一、如何安装配置apache的一个开源hadoop集群
-
使用root账户登录
-
修改IP
-
修改host主机名
-
配置SSH免密码登录
-
关闭防火墙
-
安装JDK并配置jdk环境变量
-
解压hadoop安装包
-
配置hadoop的核心文件
hadoop-env.sh,core-site.xml , mapred-site.xml , hdfs-site.xml ,yarn-site.xml ,slaves -
配置hadoop环境变量
-
格式化 hadoop namenode-format
二、HDFS存储机制
HDFS(Hadoop Distributed File System)是GFS的开源实现。
特点如下:
- 能够运行在廉价机器上,硬件出错常态,需要具备高容错性
- 流式数据访问,而不是随机读写
- 面向大规模数据集,能够进行批处理、能够横向扩展
- 简单一致性模型,假定文件是一次写入、多次读取
缺点:
- 不支持低延迟数据访问
- 不适合大量小文件存储(因为每条元数据占用空间是一定的)
- 不支持并发写入,一个文件只能有一个写入者
- 不支持文件随机修改,仅支持追加写入
HDFS中的block、packet、chunk
要把读写过程细节搞明白前,你必须知道block、packet与chunk。下面分别讲述。
-
block
这个大家应该知道,文件上传前需要分块,这个块就是block,一般为128MB,当然你可以去改,不顾不推荐。因为块太小:寻址时间占比过高。块太大:Map任务数太少,作业执行速度变慢。它是最大的一个单位。 -
packet
packet是第二大的单位,它是client端向DataNode,或DataNode的PipLine之间传数据的基本单位,默认64KB。 -
chunk
chunk是最小的单位,它是client向DataNode,或DataNode的PipLine之间进行数据校验的基本单位,默认512Byte,因为用作校验,故每个chunk需要带有4Byte的校验位。所以实际每个chunk写入packet的大小为516Byte。由此可见真实数据与校验值数据的比值约为128 : 1。(即64*1024 / 512)
例如,在client端向DataNode传数据的时候,HDFSOutputStream会有一个chunk buff,写满一个chunk后,会计算校验和并写入当前的chunk。之后再把带有校验和的chunk写入packet,当一个packet写满后,packet会进入dataQueue队列,其他的DataNode就是从这个dataQueue获取client端上传的数据并存储的。同时一个DataNode成功存储一个packet后之后会返回一个ack packet,放入ack Queue中。
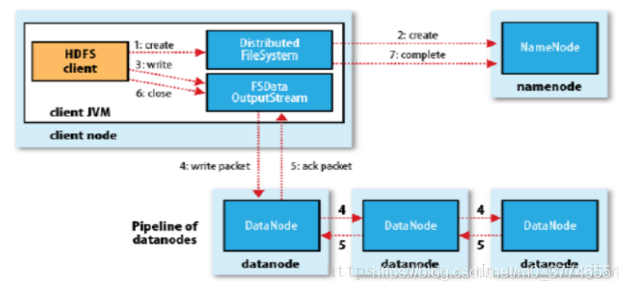
写流程(详细步骤)
-
客户端向NameNode发出写文件请求。
-
检查是否已存在文件、检查权限。若通过检查,直接先将操作写入EditLog,并返回输出流对象。
注:WAL,write ahead log,先写Log,再写内存,因为EditLog记录的是最新的 HDFS客户端执行所有的写操作。如果后续真实写操作失败了,由于在真实写操作之前,操 作就被写入EditLog中了,故EditLog中仍会有记录,我们不用担心后续client读不到相 应的数据块,因为在第5步中DataNode收到块后会有一返回确认信息,若没写成功,发送 端没收到确认信息,会一直重试,直到成功。 -
client端按128MB的块切分文件。
-
client将NameNode返回的分配的可写的DataNode列表和Data数据一同发送给最近的第一个DataNode节点,此后client端和NameNode分配的多个DataNode构成pipeline管道,client端向输出流对象中写数据。client每向第一个DataNode写入一个packet,这个packet便会直接在pipeline里传给第二个、第三个…DataNode。
注:并不是写好一个块或一整个文件后才向后分发 -
每个DataNode写完一个块后,会返回确认信息。
注:并不是每写完一个packet后就返回确认信息,packet中的每个chunk都携带校验信息,没必要每写一个就汇报一下,这样效率太慢。正确的做法是写完一个block块后,对校验信息进行汇总分析,就能得出是否有块写错的情况发生 -
写完数据,关闭输出流
-
发送完成信号给NameNode。
注:发送完成信号的时机取决于集群是强一致性还是最终一致性,强一致性则需要所有DataNode写完后才向NameNode汇报。最终一致性则其中任意一个DataNode写完后就能单独向NameNode汇报,HDFS一般情况下都是强调强一致性
读流程
步骤如下:
- client访问NameNode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。
- 就近挑选一台datanode服务器,请求建立输入流 。
- DataNode向输入流中中写数据,以packet为单位来校验。
- 关闭输入流

读写过程,数据完整性如何保持
通过校验和。因为每个chunk中都有一个校验位,一个个chunk构成packet,一个个
packet最终形成block,故可在block上求校验和。
HDFS 的client端即实现了对 HDFS 文件内容的校验和 (checksum) 检查。当客户端
创建一个新的HDFS文件时候,分块后会计算这个文件每个数据块的校验和,此校验和
会以一个隐藏文件形式保存在同一个 HDFS 命名空间下。
当client端从HDFS中读取文件内容后,它会检查分块时候计算出的校验和(隐藏文件里)
和读取到的文件块中校验和是否匹配,如果不匹配,客户端可以选择从其他 Datanode 获取
该数据块的副本。
HDFS中文件块目录结构具体格式如下:
${dfs.datanode.data.dir}/
├── current
│ ├── BP-526805057-127.0.0.1-1411980876842
│ │ └── current
│ │ ├── VERSION
│ │ ├── finalized
│ │ │ ├── blk_1073741825
│ │ │ ├── blk_1073741825_1001.meta
│ │ │ ├── blk_1073741826
│ │ │ └── blk_1073741826_1002.meta
│ │ └── rbw
│ └── VERSION
└── in_use.lock
in_use.lock表示DataNode正在对文件夹进行操作
rbw是“replica being written”的意思,该目录用于存储用户当前正在写入的数据。
block元数据文件(*.meta)由一个包含版本、类型信息的头文件和一系列校验值组成。校验和也正是存在其中。
三、mapreduce原理
MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点
管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单
地说,MapReduce就是"任务的分解与结果的汇总"。
在分布式计算中,MapReduce框架负责处理并行编程中分布式存储、工作调度、负
载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:
map和reduce,map负责把任务分解成多个任务,reduce负责把分解后多任务处理的结果
汇总起来。
需要注意的是,用MapReduce来处理的数据集(或任务)必须具备这样的特点:待处
理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。