有向图的强连通分支
在有向图G中,如果任意两个不同的顶点相互可达,则称该有向图是强连通的。有向图G的极大强连通子图称为G的强连通分支。
把有向图分解为强连通分支是深度优先搜索的一个经典应用实例。下面介绍如何使用两个深度优先搜索过程来进行这种分解,很多有关有向图的算法都从分解步骤开始,这种分解可把原始的问题分成数个子问题,其中每个子子问题对应一个强连通分支。构造强连通分支之间的联系也就把子问题的解决方法联系在一起,我们可以用一种称之为分支图的图来表示这种构造。
定义有向图G=(V,E)的分支图为GSCC=(VSCC,ESCC),其中VSCC包含的每一个结点对应于G的每个强连通分支。如果图G的对应于节点u的强连通分支中,某个结点和对应于v的强连通分支中的某个结点之间存在一条有向边,则边(u,v)∈ESCC。图1给出了一个实例。显而易见对于分支图有以下定理:
有向图G的分支图GSCC是一个有向无回路图。
图1展示了一个有向图的强连通分支的实例。(a)为有向图G,其中的阴影部分是G的强连通分支,对每个顶点都标出了其发现时刻与完成时刻,黑色边为树枝;(b)G的转置图GT。图中说明了算法Strongly_Connected_Components第3行计算出的深度优先树,其中黑色边是树枝。每个强连通子图对应于一棵深度优先树。图中黑色顶点b,c,g和h是强连通子图中每个顶点的祖先,这些顶点也是对GT进行深度优先搜索所产生的深度优先树的树根。(c)把G的每个强连通子图缩减为单个顶点后所得到的有向无回路子图(即G的分支图)。
寻找图G=(V,E)的强连通分支的算法中使用了G的转置,其定义为:GT=(V,ET),其中ET={(v,u)∈V×V:(u,v)∈E},即ET由G中的边改变方向后组成。若已知图G的邻接表,则建立GT所需时间为O(V+E)。注意到下面的结论是很有趣的:G和GT有着完全相同的强连通支,即在G中u和v互为可达当且仅当在GT中它们互为可达。图1(b)即为图1(a)所示图的转置,其强连通支上涂了阴影。

图1 强连通子图的实例
下列运行时间为θ(V+E)的算法可得出有向图G=(V,E)的强连通分支,该算法使用了两次深度优先搜索,一次在图G上进行,另一次在图GT上进行。
procedure Strongly_Connected_Components(G);begin 1.调用DFS(G)以计算出每个结点u的完成时刻f[u]; 2.计算出GT; 3.调用DFS(GT),但在DFS的主循环里按针f[u]递减的顺序考虑各结点(和第一行中一样计算); 4.输出第3步中产生的深度优先森林中每棵树的结点,作为各自独立的强连通支。end;这一貌似简单的算法似乎和强连通支无关。下面我们将揭开这一设计思想的秘密并证明算法的证确性。我们将从两个有用的观察资料入手。
如果两个结点处于同一强连通支中,那么在它们之间不存在离开该连通支的通路。
证明:
设u和v是处于同一强连通支的两个结点,根据强连通支的定义,从u到v和从v到u皆有通路,设结点w在某一通路u→w→v上,所以从u可达w、又因为存在通路 v→u,所以可知从w通过路径w→v→u可达u,因此u和w在同一强连通支中。因为w是任意选定的,所以引理得证。
(证毕)
在任何深度优先搜索中,同一强连通支内的所有顶点均在同一棵深度优先树中。
证明:
在强连通支内的所有结点中,设r第一个被发现。因为r是第一个被发现,所以发现r时强连通支内的其他结点都为白色。在强连通支内从r到每一其他结点均有通路,因为这些通路都没有离开该强连通支(据引理1),所以其上所有结点均为白色。因此根据白色路径定理,在深度优先树中,强连通支内的每一个结点都是结点r的后裔。
(证毕)
