1 导语
本来想沿着场景文本检测继续做场景文字识别,不过从现有的状况上看,学术数据库上都比较小,不足以支撑一个较为实用的识别算法的研究,所以想看看怎么能利用网络上未标注数据或者文档任务来辅助学习。其实这种在工业界是个非常普遍的问题。比如在无人驾驶或者机器人中,实际测试成本高,而且如果失败会产生很大风险,因此比较好的一种方式可能是先从模拟器中去学习,但是两者之间的数据肯定会有些出入。迁移学习关注的是怎么利用一个源任务(source task)来帮助我们更好地处理现有的目标任务(target task),源任务里面的数据称为源数据(source data),目标任务里的为 目标数据(target data)。迁移学习的出发点其实是很显然的,如果两个任务间有些共通性,那么这个共通性可以被利用,共通性体现在数据的共通性或者任务目标本身的共通性。 比如我们首先学了英语,然后再想学法语,学英语的过程中发现单词量特别重要,那么在学法语的时候我可能也需要特别注重单词量的积累。如果两者任务基本没什么联系,那么迁移也就没有多大意义,比如希望用本人博客的阅读量走势去帮助预测股市的走势。 当然,除了迁移学习外,也有很多其他相关但也非常务实的方向,比如[2]中的omni-supervised learning,或者怎么处理webvision这种有很多错误标注的数据库,这里不再介绍。
2 迁移学习
接下来主要参考李宏毅老师的讲解[1]来介绍迁移学,另外[7]这篇博客可能介绍的更加全面,大家有时间可以看看。[3]里面收集和总结了很多资料,供大家参考学习。先申明一下,本人现在还没入门,很多东西没有看全,所以有可能会有错误。
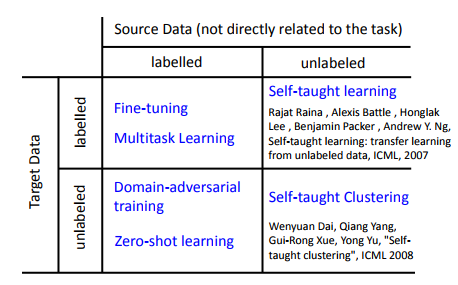
根据源数据和目标数据库有无标签我们可以把问题分成四个不同的象限,首先介绍最简单的:
2.1源数据有标签,目标数据也有标签
2.1.1特征提取
这种大家应该用的非常多。比如我们把在ImageNet上的训练好的VGG或ResNet的前五个stage的权重拷贝下来并固定住,后面只训练自己新加的全连接层。或者类似我的同事在做video caption的时候,把各个主流网络的特征提取出来,之后适当的处理后,直接送到lstm中学习。特征提取比较适合小数据量的情况,可以防止过拟合。
2.1.2 Fine-tuning
如果自己的数据够多,一般建议还是得微调,这也是现在学术上做检测和分割等任务常用的思路。骨架网络基本都是在imagenet上预训练,然后用一个小点的学习率微调。当然网络的不同层的可迁移能力是不一样的,比如某一层学习的都是人脸的高层特征,那么要它去做桌椅识别可能不是很合适。文献[4]就研究了Alex的各个层的迁移能力,总体来说底层的迁移能力比较好,因为学习到的是边缘之类的基础特征(这篇文章竟然是被NIPS接收的)。当然这也跟任务有关,比如在做声纹识别的时候,迁移的时候可能是高层。
2.1.3 multi-task learning
特征提取在新任务上并不是最优的,而finetuning在旧任务上不是最优的,如果我们希望综合考虑两种情况,在新旧任务上都能做的比较好,那么可能需要多任务学习,一种最简单的方法就是新加一个分支(head)去联合训练,一个成功的例子是做多语言的语音识别。如果任务之间相似度比较高,一般情况下这种方式的效果是最好的。
还有一种多任务学习思路[6]只需要老任务的训练模型,而不再需要老任务的数据了,它的出发点特别简单,初版被ECCV接收,后面又被TPRMI接收,我这破品位体会不了它的精髓。它用的还是联合训练那一套方案,但是既然没有了老任务的数据,那怎么还能保持在老任务的准确度呢?它的思路就是用老的模型去预测一下新输入数据的label,然后把这个预测的label做为ground truth,用在于新的联合训练任务中。

上面的两种情况都对两个任务的相似度有一定的要求。如果这种情况不成立呢,[5]提出了一种思路,见下图。感觉就是把老任务作为了一个特征提取的工具,再通过一个矩阵进行转化而已。不过个人感觉由于它的时间和存储都是线性增长,可能实用意义不是特别大。

当然这个类别之下还有很多其他的工作。
2.2 源数据有标签,目标数据没有标签
2.2.1domain adaption
如果我们有两个数据库,一个是MNIST,里面全是黑底白字的手写字;另外一个是在给mnist的样本随机加些彩色背景,但是为了研究我们暂时不给出他们的label,称之为MNIST-M,如下图。那在这种情况下,我们怎么训练一个模型能较好地在MINST-M下work呢。

