本文代码等仅作学习记录使用
一、爬虫原理
网络爬虫指按照一定的规则(模拟人工登录网页的方式),自动抓取网络上的程序。简单的说,就是讲你上网所看到页面上的内容获取下来,并进行存储。网络爬虫的爬行策略分为深度优先和广度优先。
(1)、深度优先
深度优先搜索策略从起始网页开始,选择一个URL进入,分析这个网页中的URL,选择一个再进入。如此一个链接一个链接地抓取下去,直到处理完一条路线之后再处理下一条路线。深度优先策略设计较为简单。然而门户网站提供的链接往往最具价值,PageRank也很高,但每深入一层,网页价值和PageRank都会相应地有所下降。这暗示了重要网页通常距离种子较近,而过度深入抓取到的网页却价值很低。同时,这种策略抓取深度直接影响着抓取命中率以及抓取效率,对抓取深度是该种策略的关键。
(2)、广度优先:
广度优先搜索策略是指在抓取过程中,在完成当前层次的搜索后,才进行下一层次的搜索。该算法的设计和实现相对简单。在目前为覆盖尽可能多的网页,一般使用广度优先搜索方法。也有很多研究将广度优先搜索策略应用于聚焦爬虫中。其基本思想是认为与初始URL在一定链接距离内的网页具有主题相关性的概率很大。另外一种方法是将广度优先搜索与网页过滤技术结合使用,先用广度优先策略抓取网页,再将其中无关的网页过滤掉。这些方法的缺点在于,随着抓取网页的增多,大量的无关网页将被下载并过滤,算法的效率将变低。
二、抓取结构和规则
1.结构查看
本文主要介绍基础的抓取方式,以html格式为例
以当当网书籍页面为例,如图
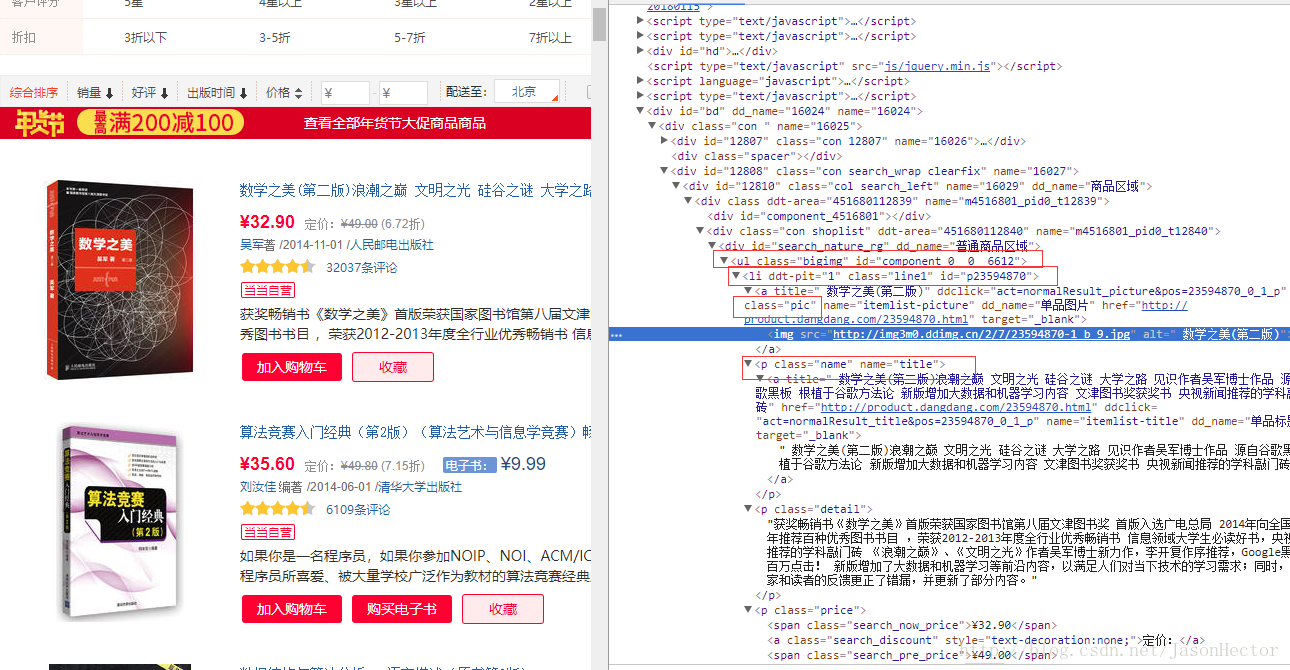
从图中可以看出 ,网页中的图书列表是一个以 ul 开始的 li标签遍历列表
我们需要的就是每个li标签中的数据,每个li标签相当于一个java中的对象。
2.html数据规则
从上图能看出每条数据外层都具备带有class [CSS样式]的标签,如下图
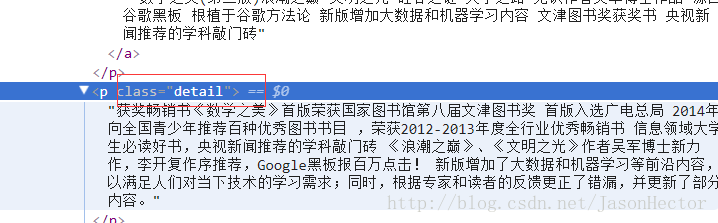
java 具有相对应的jar包来对html或xml数据结构进行解析,本文用的jar包为
三、代码实现
1.类展示
我用的springboot微框架 单纯抓取的话直接写main类就可以
(1)、model类
package com.weixin.model.book;
import com.weixin.model.BaseModel;
import org.apache.ibatis.type.Alias;
/**
* create by frank
* on 2018/01/25
* 书籍信息类
*/
@Alias("dangBook")//mybatis 数据类型绑定
public class DangBook extends BaseModel {
private String title;
private String img;
private String author;
private String publish;
private String detail;
private float price;
private String parentUrl;//父链接,即请求链接
public String getParentUrl() {
return parentUrl;
}
public void setParentUrl(String parentUrl) {
this.parentUrl = parentUrl;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getPublish() {
return publish;
}
public void setPublish(String publish) {
this.publish = publish;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getImg() {
return img;
}
public void setImg(String img) {
this.img = img;
}
public String getDetail() {
return detail;
}
public void setDetail(String detail) {
this.detail = detail;
}
public float getPrice() {
return price;
}
public void setPrice(float price) {