在下文中,记号d[u]和f[u]分别指由算法Strongly_Connected_Components第1行的深度优先搜索计算出的发现和完成时刻。类似地,符号u→v是指G中而不是GT中存在的一条通路。
为了证明算法Strongly_Connected_Components的正确性,我们引进符号Φ(u)表示结点u的祖宗w,它是根据算法第1行的深度优先搜索中最后完成的从u可达的结点(注意,与深度优先树中祖先的概念不同)。换句话说,Φ(u)是满足u→w且f[w]有最大值的结点w。
注意有可能Φ(u)=u,因为u对其自身当然可达,所以有
我们同样可以通过以下推理证明Φ(Φ(u))=Φ(u),对任意结点u,v∈V,
因为{w|v→w}包含于{w|u→w},且祖宗结点是所有可达结点中具有最大完成时刻的结点。又因为从u可达结点Φ(u),所以(2)式表明订f[Φ(Φ(u))]≤f[Φ(u)],用Φ(u)代入(1)式中的u同样有f[Φ(u)]≤f[Φ(Φ(u))],这样f[Φ(Φ(u))]=f[Φ(u)]成立。所以有Φ(Φ(u))=Φ(u),因为若两结点有同样的完成时刻,则实际上两结点为同一结点。
我们将发现每个强连通分支中都有一结点是其中每一结点的祖宗,该结点称为相应强连通分支的“代表性结点”。在对图G进行的深度优先搜索中,它是强连通支中最先发现且最后完成的结点。在对GT的深度优先搜索中,它是深度优先树的树根,我们现在来证明这一性质。
第一个定理中称Φ(u)是u的祖先结点。
已知有向图G=(V,E),在对G的深度优先搜索中,对任意结点u∈V,其祖宗Φ(u)是u的祖先。
证明:
如果Φ(u)=u,定理自然成立。如果Φ(u)≠u,我们来考虑在时刻d[u]各结点的颜色,若Φ(u)是黑色,则f[Φ(u)]<f[u],这与不等式(1)矛盾;若Φ(u)为灰色,则它是结点u的祖先,从而定理可以得证。
现在只要证明Φ(u)不是白色即可,在从u到Φ(u)的通路中若存在中间结点,则根据其颜色可分两种情况:
- 若每一中间结点均为白色,那么由白色路径定理知Φ(u)是u的后裔,则有f[Φ(u)]<f[u],这与不等式(1)相矛盾。
- 若有某个中间结点不是白色,设t是从u到Φ(u)的通路上最后一个非非白节点,则由于不可能有从黑色结点到白色结点的边存在,所以t必是灰色。这样就存在一条从t到Φ(u)且由白色结点组成的通路,因此根据白色路径定理可推知Φ(u)是t的后裔,这表明f[t]>f[Φ(u)]成立,但从u到t有通路,这巧我们对Φ(u)的选择相矛盾。
(证毕)
推论1
在对有向图G=(V,E)的任何深度优先搜索中,对所有u∈V,结点u和Φ(u)处于同一个强连通分支内。
证明:
由对祖宗的定义有u→Φ(u),同时因为Φ(u)是u的祖先,所以又有Φ(u)→u。
(证毕)
下面的定理给出了一个关于祖宗和强连通分支之间联系的更强有力的结论。
在有向图G=(V,E)中,两个结点u,v∈V处于同一强连通分支当且仅当对G进行深度优先搜索时两结点具有同一祖宗。
证明:
→:假设u和v处于同一强连通分支内,从u可达的每个结点也满足从v可达,反之亦然。这是由于在 u和 v之间存在双向通路,由祖宗的定义我们可以推知Φ(u)=Φ(v)。
←:假设Φ(u)=Φ(v)成立,根据推论1,u和Φ(u)在同一强连通分支内且v和Φ(v)也处于同一强连通分支内,因此u和v也在同一强连通支中。
(证毕)
有了定理4,算法Strongly_Connected_Components的结构就容易掌握了。强连通分支就是有着同一组总的节点的集合。再根据定理3和括号定理可知,在算法第1行所述的深度优先搜索中,祖宗是其所在强连通分支中第一个发现最后一个完成的结点。
