热身题
服务器正在运转着,也不知道这个技术可不可用,万一服务器被弄崩了,那损失可不小。
所以, 决定在虚拟机上试验一下,不小心弄坏了也没关系。需要在的电脑上装上虚拟机和linux系统
安装虚拟机(可参考Vmware、Virtual Box等)
安装ubuntu系统(推荐安装16.04版本)
写一个helloworld程序,在ubuntu系统上编译运行
(你可能需要了解linux系统的终端和一些基本命令、文本编辑工具nano、如何编译代码、运行程序)
- 1.安装虚拟机Vmware:在官网下载页面选择workstation pro,下载并安装。

运行workstation pro节目如下
- 2.安装Ubuntu系统
安装系统,以及配置c、c++编译器主要参考了以下两篇博文:
win10安装内置Ubuntu系统
Windows10内置Ubutnu配置C/C++编译环境 - 3.在VMware上创建Ubuntu虚拟机主要参考了Vmware虚拟机安装Ubuntu 16.04 LTS(长期支持)版本+VMware tools安装
- 4.在Ubuntu系统上编译运行hello world程序
- 先在桌面添加名为1.cpp的helloworld程序
- 在Ubuntu系统上运行

基本题
了解新技术
众多sketch的技术中,Count-min sketch 常用也并不复杂,但你可能需要稍微了解一点点散列的知识。从它入手不失为一个好选择,把它记录在你的技术博客上:
- 1.简单描述什么是sketch
- sketch是基于哈希的数据结构,通过合理设置哈希函数(也称散列函数),在将数据进行哈希运算后(可能包含多次哈希运算,即多重哈希,目的是提高精确度),将具有相同哈希值的键值数据存入相同的特定区域内,以减少空间开销。将各个区域内的数据值作为测量结果,存在一定的误差,但可以使用各种方式减小误差。
