ssex,sbirthday from t_student) union (select tname,tsex,tbirthday from t_teacher);
先执行“select sname,ssex,sbirthday from t_student”和“select tname,tsex,tbirthday from t_teacher”,可以得到表
和
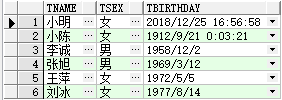
在使用union 连接,得到表
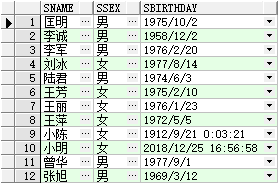
union 可以使拥有相同字段类型的表进行联合。
● union all
例:(select sname,ssex,sbirthday from t_student) union all (select tname,tsex,tbirthday from t_teacher);
和union 用法相同,只是不会去除重复字段。
● intersect
例:select * from emp where sal >= 1500 intersect select * from emp where job='SALESMAN';
intersect 所选取的范围为交集,即两个都符合

● minus
例:select * from emp where sal >= 1500 minus select * from emp where job='SALESMAN';;
intersect 所选取的范围为出去交集的部分。

● all
例:select * from emp where sal > all(select sal from emp where deptno = 30);
查询工资比30号部门所有员工工资高的员工信息
先执行“select sal from emp where deptno = 30” 可以得到下面即所有30部门的员工工资
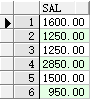
all的作用即,大于这个结果集所有的数据。
结果:

● any
例:select * from emp where sal > any(select sal from emp where deptno = 30);
查询工资比30号部门员工工资高的员工信息
先执行“select sal from emp where deptno = 30” 可以得到下面即所有30部门的员工工资
all的作用即,大于这个结果集中任意的数据。
结果:
● some
例:select * from emp where sal > some(select sal from emp where deptno = 30);
some 和any 的用法一致
● exists
例:select * from dept d where exists (select * from emp e where e.deptno=d.deptno)
存在(判断某种条件存在,而不是某个字段或某个值)
即存在 e.deptno=d.deptno 条件的数据。
分页查询
例:select * from ( select emp.*,rownum rm from emp order by empno ) t where t.rm between 1 and 5;
执行“select emp.*,rownum rm from emp order by empno”,排序的表会生成rownum列,即行编号
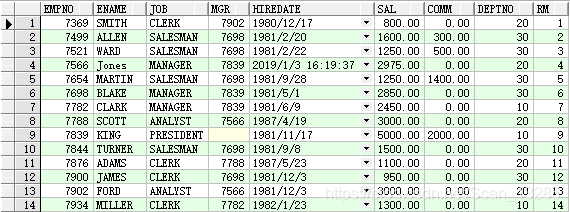
之后可以根据行编号进行查询,以实现分页查询:

或者这句:select * from (select t.*,rownum rn from (select * from emp order by empno) t) a where a.rn between 3 and 10;
原理相同,只是在分页查询前先进行查询排序之后的编号,以提高代码的严谨性。
随机数dbms_random.random()
例:select emp.*,rownum rn from emp order by dbms_random.random()
如上表所示:使用了“dbms_random.random()”,rownum的行号变成了随机的了