本文从“然而有一种丢包...”开始步入正题。此前的胡扯可以直接跳过。
这个周末是搬入新家的第二个周末,感觉整个人比在罗湖时状态更加好了。也许这个房子的色调跟我上海的家更像吧...不管怎么说,这是我到深圳以后第一个感到振作的地方,以前曾经好几次都想离开了,但是这个家让我决定可以继续坚持。说实话我并不喜欢深圳,虽然我比较喜欢下雨,但是喜欢的是那种持续不断的雨,而不是亚热带雨林式的十分钟暴雨十分钟烈日那种。我喜欢的城市是那种纵深的,30公里回家路可以看完一本书的那种...本来嘛,今天想好好睡一觉,以往周末都是半夜三点多爬起来总结这一周的收获写写文章,今天五点多才起来,也算是睡足了。没想到两小时不到一气呵成了本文,也是简直了。唉,环境影响心情,环境影响效率,特别是对性情中人...
我的作文习惯中,都是在写完了一篇文章后在开头添加一段应景的文字,本文也不例外。现在时间2016/07/09 08:25,上述是我添加的。
TCP采用两种机制来进行重传,分别是超时重传和快速重传,其中最根本的是超时重传,至于说快速重传,你可以把它看作是一种优化措施。超时重传是在ACK时钟丢失后的最后一道防线,它是一个外部时钟来弥补ACK时钟的暂时停摆,并试图再次启动ACK时钟。
本来在设计之初,数据的传输只是利用基于统计复用的分组交换技术来代替严格TDM/FDM等电路交换技术从而进一步提高线路利用率,至于说节点之间在动态路由协议的管理下大规模自适应互联则是后来的事,因此端到端协议在这个层面上其实工作地并不好,挑战在于“按序”到达!网络节点的大规模随机互联无法保证其中传输数据的到达时序,然而按照分层模型的原则,端到端传输层协议对网络层拓扑变更的漠然以及网络层本身的无状态无连接之间,又产生一组矛盾。解决之道依然是修改TCP而保持网络层的简洁。增加一个TCP选项,由接收端在ACK中设置,在收到乱序到达的数据时,显式告诉发送端它都收到了哪些数据,由发送端自己来判断这些被收到的乱序数据和已经被确认的按序数据之间的空洞是丢失了还是乱序了,从而做出是立即重传还是继续等待重传定时器超时的决策。
比如,数据因为拥塞被路由器丢弃,那么路由器如果能发送一小段数据告诉发送端“线路已经拥塞,请不要再继续发送”,这就是传说中的“源抑制报文”,但是由于这是一种带外控制报文,不一定会被发送端收到或者处理。另一方面,如果数据是由于线路误码被丢弃了,那么要是可以发送一个消息,告诉发送端该情况,发送端就可以立即重传这个被丢失的数据包。只可惜,TCP无法保证中间网络会发送这样的报文,即便它们发了,也不能保证这些报文不会在回来的路上被拦截...困难重重。因此发送端采用了一种自适应的超时机制择机重传没有被确认的数据。这个超时时间基于RTT来计算,这里就不说了,哪里都有。特别要指出的是,TCP的超时重传采用一种退避的方式,也就是说,在第一次重传仍然没有被确认时,会退避一段更长的时间再来进行重传,随着重传次数的增多,数据始终没有被确认的话,这个退避的时间会越来越久,可以多达数分钟...注意!这是本文接下来讨论的根本。
这个地方会导致性能瓶颈,本质原因在于:明明有一种丢包是数据接收端通知给发送端原因的,可发送端并不感知,依然我行我素。解决之道也简单,让这种通知被发送端感知到即可!
我们抛开发送端忽略接收窗口而激进发送不说,仅仅从接收端的角度来讨论。事实上,接收窗口只是说发送端最多只能再发这么多数据,它表示的是接收端发送携带通告窗口的ACK时的剩余缓冲区大小,然而过了大约一个RTT后,当发送端真的发了这么多数据过来,接收端此时是否能成功接收,还要看一个全局配额,如果在此间,其它的TCP连接占据了更多的配额,导致配额剩余不足,数据包还是会被丢弃的。
在Linux的TCP实现中,有一个内核参数:
tcp_mem - vector of 3 INTEGERs: min, pressure, max min: below this number of pages TCP is not bothered about its
memory appetite.
pressure: when amount of memory allocated by TCP exceeds this number
of pages, TCP moderates its memory consumption and enters memory pressure mode, which is exited when memory consumption falls
under "min".
max: number of pages allowed for queueing by all TCP sockets.
