需要完整项目源码和论文报告可以私信我
机器学习大作业–基于机器学习算法、KNN、SVM、LSTM、决策树、随机森林、线性回归分析对空气质量的分类、识别和预测:
本文针对江西省南昌市2022年空气质量问题,采用各种机器学习算法实现其分类、知识、预测等。文中采用了基于SVM的图像分类或归类、深度学习模型LSTM、决策树、随机森林和线性回归分析等方法,对南昌市空气质量进行了研究和预测,并综合分析了各种算法的优缺点和适用性,为南昌市及相关决策部门提供了有效的参考建议。
(可以自行改地区,通过爬虫源码爬取其他地区空气质量数据集)
所有可视化结果以aqi指数为x轴,当天aqi排名为y轴,颜色代表空气质量。green, yellow, orange,red, purple,black分别代表优,良,轻度污染,中度污染,重度污染,严重污染。
1.获取数据
1.1数据来源:
http://www.tianqihoubao.com/aqi/nanchang-202201.html
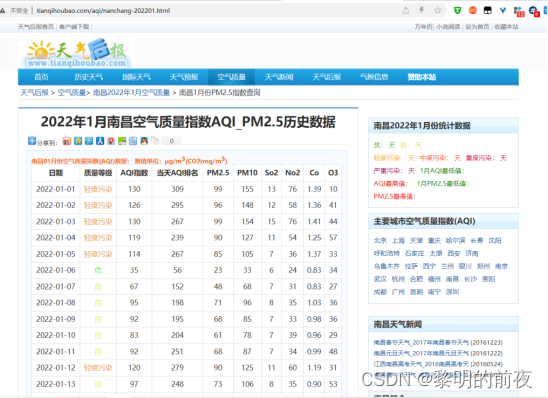
1.2爬虫源码:(完整源码见项目中:爬虫.py程序)
import pandas as pd
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
for page in range(1, 13): # 12个月
if page < 10:
url = f'http://www.tianqihoubao.com/aqi/nanchang-20220{page}.html'
df = pd.read_html(url, encoding='gbk')[0]
if page == 1:
df.to_csv('空气质量-nanchang_day.csv', mode='a+', index=False, header=False)