- 2.描述Count-min sketch的算法过程
- 摘自维基百科:In computing, the count–min sketch (CM sketch) is a probabilistic data structure that serves as a frequency table of events in a stream of data. It uses hash functions to map events to frequencies, but unlike a hash table uses only sub-linear space, at the expense of overcounting some events due to collisions.( 在计算中,count-min sketch(CM sketch)是一种概率数据结构,用作数据流中事件的频率表。它使用散列函数将事件映射到频率,但不像散列表仅使用子线性空间,代价是由于冲突导致一些事件过度计数。)
- 目的:统计一个实时的数据流中元素出现的频率,并且准备随时回答某个元素出现的频率,不需要的精确的计数。
- 技巧:因为储存所有元素的话太耗费内存空间,所有不存储所有的不同的元素,只存储它们Sketch的计数。
- 实现大致过程:
- 建立一个1~x的数组,作为储存计数的载体。
- 对于一个新元素,哈希到0~x中的一个数x0,作为该元素的数组索引。
- 查询元素出现频率时,返回元素对于数组索引中储存的数即可。
实现新技术(30')
大致了解了Count-min sketch,接下来就需要实现它了。本着不需要重复造轮子的思想,你上github一查,果然发现了相关代码。
并不需要深刻理解代码,你只需要会用,你的目标是在虚拟机上跑通Count-min sketch:
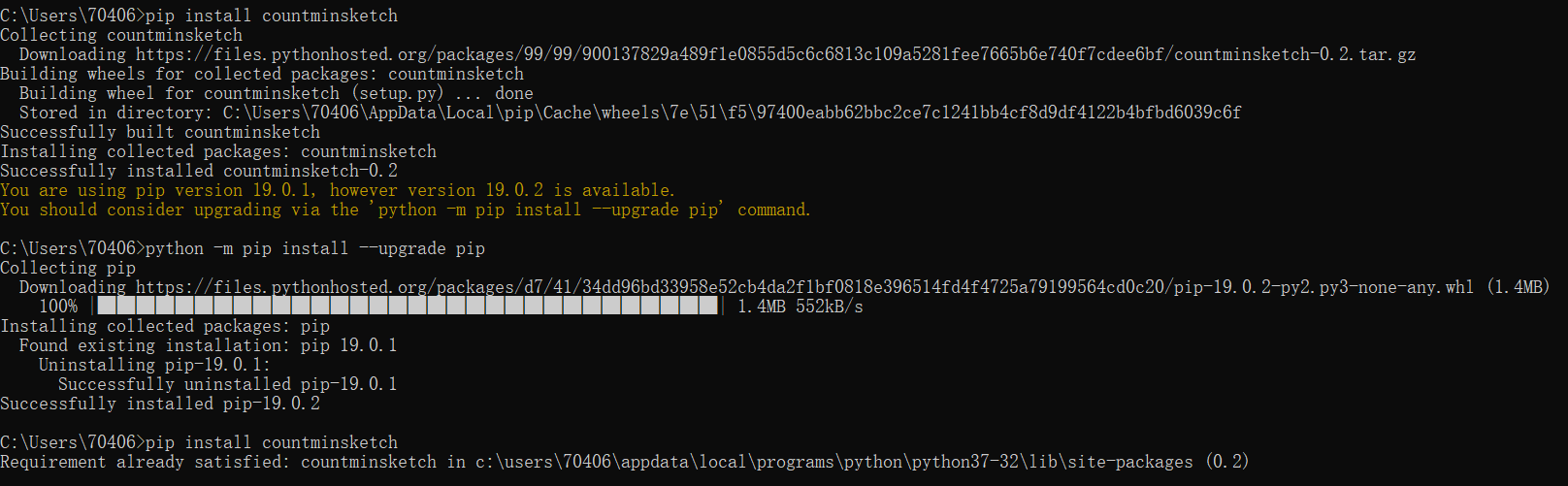
- 1.克隆一种版本(python或者c语言)的代码,大致了解如何使用这个代码,在ubuntu系统上编译。自己任意编写一个小测试,成功运行这个代码。
通过pip安装countminsketch0.2
在GitHub上找到了一个countminsketch项目
- 因为代码比较久远,需要把xrange()函数更替为range()函数
- 出现Unicode-objects must be encoded before hashing问题时,发现是update() 方法必须指定要指定编码格式,否则会报错。应在update()内添加.encode("utf8")
- 在网络上下载《飘》的英文版
编写程序,统计文中的地名“tala”的出现次数
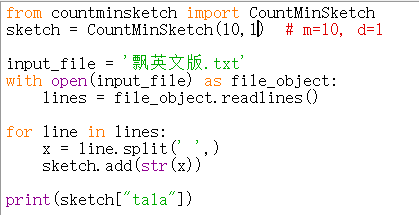
运行成程序三次,结果分别为

2.你也可以自己实现Count-min sketch。
获取用户请求(15')
现在需要获取用户的请求信息,其实请求就是网络传输的数据包,可以使用自己的网络环境来模拟服务器的请求,使用工具来捕获这个数据包:
- 1.安装并使用抓包工具tcpdump
- 2.输入tcpdump -n 获取数据包的信息
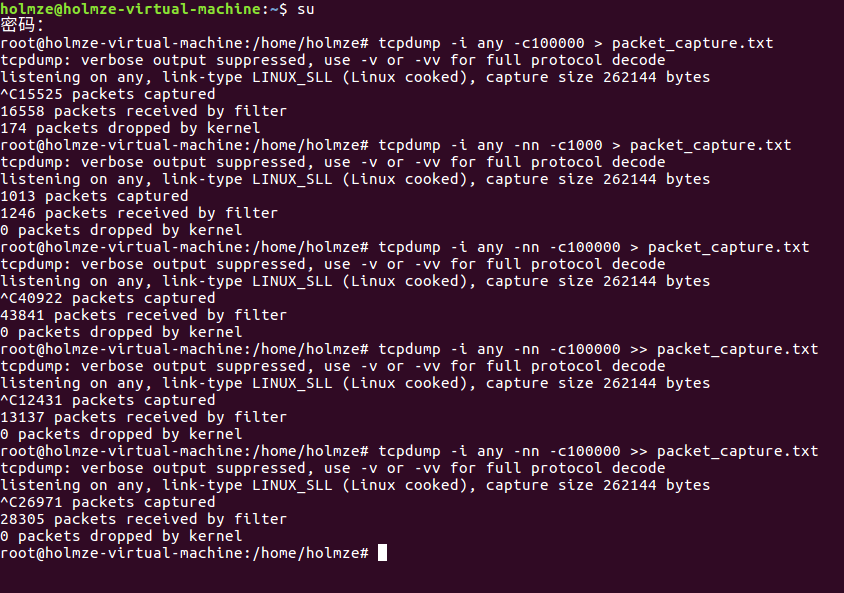
- 在这部分中,因为Ubuntu的版本原因,卡了很久。最后改成Ubuntu16.04后才能顺利抓包。>_<
3.使用linux 重定向的方法把该信息用文本文件存起来,文件命名为 pakcet_capture.txt。
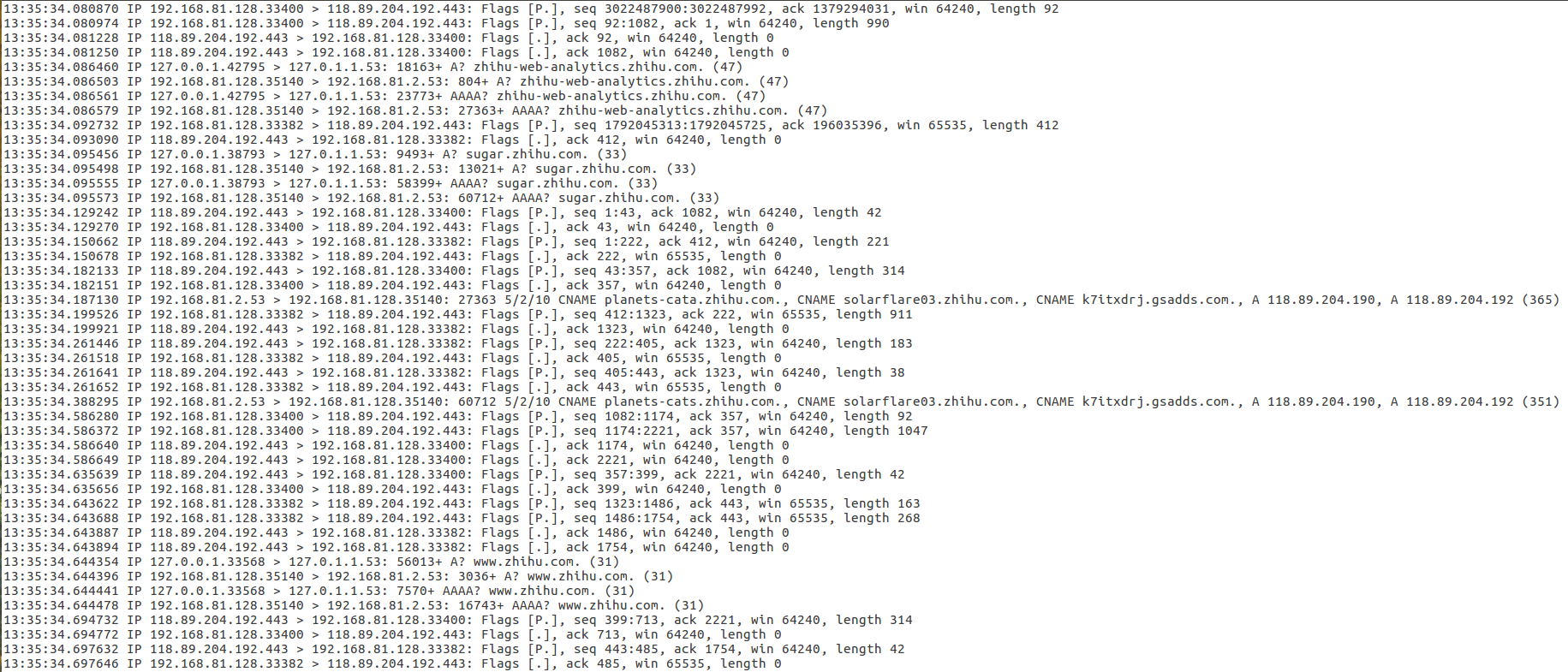
编写一个py程序,处理得到的数据