Defaults are calculated at boot time from amount of available
memory.
说的就是这回事。其它的实现中有没有这个参数,我不是十分清楚,如果谁清楚细节,可以告知一下,我们一起讨论。在Linux的这部分判断实现中,逻辑还是比较简单的,如下的伪代码所示:
接收端在ACK中通告给发送端的窗口计算公式如下:
window = socket.receive_buffer - socket.alloced;
当接收端收到一个skb的时候,会做如下判断来决定是接收该skb,还是丢弃它:
# check_local仅仅受限于自己的通告窗口,只要发送端严格遵循接收端的通告窗口发送,一般可以通过。
if (check_local(socket, skb_size) != 0)
DROP;
# check_global受限于所有的TCP连接的内存分配,其它的TCP连接可以抢走更多的配额。
else if (check_global(socket, skb_size) != 0)
DROP
else
ACCEPT
我们来看一下check_local的细节:
bool check_local(socket, skb_size)
{
if (socket.alloced + skb_size > socket.receive_buffer)
return 1;
else
return 0;
}
当check_local通过后,意味这数据并没有超过其上一次的通告窗口的大小,进一步要检查一下全局的配额是否允许这个skb被TCP接收:
bool check_global(socket, skb_size)
{
# 首先查看自己的预分配配额。
if (socket.forward_alloc >= skb_size)
{
# 这个skb用掉了其长度大小的配额
socket.forward_alloc -= skb_size;
return 0;
}
# 如果预分配配额不够,则一次性在全局配额中为自己分配一个预分配的配额
else
{
new_forward = ALIGIN(skb_size, PAGE_SIZE);
# 如果超过了内核配置的TCP最大内存使用配额,则失败!这意味新收的skb将要被丢弃!
if (G_mem + new_forward > sysctl_mem)
{
return 1;
}
else
{
# 预分配配额延展成功,累加给socket,此后的skb可以使用这个配额
socket.forward_alloc += new_forward;
G_mem += new_forward;
return 0;
}
}
}
注意,这里并不涉及内存分配的操作,只是检查一下配额,既然skb已经存在并且已经到达了TCP层,内存分配肯定是成功了,这里检查的目的是为了避免TCP连接疯狂的吃内存,因此检查一个限额,超过限额则丢弃skb并释放内存,毕竟在skb被分配的时候,处在底层的逻辑还无法精细识别这个skb的性质,到达TCP层之后,协议栈就可以对TCP配额进行全局检查了。连同上述的check_local,这是一个分层检查体系:
skb的分配:全局内存的检查。
check_local(通告窗口检查):本TCP连接范围内的检查。
check_global(TCP配额检查):TCP协议范围内的检查。
另外需要注意的是,上述的伪代码中,我省略更复杂的逻辑。实际上,内核参数tcp_mem有三个值,分别是安全阈值,警戒阈值,超标阈值,全局的配额在不同的区间时,内核会采取不同的应对策略,更平滑地对待skb的接收,在可能的情况下,协议栈会腾出一部分为优化性能而乱序到达的skb占据的配额供按序到达的skb使用。这部分由于不涉及本文所述优化的根本,就不多说了。
如果发生误判会怎样?也就是说这个重传并不是由于接收端缓冲区配额不足而引发的,而是由于网络拥塞而引发。如果是这样的话,我们依然首先传输已经重传的那个数据而不是发送新数据的话,会怎样?