else:
df.iloc[1:, ::].to_csv('空气质量-nanchang_day.csv', mode='a+', index=False, header=False)
else:
url = f'http://www.tianqihoubao.com/aqi/nanchang-2022{page}.html'
df = pd.read_html(url, encoding='gbk')[0]
df.iloc[1:, ::].to_csv('空气质量-nanchang_day.csv', mode='a+', index=False, header=False)
logging.info(f'{page}月空气质量数据下载完成!')
1.3爬取数据:(数据集见空气质量-nanchang_day.csv文件)
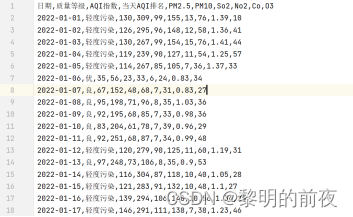
1.4数据预处理:(源码见test.py程序,处理后的数据见data.txt文件)

2.数据分析
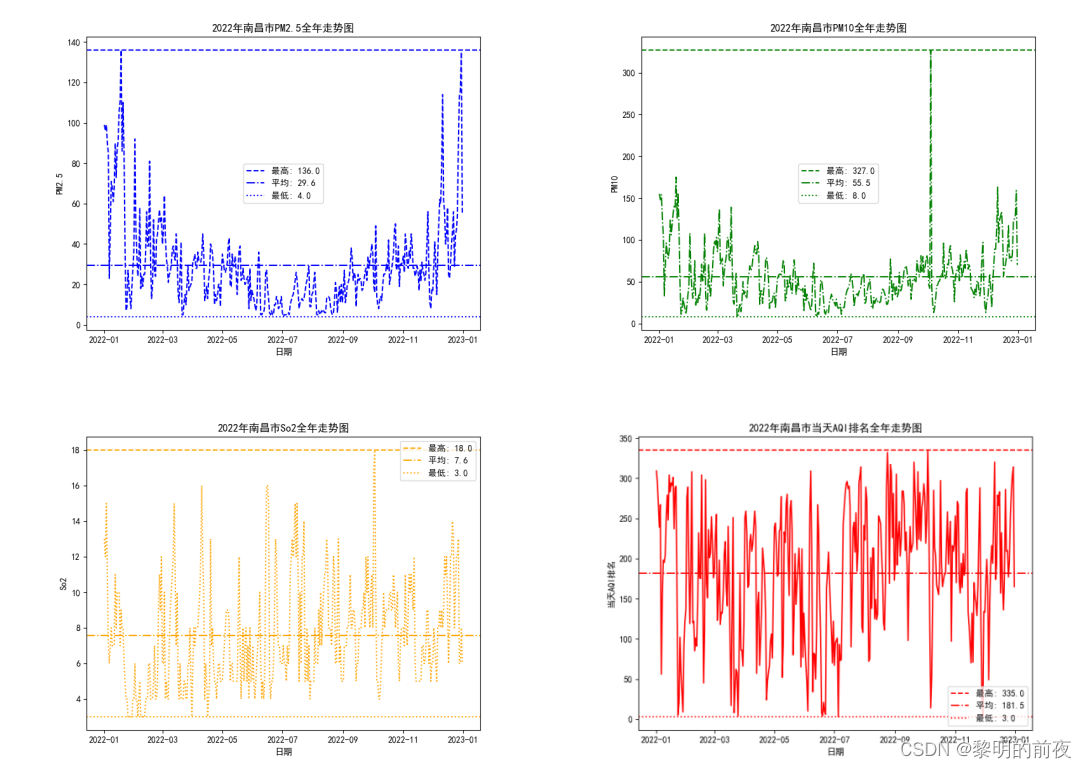
2.1.2022年南昌市空气质量分析中质量等级,AQI指数,当天AQI排名,PM2.5,PM10,So2,No2,Co,O3全年走势图:

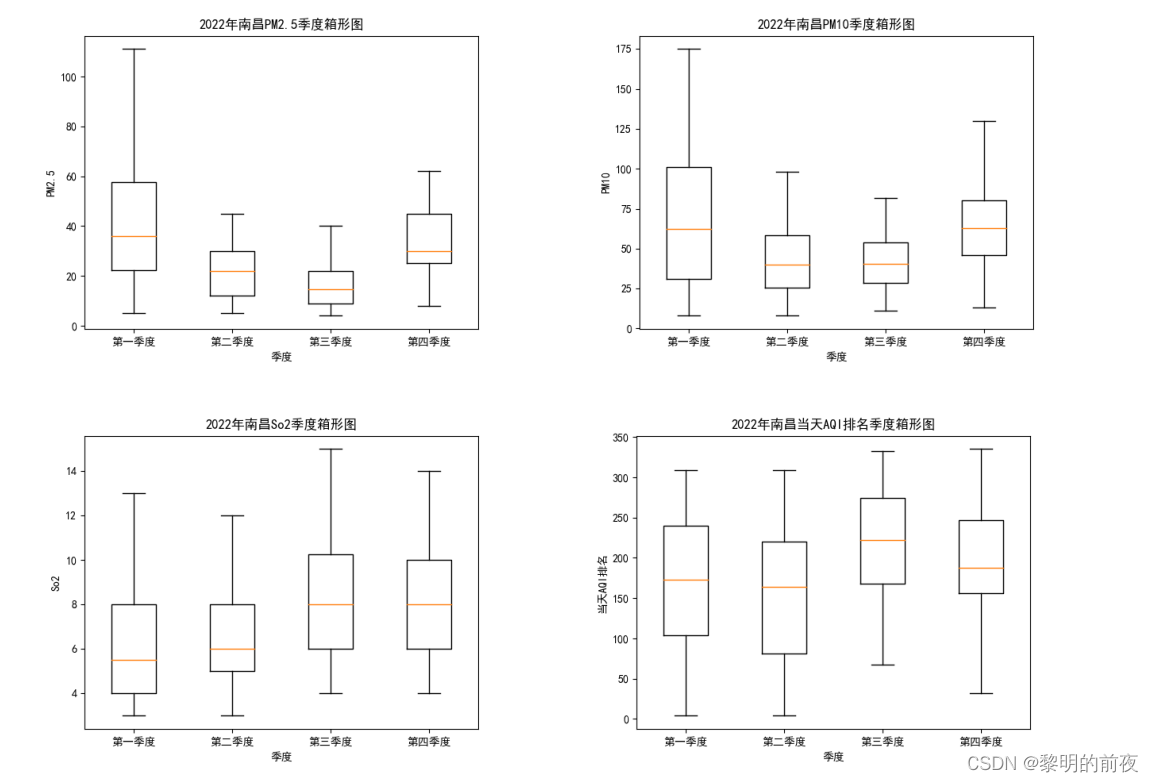
2.2.2022年南昌市空气质量分析中质量等级,AQI指数,当天AQI排名,PM2.5,PM10,So2,No2,Co,O3季度箱形图: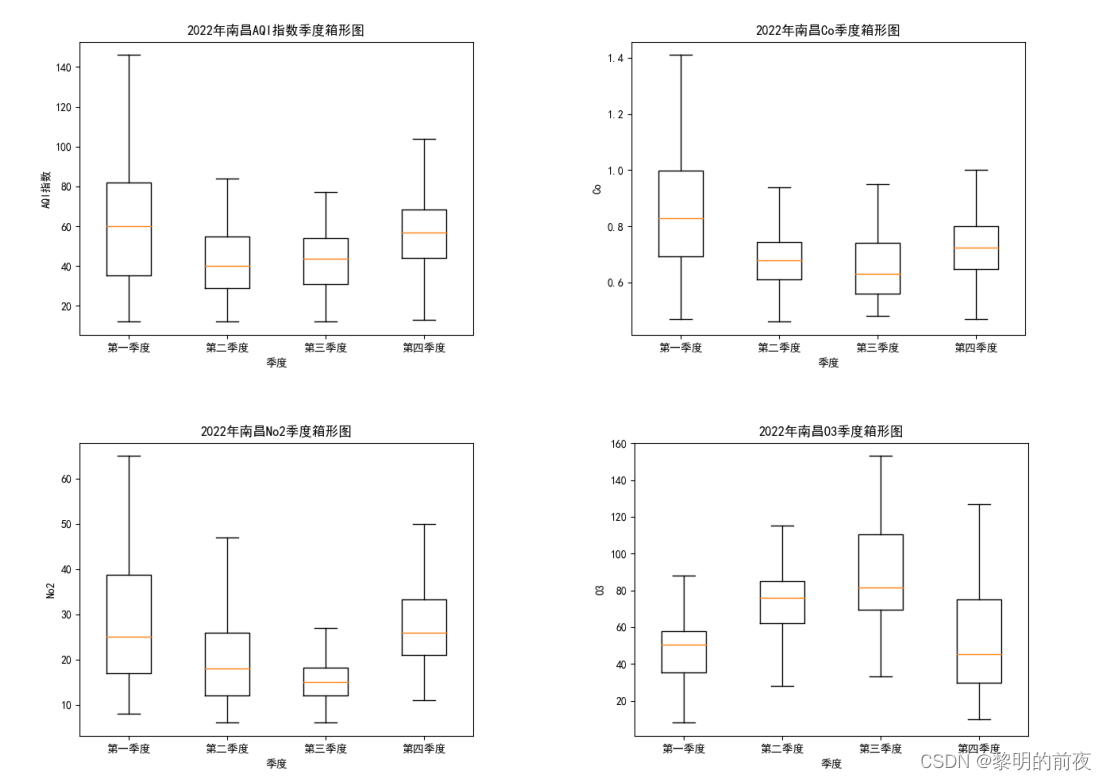
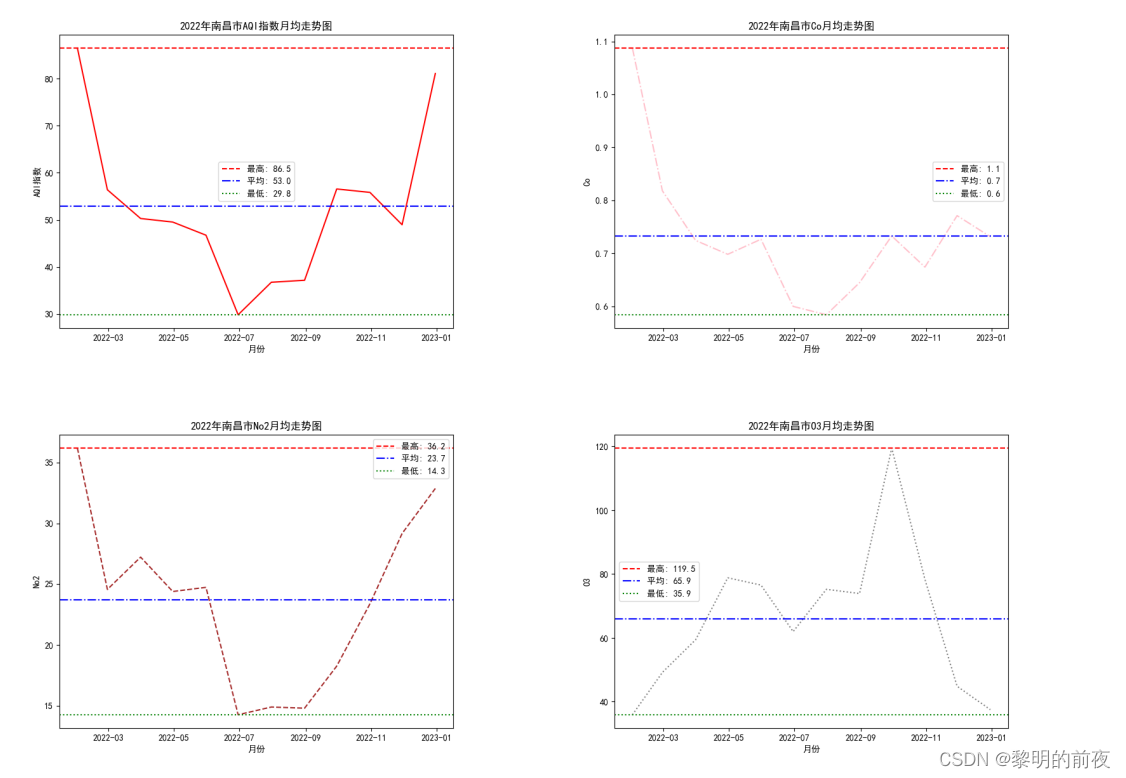
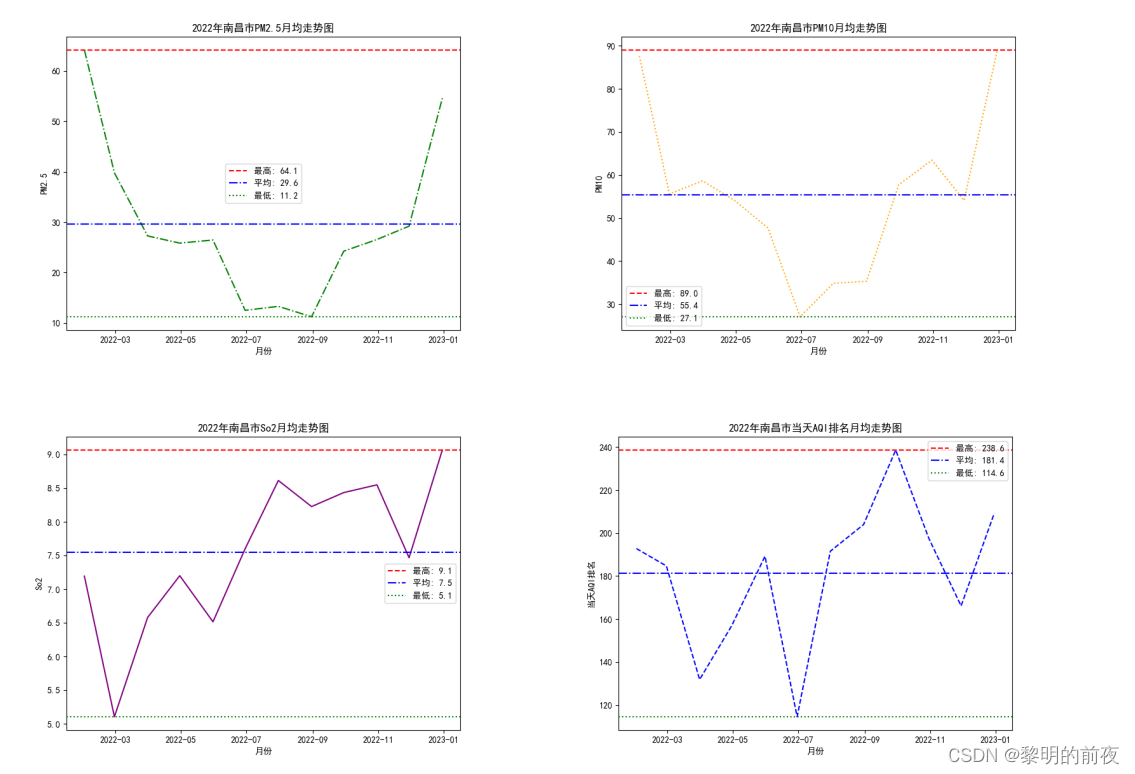