为了弄清楚为什么在算法Strongly_Connected_Components的第3行要对GT进行深度优先搜索,我们考察算法的第1行的深度优先搜索所计算出的具有最大完成时刻的结点r。根据祖宗的定义可知结点r必为一祖宗结点,这是因为它是自身的祖宗:它可以到达自身且图中其他结点的完成时刻均小于它。在r的强连通分支中还有其他哪些节点?它们是那些以F为祖宗的结点——指可达r但不可达任何完成时刻大于f[r]的结点的那些结点。但由于在G中r是完成时刻最大的结点,所以r的强连通分支仅由那些可达r的结点组成。换句话说,r的强连通支由那些在GT中从r可达的顶点组成。在算法第3行的深度优先搜索识别出所有属于r强连通支的结点,并把它们置为黑色(宽度优先搜索或任何对可达结点的搜索可以同样容易地做到这一点)。
在执行完第3行的深度优先搜索并识别出r的强连通分支以后,算法又从不属于r强连通分支且有着最大完成时刻的任何结点r'重新开始搜索。结点,r'必为其自身的祖宗,因为由它不可能达到任何完成时刻大于它的其他结点(否则r'将包含于r的强连通分支中)。根据类似的推理,可达r'且不为黑色的任何结点必属于r'的强连通分支,因而在第3行的深度优先搜索继续进行时,通过在GT中从r'开始搜索可以识别出属于r'的强连通分支的每个结点并将其置为黑色。
因此通过第3行的深度优先搜索可以对图“层层剥皮”,逐个取得图的强连通分支。把每个强连通分支的祖宗作为自变量调用DFS_Visit过程,我们就可在过程DFS的第7行识别出每一支。DFS_Visit过程中的递归调用最终使支内每个结点都成为黑色。当DFS_Visit返回到DFS中时,整个支的结点都变成黑色且被“剥离”,接着DFS在那些非黑色结点中寻找具有最大完成时刻的结点并把该结点作为另一支的祖宗继续上述过程。
下面的定理形式化了以上的论证。
过程Strongly_Connected_Components(G)可正确计算出有向图G的强连通分支。
证明:
通过对在GT上进行深度优先搜索中发现的深度优先树的数目进行归纳,可以证明每棵树中的结点都形成一强连通分支。归纳论证的每一步骤都证明对GT进行深度优先搜索形成的树是一强连通分支,假定所有在先生成的树都是强连通分支。归纳的基础是显而易见的,这是因为产生第一棵树之前无其他树,因而假设自然成立。
考察对GT进行深度优先搜索所产生的根为r的一棵深度优先树T,设C(r)表示r为祖宗的所有结点的集合:
C(r)={v∈V|Φ(v)=r}
现往我们来证明结点u被放在树T中当且仅当u∈C(r)。
→:由定理2可知C(r)中的每一个结点都终止于同一棵深度优先树。因为r∈C(r)且r是T的根,所以C(r)中的每个元素皆终止于T。
←:通过对两种情形f[Φ(w)]>f[r]或f[Φ(w)]<f[r]分别考虑,我们来证明这样的结点w不在树T中。通过对已发现树的数目进行归纳可知满足f[Φ(w)]>f[r]的任何结点w不在树T中,这是由于在选择到r时,w已经被放在根为Φ(w)的树中。满足f[Φ(w)]<f[r]的任意结点w也不可能在树T中,这是因为若w被放入T中,则有w→r:因此根据式(2)和性质r=Φ(r),可得f[Φ(w)]≥f[Φ(r)]=f[r],这和f[Φ(w)]<f[r]相矛盾。
这样树T仅包含那些满足Φ(u)=r的结点u,即T实际上就是强连通支C(r),这样就完成了归纳证明。
一、 Kosaraju算法
1. 算法思路
2. 伪代码
3. 实现代码
编辑本段二、 Tarjan算法
1. 算法思路
2. 伪代码
3. 实现代码
编辑本段三、 Gabow算法
1. 思路分析
2. 伪代码
3. 实现代码
编辑本段四、 总结
本节内容将详细讨论有向图的强连通分支算法(strongly connected component),该算法是图深度优先搜索算法的另一重要应用。强分支算法可以将一个大图分解成多个连通分支,某些有向图算法可以分别在各个联通分支上独立运行,最后再根据分支之间的关系将所有的解组合起来。