其实结果就是无效重传一个数据段而已。如果真的发生了网络拥塞,即便发送新数据也还是有大概率会丢包的。但是接下来我要说的是,收到Window Update后发现依然有数据包发出后未被确认,这件“未被确认”的事情是由于网络拥塞导致的概率是多么地低,以至于你可以认为只要在收到Window Update将窗口从0变为非0的时候仍有数据发出未被确认,几乎就是由于接收端缓冲区配额不足引发的。
假设接收端通告了N大小接收窗口,发送端发送了N个数据,考虑到目前的网络和主机配置,网络基本都是百兆,千兆级,主机的内存以4G为单位,因此窗口N应该是一个不止几个MSS的相对较大的值,也就是说,in flight的报文数量也不止几个MSS:
因此,几乎可以确定,如果在收到接收端的Zero Window消息时仍有数据未被确认,那么原因就是接收端配额满了,造成了丢包。此时发送端将会只能对这些数据进行超时重传。注意,此时由于接收端的Window已经Shrunk to zero,因此即使收到了多个duplicated ACK(其实每一个Zero Window Probe带来的ACK都是一个重复的ACK)也无法进行快速重传了,这个时候可以进行超时重传吗?注意Linux的TCP协议实现中的tcp_retransmit_skb函数,我们知道,在重传定时器超时时,会无条件调用tcp_retransmit_skb,传输传输队列中的第一个skb,该函数中有一段逻辑:
注释已经很清楚了,只有重传定时器超时才会在发送窗口不够的情况下把执行流带到tcp_retransmit_skb,理由呢?正如注释所述,将其作为一个zero window probe,这么做的目的看来实现者也想周到了,不浪费一个字节的带宽!
我们知道,TCP的数据发送在正常情况下是不依赖外部时钟,它是自时钟驱动的,也就是由ACK来驱动,然而一旦接收端缓冲区配额不足,将会产生丢包并不允许发送端再发送数据,一直到接收端重新拥有足够的缓冲区配额为止!在这段时间内,ACK自时钟是停摆的,我们认为这个时钟已丢失!
TCP依靠一个外部的定时器取代ACK自时钟丢失期间的时钟,这就是Zero Window Probe机制,TCP发送端会定时发送一个探测包,诱导接收端回应一个ACK,这个ACK中会包含其当前的接收窗口,这个接收窗口反应了自己的缓冲区配额现状,一旦发送端收到了一个通告窗口不为0的ACK,它就可以继续发送数据了,是否立即发送取决于Nagle,CORK等算法。发送端可以发送数据意味着可以重启ACK自时钟了。这一切看似都很合理,但是会有一个性能问题。
如果在收到Window Update的时候,恰恰有数据已经被重传且仍未得到确认(我们已经知道这十有八九是接收端缓冲区配额不足引发的),如果这个时候能立即发送这个数据的话,将会在一个RTT内获得确认,从而TCP发送流继续下去,然而由于ACK时钟的缺失,发送端完全依靠外部的重传定时器来决定什么时候再次重传这个未被确认的数据,而我们知道,重传定时器是执行退避策略的,简单点说就是再次重传的间隔逐渐延长,在发送端收到带有Window Update的ACK时,这个重传定时器离到期的时间可能还很久,这个时候会有以下3种可能,假设发送端禁用了Nagle:
这种事情发生的概率会非常低!因为主机的发送时延和网络时延(体现在RTT上)根本不在一个量级上,如果说在超高速网络上主机延时是一笔很大的开销并且可能大于网络延时,但是如果真的是在超高速网络上,接收端产生Zero Window的概率也是极低的,不是有个原则叫做“在超高速网络上,优化端主机的收益大于优化网络本身的收益”吗?此时端主机是瓶颈,如果连这个都还没搞定,别的还搞毛啊!
综上所述,无论哪种情况,首先立即重传已经被重传的数据并重置重传定时器都是不错的选择。
在正式的代码中,上述逻辑填入tcp_ack即可。测试结果也是非常符合预期的。唯一的难点就是现象不是太好模拟。为了模拟缓冲区配额不足导致的丢包,我需要执行以下的脚本:
id=$(ps -e|grep curl|awk -F ' ' '{print $1}') ;
echo $id;
while true; do
kill -STOP $id;
sleep 10;
kill -SIGCONT $id;