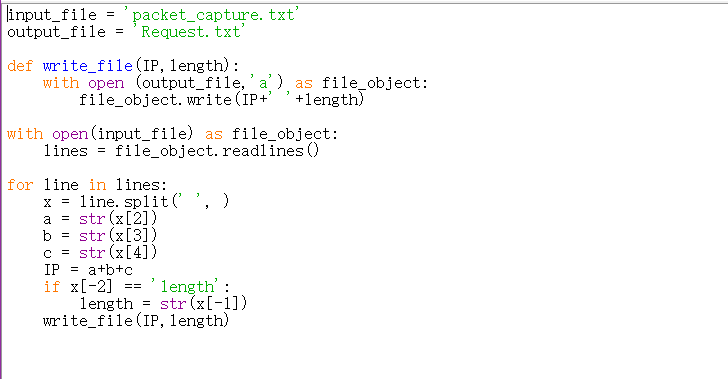
得到的Request.txt

测试新技术
完事具备,只欠东风:
- 用跑通的Count-min sketch程序读文件,获得最后的处理结果,请求大小超过阈值T认定为黑客,此处T自己定义。对于你所完成题目,把实现思路和实现结果记录在博客中,把代码提交到github的仓库上。
稍微改造一下第二次作业中的代码,添加了count-min sketch算法得到的名单

开放题(50')
- 理论部分(25')
- 解释为什么 sketch 可以省空间
- count-min sketch算法使用了hash函数,通过压缩映射,使得散列值的空间远远小于输入值的空间。
用流程图描述Count-min sketch的算法过程
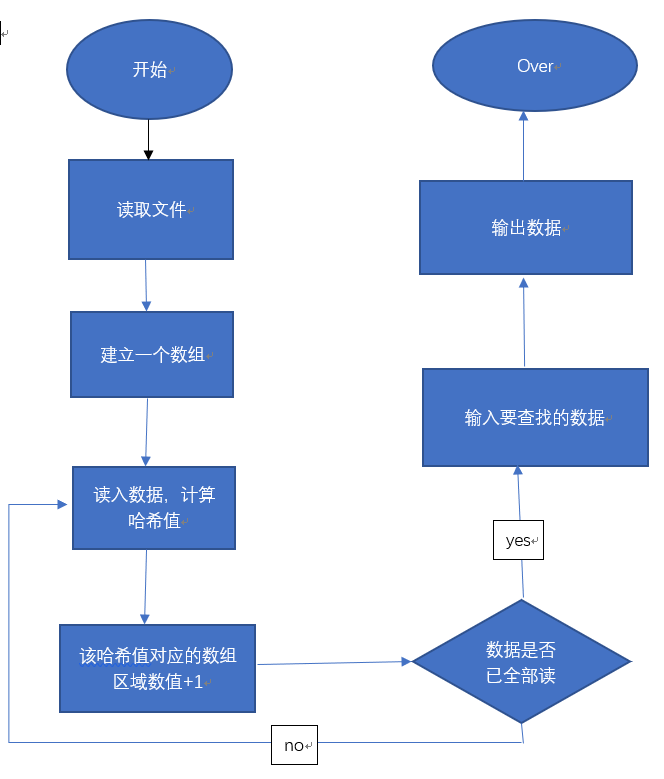
- 拿它和你改进后方法进行对比,分析优劣
- 优点:引入了count-min sketch后,很大程度上减小了空间占用和处理速度。
- 缺点:
- 可能是笔者不是很懂count-min sketch算法中m,d值的设置,抑或是算法本身的原因,得到的数据不甚准确,每次计算得到的值基本不同。但因为是针对大体量数据进行的计算,一些误差可以看淡甚至忽略不计。但若是对较少数据量的计算,误差则会严重影响精度(例如本文中给出的,对《飘》中地名的统计,难以得到较为准确的数据)
- 吐槽Count-min sketch
- 笔者在GitHub上找到的代码过于久远,py中的xrange()函数已经被弃用了,需要手动改成range()。
- readme文件有些地方说得晦涩难懂,花了一些功夫才搞懂怎么使用。
- 解释为什么 sketch 可以省空间
- 实验部分(25')
- 由于笔者的能力和时间上的原因,这部分没完成。