Kafka简介
首先,我们还是先从官网入手吧:kafka.apache.org。
那么Kafka是什么呢?官网上面是说:Apache Kafka® is a distributed streaming platform 这个是改版后的介绍了,以前就是一个消息中间件。
那么Kafka有什么用呢?
- 发布与订阅(就是读写数据)
- 处理数据(当数据读取到Kafka里面后现在可以在Kafka里面直接对一些数据进行处理了)
- 存储,因为Flume也是可以将数据从一端传送到另外一端去的,但是Flume的数据一般是走memory-channel的,我们很少走磁盘type的。当读写数据的数据出现严重差异的时候就需要有一个地方来缓存一下数据了,而Kafka就很好的胜任这一个任务了。
其次,Kafka的缓存数据不是在内存里面的,而是落盘到Linux的文件里面,这里就引出了一个概念就是partition,每一个partition对应一个Linux的文件夹,里面以多个文件来存储我们的流式数据
接着,Kafka是使用一个叫做topic的概念来区分不同业务的数据的。假如现在我们有3台机器部署了Kafka,我们分别从订单系统和货物系统上接收数据,这些数据都是经过我们Kafka所部署的3台机器,那么我们怎么区分不同的数据呢?我们在创建一个不同的topic来代表不同的数据流生产线。
订单系统发送的数据路线:omn–>Flume–>Kafka–>SparkStreaming.1
wms–>Flume–>Kafka–>SparkStreaming.2
这样不同topic的数据之间就是相互独立的,大家不会拿错数据了。在生产当中我们可以创建多个topic来构建不同的业务线来获取数据,而不同的业务线也可以公用这些Kafka机器了。
Kafka核心概念
| 名词 | 解释 |
|---|---|
| producer | 生产者,就是数据的发布者,也就是将数据写入到Kafka里面的源 |
| consumer | 消费者,就是数据的订阅者,也就是将Kafka里面的数据读取出去的目标 |
| topic | 不同数据的区分,不同的topic的数据将相互独立,所以我们创建一条数据线时都要定义唯一的topic |
| partition | 分区,当数据缓存在Kafka里面时我们可以为一个topic构建多个partition,如果partition越多,数据写入和读取的并行度越高,速度越快。但多个partition的时候,数据就不在是有序的了,相同partition里面的数据是有序的,不同的时候就无序了 |
| broker | 缓存代理,Kafka集群中的一台或多台服务器统称broker,所以当producer要传入数据时要指定好broker-list |
| consumer group | 消费者组,里面有多个消费者,相同的partition不能由相同消费者组里面的同一个消费者消费 |
ConsumerGroup:
- 一个组内的消费者共享一个GroupID
- 组内的所有消费者协调一起消费topic里面的所有partition里面到数据
- 每个分区只能被一个组内的一个消费者消费
- 当一个组内的一个消费者挂了,还能有其他消费者顶上,体现容错性
请记清楚这副图:
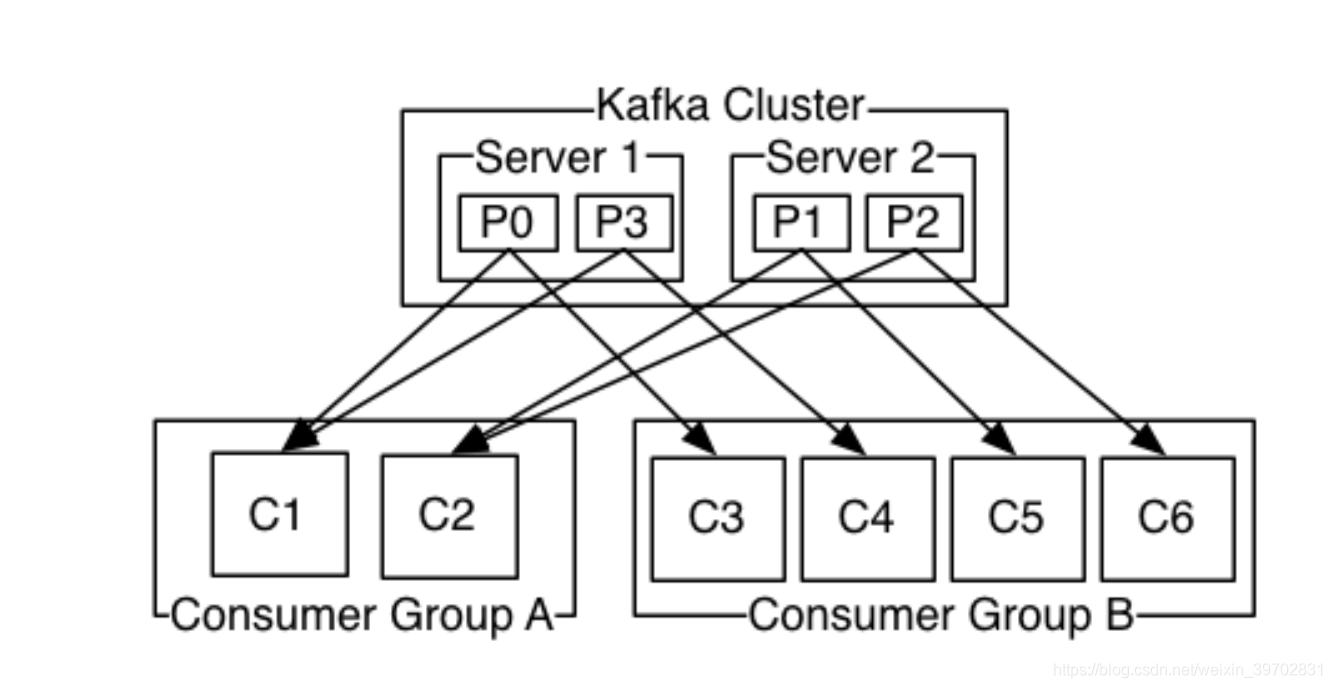
Partition
假设我们现在只用一个topic名为test,而这个topic下面了有3个partition,这个每次生产者生产的数据都会按照一个规则或者随机地落入到一个partition里面(这里的落入其实是追加,就是数据会有序地从后面加入到一个partition里面,所以说每个partition里面的数据都是有序地,按时间来排序,但是多个partition里面的数据就是无序的了)
那么在实际中如何体现一个partition的存在呢?一般一个partition对应一个文件夹,如果你为你这个topic创建了3个partition,那么就会产生3个文件夹,分别为:test-0,test-1,test-2。然后我们的数据就存储在这个3个文件夹里面的文件了。