this.price = price;
}
}
附带公共类 BaseModel
package com.weixin.model;
import org.apache.ibatis.type.Alias;
import java.util.Date;
/**
* 基础类
* create by frank
* on 2017/12/18
*/
public class BaseModel {
private int id;
private Date inputTime;
public Date getInputTime() {
return inputTime;
}
public void setInputTime(Date inputTime) {
this.inputTime = inputTime;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
}
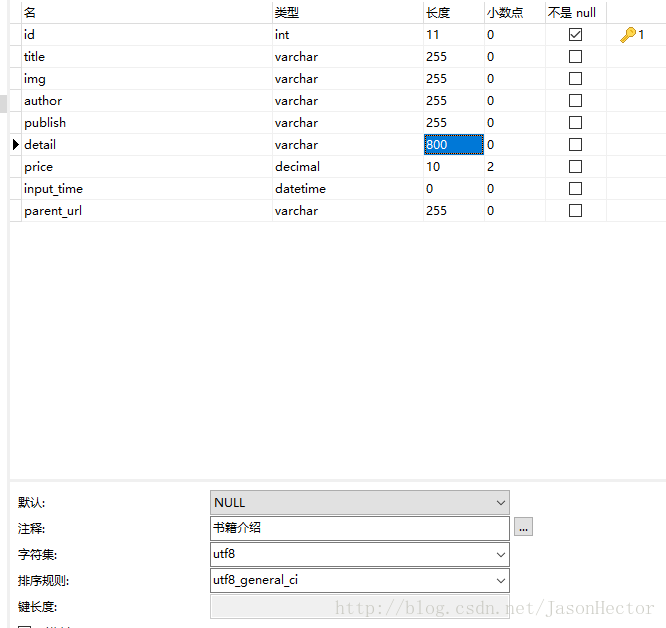
(2)、mapper 映射文件(dao、service类省略)附带数据库表格,如图
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="DangBook">
<insert id="insert" parameterType="dangBook">
INSERT INTO dd_book (title,img,author,publish,detail,price,input_time,parent_url)
VALUES
(#{title,jdbcType=VARCHAR},
#{img,jdbcType=VARCHAR},
#{author,jdbcType=VARCHAR},
#{publish,jdbcType=VARCHAR},
#{detail,jdbcType=VARCHAR},
#{price,jdbcType=NUMERIC},
#{inputTime,jdbcType=TIMESTAMP},
#{parentUrl,jdbcType=VARCHAR})
</insert>
</mapper>
(3)、链接请求工具类(根据url请求获取html文本)
注意import 为apache包
package utils;
import org.apache.http.HttpResponse;
import org.apache.http.HttpStatus;
import org.apache.http.HttpVersion;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.message.BasicHttpResponse;
import org.apache.http.util.EntityUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
/**
* http请求类
* create by frank
* on 2018/01/25
*/
public class HttpGetUtils {
private static Logger logger = LoggerFactory.getLogger(HttpGetUtils.class);
public static String getUrlContent(String url) {
if (url == null) {
logger.info("url地址为空");
return null;
}
logger.info("url为:" + url);
logger.info("开始解析");
String contentLine = null;
//最新版httpclient.jar已经舍弃new DefaultHttpClient()
//但是还是可以用的
HttpClient httpClient = new DefaultHttpClient();
HttpResponse httpResponse = getResp(httpClient, url);
if (httpResponse.getStatusLine().getStatusCode() == 200) {
try {
contentLine = EntityUtils.toString(httpResponse.getEntity(), "utf-8");
} catch (IOException e) {
e.printStackTrace();
}