在无向图中,如果顶点s到t有一条路径,则可以知道从t到s也有一条路径;在有向无环图中个,如果顶点s到t有一条有向路径,则可以知道从t到s必定没有一条有向路径;对于一般有向图,如果顶点s到t有一条有向路径,但是无法确定从t到s是否有一条有向路径。可以借助强连通分支来研究一般有向图中顶点之间的互达性。
有向图G=(V, E)的一个强连通分支就是一个最大的顶点子集C,对于C中每对顶点(s, t),有s和t是强连通的,并且t和 s也是强连通的,即顶点s和t是互达的。图中给出了强连通分支的例子。我们将分别讨论3种有向图中寻找强连通分支的算法。
3种算法分别为Kosaraju算法、Tarjan算法和Gabow算法,它们都可以在线性时间内找到图的强连通分支。
Kosaraju算法
Kosaraju算法的解释和实现都比较简单,为了找到强连通分支,首先对图G运行DFS,计算出各顶点完成搜索的时间f;然后计算图的逆图GT,对逆图也进行DFS搜索,但是这里搜索时顶点的访问次序不是按照顶点标号的大小,而是按照各顶点f值由大到小的顺序;逆图DFS所得到的森林即对应连通区域。具体流程如图(1~4)。
上面我们提及原图G的逆图GT,其定义为GT=(V, ET),ET={(u, v):(v, u)∈E}}。也就是说GT是由G中的边反向所组成的,通常也称之为图G的转置。在这里值得一提的是,逆图GT和原图G有着完全相同的连通分支,也就说,如果顶点s和t在G中是互达的,当且仅当s和t在GT中也是互达的。
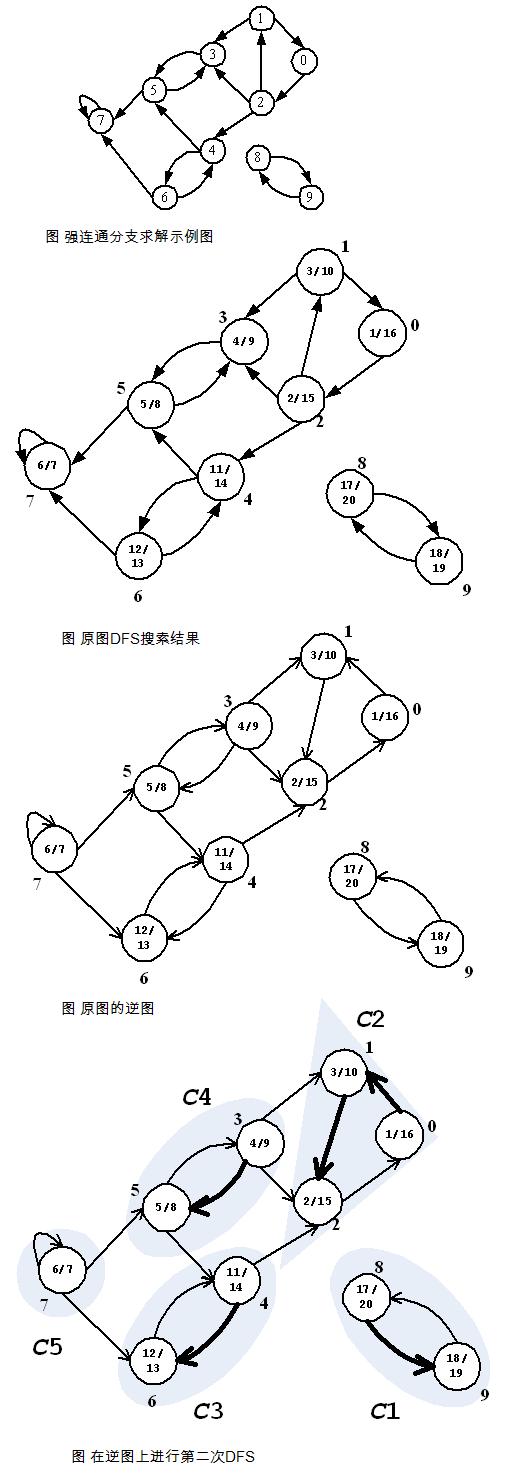
根据上面对Kosaraju算法的讨论,其实现如下:

* 算法1:Kosaraju,算法步骤:
* 1. 对原始图G进行DFS,获得各节点的遍历次序ord[];
* 2. 创建原始图的反向图GT;
* 3. 按照ord[]相反的顺序访问GT中每个节点;
* @param G 原图
* @return 函数最终返回一个二维单链表slk,单链表
* 每个节点又是一个单链表, 每个节点处的单链表表示
* 一个联通区域;slk的长度代表了图中联通区域的个数。
*/
public static SingleLink2 Kosaraju(GraphLnk G){
SingleLink2 slk = new SingleLink2();
int ord[] = new int[G.get_nv()];
// 对原图进行深度优先搜索
GraphSearch.DFS(G);
// 拷贝图G的深度优先遍历时每个节点的离开时间
for( int i = 0; i < GraphSearch.f.length; i++){
ord[i] = GraphSearch.f[i];
System.out.print(GraphSearch.parent[i] + " || ");
}
System.out.println();
// 构造G的反向图GT
GraphLnk GT = Utilities.reverseGraph(G);
/* 用针对Kosaraju算法而设计DFS算法KosarajuDFS函数
* 该函数按照ord的逆向顺序访问每个节点,
* 并向slk中添加新的链表元素; */
GraphSearch.KosarajuDFS(GT, ord, slk);
// 打印所有的联通区域
for(slk.goFirst(); slk.getCurrVal()!= null; slk.next()){
// 获取一个链表元素项,即一个联通区域
GNodeSingleLink comp_i =
(GNodeSingleLink)(slk.getCurrVal().elem);
// 打印这个联通区域的每个图节点