每个partition里面存储数据的模式都是:00000000000xxxx.index和 00000000000xxxx.log。
这里,我们要引入另外一个概念offset(偏移量),而这个offset又分为:相对偏移量和绝对偏移量
假设我们一个partition里面存储了6000个数据,那么假设这个partition里面有3个文件
00000000000000.index
00000000000000.log
00000000002000.index
00000000002000.log
00000000004000.index
00000000004000.log
每一个数据都有自己唯一的偏移量,这里有6000个,那么第一个数据就是0001,第二个就是0002…最后一个为6000。所以每一个文件的名称就是前一个文件的里面最后一条数据的偏移量。所以第二个文件的名称就是00000000002000.index和
00000000002000.log,而2000这个数据是存储在00000000000000.log里面的。
由于数据量较多,我们要查找一个数据的时候不可能遍历一遍它所在的文件,这个时候我们就需要一个存储索引的文件来协助系统快速查找了。
那么这个00000000000xxxx.index文件是怎么存储索引的呢,因为每一条数据在一个partition里面有唯一的偏移量,但是不同的数据有落在了不同的文件里面,那么每一个文件里面也有一个相对偏移量和字节偏移量来确定这条数据在这个文件里面的位置。
现在我们要寻找绝对偏移量为2800的数据,按照2分法来查找,我们可以确定这条数据是在00000000002000.log这个文件里面的,然后我们用2800-2000=800,我们知道这条数据在00000000002000.log里面是第800条数据(800是相对偏移量),然后我们在00000000002000.index这个文件里面查找是否有800这个偏移量序号(因为00000000002000.index是将00000000002000.log里面的数据的相对偏移量以稀松方式存储的,所以其并不是将所有相对偏移量都存储下来的),如果没有的话就找其最近的小于它的相对偏移量出来,得到这条数据在00000000002000.log里面的字节偏移量,快速定位到那里,从那个位置开始遍历后面的数据来查找2800偏移量的这条数据。
所以00000000000xxxx.index里面时候以稀松法存储一些数据在00000000000xxxx.log里面的相对偏移量和字节偏移量的。
Kafka基础概念
消费语义
- at most once 最多一次消费,数据要么及时消费掉,那么就丢掉了
- at least once 至少消费一次,可以重复消费
- exactly once 全部数据都消费,没有丢掉且不重复消费 需要外部存储offset,如:Zk,Hbase,Redis等
生产有序
单分区有序,全局无序
数据在每一个partition里面都是按生产时间来排序的,消费也将是按照这个顺序来消费的,就是先到先出。但是当多个partitions的时候,不同partition里面的数据将没有顺序性。所以一些公司需要数据有序的话,就只能单partition了。
全局有序
如果想全局有序,就要按照数据的特性来选取不同的partition来存储了。一般的做法是将数据构建成key-value对,其中key为其特征,value就是这个数据的真实值。然后对key取模来选取对应的partition存储数据了,这个需要改Kafka的源码了,这里不多讲了。
调参与监控
Kafka的参数是在http://kafka.apache.org/documentation/#configuration网址下的,小伙伴们可以自行去查看。而监控的话,我们生产上一般是从CDH上面监控的,只要生产者和消费者的趋势一致就说明消费没有延时,具体的我们到CDH部分来细说。