2.2.2022年南昌市空气质量分析中质量等级,AQI指数,当天AQI排名,PM2.5,PM10,So2,No2,Co,O3月均走势图:
3.实验结果
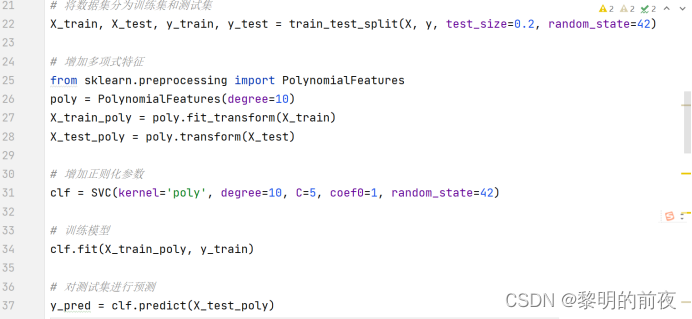
3.1基于SVM的图像分类、归类和预测
关键代码:(源码见SVM.py程序)
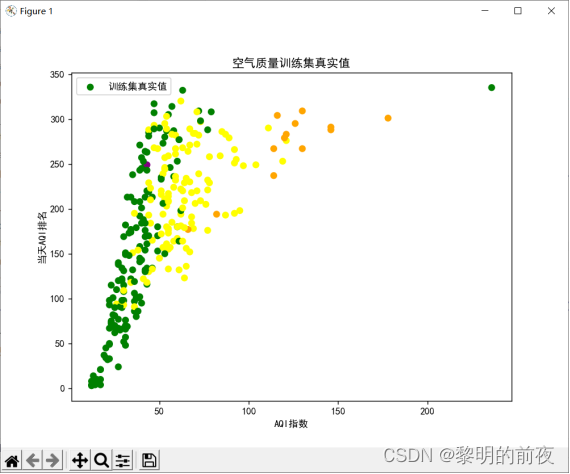
可视化训练集的真实值:
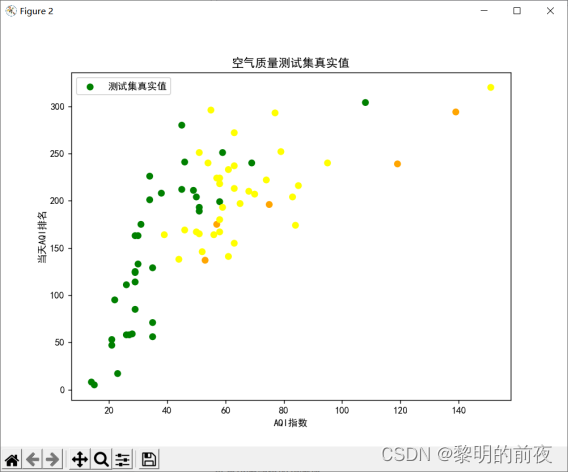
可视化测试集的真实值:
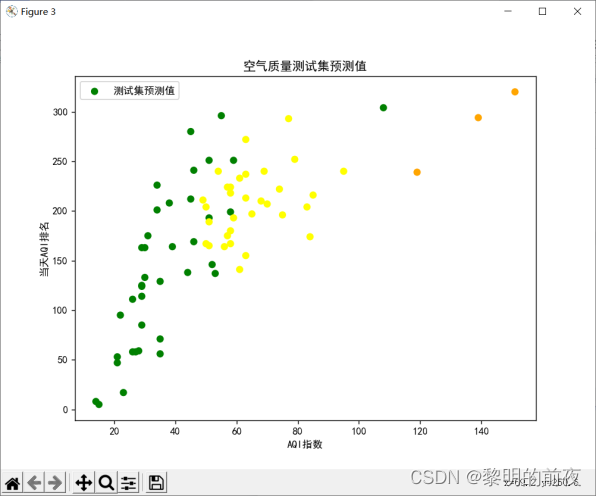
可视化测试集的预测值:
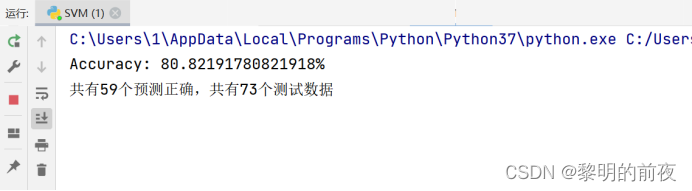
模型的准确率:
在支持向量机模型中, degree 控制多项式特征的次数,它的值越大,模型的复杂度就越高。另外, C 参数控制了模型对误分类的惩罚力度,它的值越小,模型就越容易出现过拟合的情况。将 degree 参数调为10 和 C 设置为5出现过拟合。
以下是模型过拟合实验对比结果:
可视化训练集的真实值:
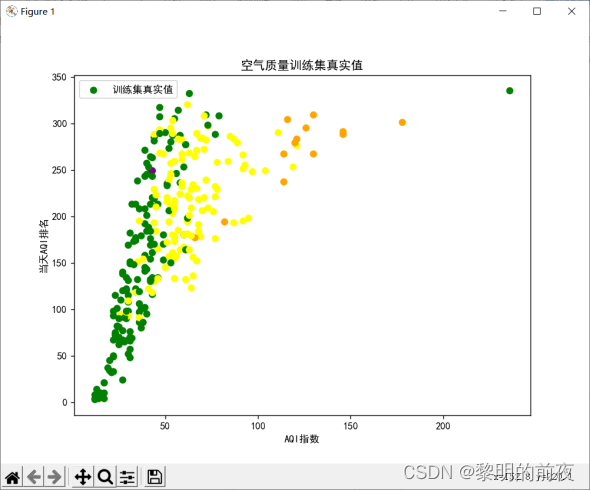
可视化测试集的真实值:
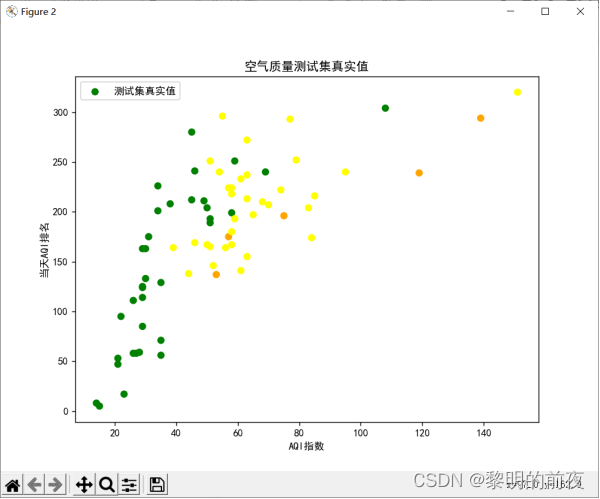
可视化测试集的预测值:
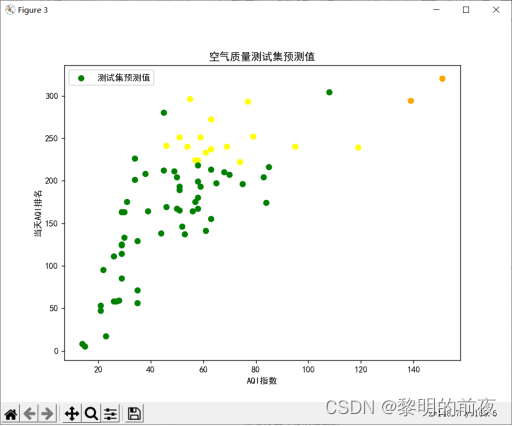
模型的准确率:
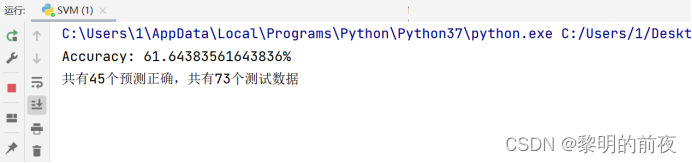
3.2深度学习模型LSTM
Lstm最优模型参数:(源代码见best_lstm.py程序)
3.3决策树
3.4随机森林
3.5 线性回归分析
3.6.KNN算法
内容太多不一一展示,需要完整项目源码和论文报告的可以私我。