for(comp_i.goFirst();
comp_i.getCurrVal() != null; comp_i.next()){
System.out.print(comp_i.getCurrVal().elem + "\t");
}
System.out.println();
}
// 返回联通区域链表
return slk;
}
算法首先对原图进行DFS搜索,并记录每个顶点的搜索离开时间ord;然后调用Utilities类中的求逆图函数reverseGraph,求得原图的逆图GT;最后调用GraphSearch类的递归函数KosarajuDFS,该函数按照各顶点的ord时间对图进行深度优先搜索。函数最终返回一个二维单链表slk,单链表每个节点的元素项也是一个单链表,每个节点处的单链表表示一个联通区域,如图,slk的长度代表了图中联通区域的个数。之所以使用这样的数据结构作为函数的结果,其原因是在函数返回之前无法知道图中共有多少个强连通分支,也不知道每个分支的顶点的个数,二维链表自然成为最优的选择。其余两个算法的返回结果也采用这种形式的链表输出结果。
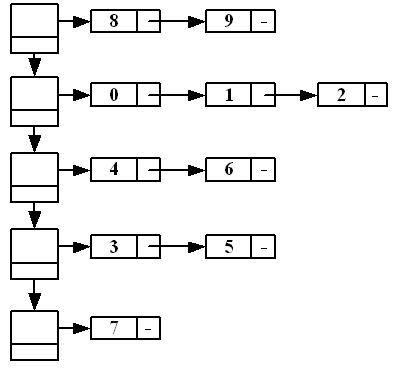
图 Kosaraju算法返回的二维链表形式结果
reverseGraph函数返回的逆图是新创建的图,其每条边都与原图边的方向相反。原图中一个顶点对应的链表中的相邻顶点是按照标号由小到大的顺序排列的,这样做能提高相关算法的效率(例如isEdge(int, int)函数)。这里在计算逆图时这个条件也必须满足。该静态函数的实现如下:
* 创建一个与入参G每条边方向相反的图,即逆图。
* @param G 原始图
* @return 逆图
*/
public static GraphLnk reverseGraph(GraphLnk G){
GraphLnk GT = new GraphLnk(G.get_nv());
for( int i = 0; i < G.get_nv(); i++){
// GT每条边的方向与G的方向相反
for(Edge w = G.firstEdge(i); G.isEdge(w);
w = G.nextEdge(w)) {
GT.setEdgeWt(w.get_v2(), w.get_v1(),
G.getEdgeWt(w));
}
}
return GT;
}
函数中对顶点按照标号由小到大进行遍历,对顶点i,再遍历其对应链表中的顶点i0, …, in,并向逆图中添加边(i0, i), …, (in, i),最终得到原图的逆图GT。可以发现,函数中调用setEdgeWt函数来向GT中添加边。细心的读者可能还记得,若待修改权值的边不存在时,函数setEdgeWt充当添加边的功能,并且能保证相邻的所有顶点的标号在链表中按由小到大的顺序排列。
Kosaraju实现中关键的一步是调用KosarajuDFS函数对逆图GT进行递归深度优先搜索。函数的另外两个形参为原图DFS所得的各顶点搜索结束时间ord,和保存连通分支结果的链表slk。KosarajuDFS的实现如下:
* 将根据逆图GT和每个节点在原图G深度遍历时的离开时间数组,
* 生成链表slk表示的连通分支
* 本函数不改变图的连接关系,只是节点的访问次序有所调整.
* @param GT 逆图
* @param ord 原图DFS各顶点遍历离开时间数组
* @param slk 连通分支存放在链表中
*/
public static&n
再分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到我们人工智能的队伍中来!https://blog.csdn.net/jiangjunshow