}
logger.info("解析结束");
return contentLine;
}
/**
* 根据url 获取response对象
*
* @param httpClient
* @param url
* @return
*/
public static HttpResponse getResp(HttpClient httpClient, String url) {
logger.info("开始获取response对象");
HttpGet httpGet = new HttpGet(url);
HttpResponse httpResponse = new BasicHttpResponse(HttpVersion.HTTP_1_1, HttpStatus.SC_OK, "OK");
try {
httpResponse = httpClient.execute(httpGet);
} catch (IOException e) {
e.printStackTrace();
}
logger.info("获取对象结束");
return httpResponse;
}
}
(4)、解析类(解析html获取有用数据,重要类)
package utils;
import com.weixin.model.book.DangBook;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
/**
* 数据解析类 丁丁网图集
* create by frank
* on 2018/01/25
*/
public class ParseUtils {
private static Logger logger = LoggerFactory.getLogger(ParseUtils.class);
public static List<DangBook> dingParse(String url) {
List<DangBook> list = new ArrayList<>();
Date date = new Date();
if (url == null) {
logger.info("url为空,数据获取结束");
return null;
}
logger.info("开始获取数据");
String content = HttpGetUtils.getUrlContent(url);
if (content != null)
logger.info("得到解析数据");
else {
logger.info("解析数据为空,数据获取结束");
return null;
}
Document document = (Document) Jsoup.parse(content);
//遍历当当图书列表
for(int i =1;i<=60;i++){
Elements elements = document.select("ul[class=bigimg]").select("li[class=line"+i+"]");
for (Element e : elements) {
String title = e.select("p[class=name]").select("a").text();
logger.info("书名:" + title);
String img = e.select("a[class=pic]").select("img").attr("data-original");
logger.info("图片地址:" + img);
String authorAndPublish = e.select("p[class=search_book_author]").select("span").select("a").text();
String []a = authorAndPublish.split(" ");
String author = a[0];
logger.info("作者:" + author);
String publish = a[a.length - 1];
logger.info("出版社:" + publish);
// String publish =e.select("p[class=name]").select("a").text();
String detail = e.select("p[class=detail]").text();
logger.info("图书介绍:" + detail);
