案例 :在赛事统计中,经常需要知道每一轮中都有得分的运动员。
比如第一场中,使用字典来统计队员和得分情况 d1={'a':3.'b':4,'c':3,'d':2},仅仅记录有得分的运动员,得分为0 不记录。
第二场 d2={'a':3.'b':4,'c':3,'d':2.'e':1}
第三场 d3={'b':4,'c':3,'d':2}
比如在这三场比赛中,统计每场都有进球的球员 ,在数据量不大的情况下,很容易肉眼分出来,但是当数量量大,多名球员时,使用循环的方法。从d1 中选取键,与其他的字典的键进行比较,有相同的值就放到新的列表---记录每轮都有得分的列表。
首先生成一个表示球员得分的随机字典
{'a':3.'b':4,'c':3,'d':2.'e':1} 使用random函数 {k:randint(1.7) for k in 'abcdefg'} 如果这样写生成的随机字典 ,那么每一个字典中代表球员姓名的键值abcdefg 都会出现 ,此时使用sample函数,在给出的值中随机取样,这样就不会全部取出来
random.sample
random.sample(sequence, k),从指定序列中随机获取指定长度的片断。sample函数不会修改原有序列
from random import randint,sample
{k:randint(1,6) for k in sample('abcdefghijk',randint(3,8)} #在序列‘abcdefghijk’中随机取样3-8个
代码如下,使用迭代。
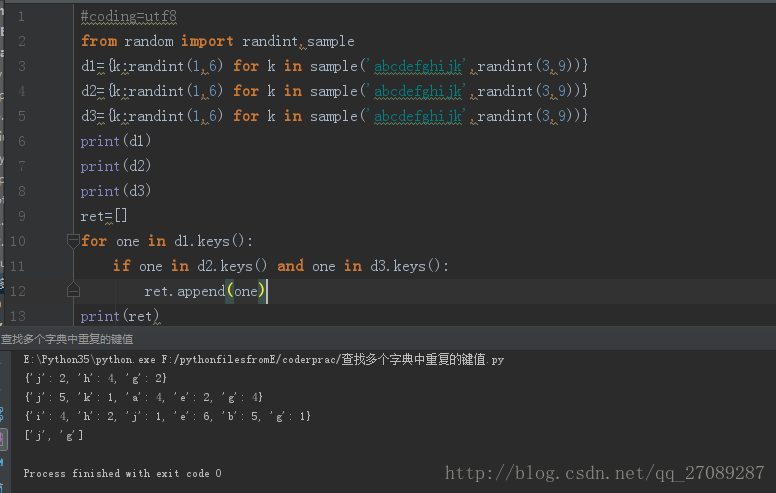
现在是使用循环迭代的方法,针对的是字典个数不多,但是当字典个数很多 及时几百的时候 也要挨个判断,这就不是很现实,输入也复杂,现在便引入几个方便的函数 使用集合的交集来操作。


map() 会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
reduce() 函数会对参数序列中元素进行累积。
函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给reduce中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。如
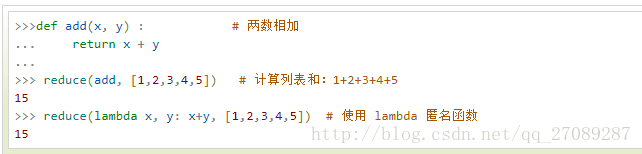
在这里例子中 使用reduce函数 #这里需要注意一个地方,使用的是3.5版本,reduce函数需要通过导入functools这个类来使用(from functools import reduce),直接使用reduce是不可以的 会报错:name 'reduce' is not defined
对取到的所有字典的键去交集。
reduce(lambda a,b:参数的运算方法,[所操作的序列])
reduce(lambda a,b:a&b,map[dict.keys,[d1,d2,d3]])
代码如下 :
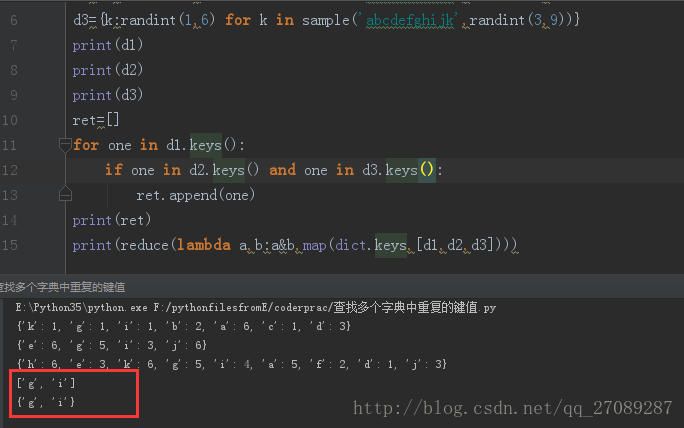
和使用迭代的方法是一样的 ,使用reduce和map的方法 适用于字典个数很多的情况。