估计大家想到的第一个比较naive的想法就是直接在MNIST下训练,然后直接在MNIST-M用,但是这样训练出来的网络,对两个不同数据库上的提取的特征分布是有一些出入的。见下图,蓝色部分就是MNIST的,有很明显的十团(cluster)对应十个不同的数字,而MINIST-M的分布却比较集中,挤在一块,说明网络区分他们的能力并不强。

那一个想法就提出来了,就是在训练的时候,尽量使两个数据库的特征分布一致。那怎么做呢,在文献[6]中提出了一种方法DAN,我们先看下大概思想。
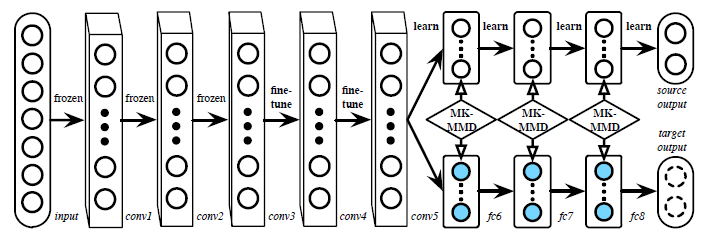
上面文章给出的图其实让人不是特别明白,建议大家有空还是直接看作者公开的网络架构。其实它的输入包含了两个部分,比如一个batchsize是128,那么64个样本来自源数据,另外64个来自目标数据。所有的数据都经过相同的5层网络后分离,源数据的特征再通过3个FC层进行分类训练,但是目标数据没有label,因此不能通过分类任务得到有效的损失,那作者想的就是在希望两个不同分支上fc6,fc7和fc8(代码中好像只看到了fc7和fc8)特征分布一致,用的是MK-MMD损失。因为现在两个分布基本一致了,测试的时候呢就用source那个分支就行了。 MK-MMD这部分的数学理论比较深,我目前也没理解,但是从代码上看不是特别难,希望后面能从代码角度看看它是怎么做的。
上面的方法是15年左右提出来,后面随着GAN的崛起,自然而然的就把GAN的思想引入进入了,因为如果网络不能区分样本来自source还是target,那是不是就意味在他们在特征层上的分布很难分呢,也就是他们的分布一致了。这个方向已经有了很多新的论文。

总体上domain adaption已经有了很多新的论文本人还没来的及看,但是从上面这两种来看,我觉得从思路上其实是有点问题的,不是非常有说服力。因为从任务目标上,最好地区分目标域的特征基本上不会跟原始域一致,如果强加一个这样的约束在这上面,必然会有性能的损失。
2.2.2 zero shot learning
这部分的论文我是一篇都没看过,所有只能依葫芦画瓢,照着视频上的给大家摘抄下来。
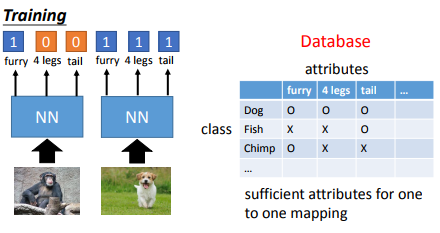
上面的domain adaption任务里面虽然两个任务的数据是不一致的,但是任务都是一致的。但是如果任务都不不一致怎么办呢,比如我们原始的数据库里有猫和狗,那目标任务是要你分辨一个没在原始数据出现的类别,比如说是草泥马,那要怎么做呢?

那一种做法是这样的,我们不再只是学习类别的标签,而是学习每个类别的属性,测试的时候通过属性来判断到底属于哪一类。当然我们并不需要跟下图一样建个显示的database,可以用wordembedding来代替,说不定最新的论文也有更好的解决方法,zero shot的论文还是挺多的。
2.3源数据没有标签
这个方向视频里基本没讲,有兴趣的同学只能自己看了。
参考文献
[1] https://www.youtube.com/watch?v=qD6iD4TFsdQ
[2] Radosavovic I, Dollár P,Girshick R, et al. Data Distillation: Towards Omni-Supervised Learning[J].arXiv preprint arXiv:1712.04440, 2017.
[3] https://github.com/jindongwang/transferlearning
[4] Yosinski J, Clune J, BengioY, et al. How transferable are features in deep neural networks?[C]//Advancesin neural information processing systems. 2014: 3320-3328.
[5] Rusu A A, Rabinowitz N C,Desjardins G, et al. Progressive neural networks[J]. arXiv preprintarXiv:1606.04671, 2016.
[6] Long M, Cao Y, Wang J, et al.Learning transferable features with deep adaptation networks[C]//InternationalConference on Machine Learning. 2015: 97-105.
[7] http://ruder.io/transfer-learning/