String priceS = e.select("p[class=price]").select("span[class=search_now_price]").text();
float price = Float.parseFloat(priceS.substring(1, priceS.length() - 1));
logger.info("价格:" + price);
logger.info("-------------------------------------------------------------------------");
DangBook dangBook = new DangBook();
dangBook.setTitle(title);
dangBook.setImg(img);
dangBook.setAuthor(author);
dangBook.setPublish(publish);
dangBook.setDetail(detail);
dangBook.setPrice(price);
dangBook.setInputTime(date);
dangBook.setParentUrl(url);
list.add(dangBook);
}
}
return list;
}
}
(5)、控制层类
package com.weixin.controller.book;
import com.alibaba.fastjson.JSONObject;
import com.weixin.model.book.DangBook;
import com.weixin.service.book.BookService;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import utils.ParseUtils;
import utils.Test;
import java.util.List;
@RestController
@RequestMapping("/book")
public class BookController {
@Autowired
private BookService bookService;
private static Logger logger = LoggerFactory.getLogger(Test.class);
@RequestMapping("/parse")
public JSONObject parse(String url){
JSONObject jsonObject = new JSONObject();
List<DangBook> dangBooks = ParseUtils.dingParse(url);
if(dangBooks != null && dangBooks.size() >0){
logger.info("解析完数据,准备入库");
bookService.insertBatch(dangBooks);
logger.info("入库完成,入库数据条数"+ dangBooks.size());
jsonObject.put("code",1);
jsonObject.put("result","success");
}else{
jsonObject.put("code",0);
jsonObject.put("result","fail");
}
return jsonObject;
}
}
以上就是完整的代码类
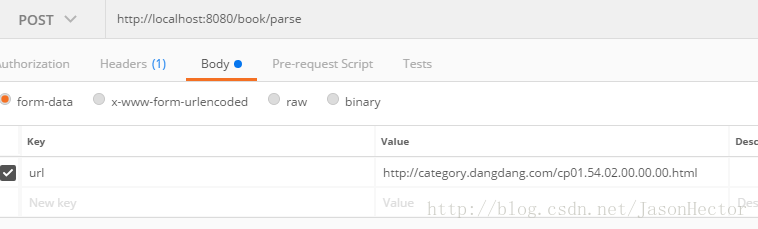
四、post man测试结果
1.请求方式 如图
2.控制台输出
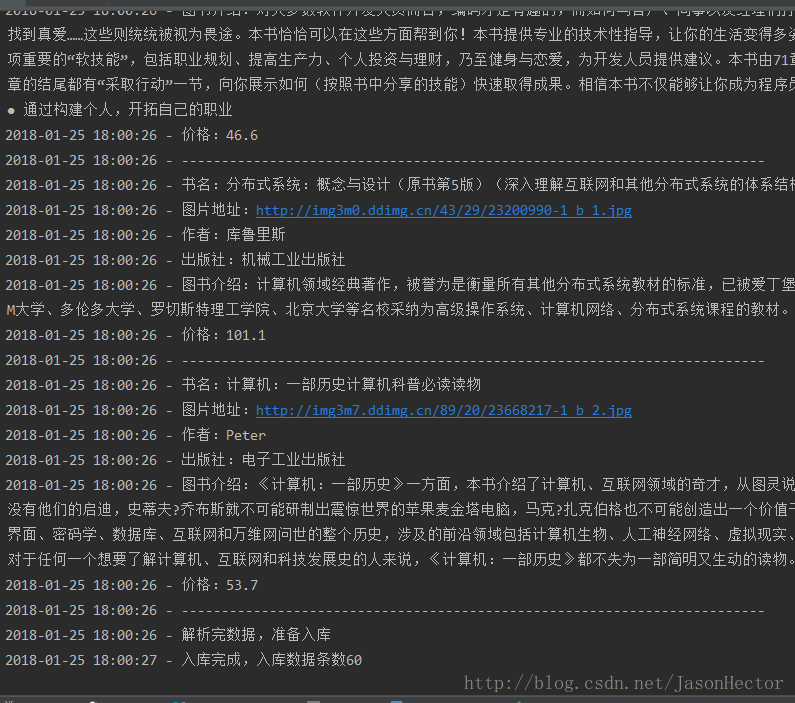
3、如上图所示,最后执行入库操作,查看数据库
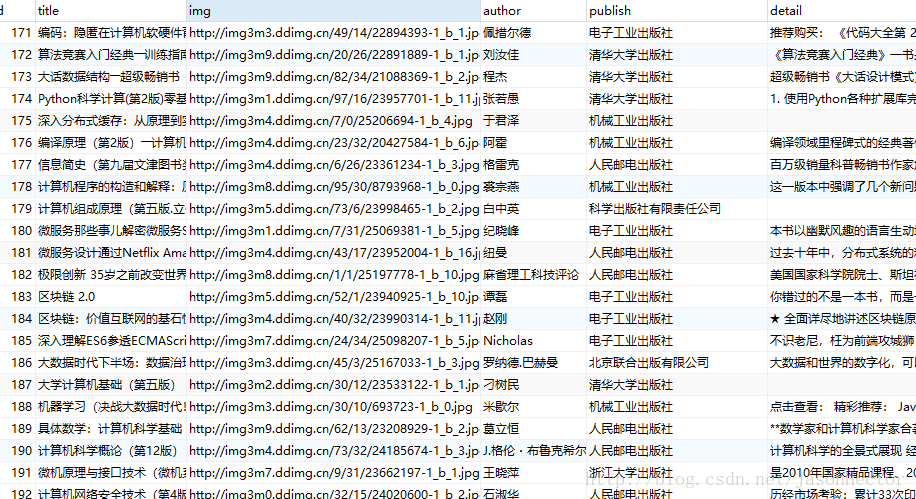
我代码中的解析作者和出版社那边代码有点小问题,导致解析部分没有获取到,这个具体就不改了,大体思路就是这样
这种就算是最基本的数据爬取了,再深入就涉及到正则表达式、队列、自动查询等比较复杂的操作
五、总结
(1)、上述操作主要注意请求代码和数据解析代码,特别是数据解析
(2)、不同网站有不同的数据逻辑和结构,基本上不同网站都有特定的一套爬虫规则
(3)、不少网站都设置反爬机制,想要得到更多数据还要进一步学习
(4)、虽然java有专门的封装好的jar包进行解析,但是最为开发人员还是要去了解他的实现原理,懂得了最基本的才是最重要的,而不是依赖现成的东西。