# sleep 10ms,为了避免一次性腾出太多的空间!
sleep 0.01;
done
然而TCP会自动降低发送速率的,为了制造突发而丢包,我尝试在发送端制造了突发队列,但这并无卵用。最简单的就是使用tcp_probe机制在发送端忽略接收端的通告窗口,直接修改tp->snd_wnd字段即可。模拟现象是令人痛苦的,最好的方式就是在真实网络上抓包,比较优化前后的抓包结果,同时比较优化前后的效率统计结果。
关于模拟测试这种事情本来就不能精确化每一次测试,如果没有统计意义,测试就是没有意义的,毕竟,任意一次的TCP测试任何人使用任何技术都无法把控细节,它跟全世界的人们的行为有关,很有可能,处在石家庄的一个人突然感觉心情不好,然后打开电脑开始看电影,就会影响你的一次测试结果!这是个混沌系统,蝴蝶效应时刻会影响测试结果。
理解现象的本质比知道怎么优化更加重要和有用,因为只要你对一个现象有足够深入的理解,你会发现优化方案远不止一个,本例中,还有一种优化方案就是在重发一个数据作为Zero Window Probe之后,如果收到的是一个Zero Window ACK,那么就不再执行退避,我不知道Linux目前是不是这么实现的,带我认为这是合理的,为什么说合理呢?因为退避是为网络拥塞的判定而退避的,然而当你被一个重传作为Probe并且确实得到了回应时,就可以下结论网络并没有拥塞,同时可以下结论这个丢包是由于接收端缓冲区配额不足引发的。爆炸!
几乎所有人都知道,TCP的发送端以拥塞窗口和接收窗口之间的最小值来作为发送窗口发送数据。其实这么理解是不足的,原因在于拥塞窗口的约束更小。直接点说,拥塞窗口不是滑动窗口,它是一个标量,只控制可以发送数据的多少而不控制数据之间的序列,而接收窗口则是一个滑动窗口,它是一个向量,不但控制发送数据的多少(由对端缓冲区配额决定),也控制发送数据的顺序(由TCP的按序接收决定)。这么规定是合理的,因为目前的网络基本是一个无状态无连接的IP网络,网络不会要求TCP的数序,它只关心TCP发送的数据是否超过了它的处理能力,然而接收端却除了要关注数据是否超过了自身处理能力之外,还要关心是否按序。所以说,在TCP数据发送或者重发的时候,对两种窗口的配额检测是不同的,分别如下:
if (segments_in_flight < congestion_window)
TRUE;
else
FALSE;
只要是TRUE,就可以继续发送skb,而根本不管是哪个skb!
if (skb.end_seqence - tcp.una < receive_window)
TRUE;
else
FALSE;
只有两种窗口的配额检测全部通过,数据才能被发送。
这个周末是搬入新家的第二个周末,感觉整个人比在罗湖时状态更加好了。也许这个房子的色调跟我上海的家更像吧...不管怎么说,这是我到深圳以后第一个感到振作的地方,以前曾经好几次都想离开了,但是这个家让我决定可以继续坚持。说实话我并不喜欢深圳,虽然我比较喜欢下雨,但是喜欢的是那种持续不断的雨,而不是亚热带雨林式的十分钟暴雨十分钟烈日那种。我喜欢的城市是那种纵深的,30公里回家路可以看完一本书的那种...本来嘛,今天想好好睡一觉,以往周末都是半夜三点多爬起来总结这一周的收获写写文章,今天五点多才起来,也算是睡足了。没想到两小时不到一气呵成了本文,也是简直了。唉,环境影响心情,环境影响效率,特别是对性情中人...
我的作文习惯中,都是在写完了一篇文章后在开头添加一段应景的文字,本文也不例外。现在时间2016/07/09 08:25,上述是我添加的。
TCP重传概述
TCP使用重传机制来应对丢包,这种丢包一般被认为发生在TCP的端到端之间,其原因大致可以分为线路误码,网络拥塞。TCP采用两种机制来进行重传,分别是超时重传和快速重传,其中最根本的是超时重传,至于说快速重传,你可以把它看作是一种优化措施。超时重传是在ACK时钟丢失后的最后一道防线,它是一个外部时钟来弥补ACK时钟的暂时停摆,并试图再次启动ACK时钟。
ACK而非NAK小史
TCP在设计之初,并没有采用NAK的机制来显式通知数据发送端哪些数据已经丢失,这是因为一方面在上世纪80年代线路资源是昂贵的,就目前的普遍情形来讲,互联网中占据30%的包都是ACK包,这种情况在那个年代本来就很夸张,再加上NAK通知,那就更不能接受了,另一方面是TCP的ACK机制完全有能力让发送端判断哪些数据包是丢失的。作为一系列的优化措施,Nagle,延迟ACK等算法被发明,这些优化措施中,很多都是相互打架的,造成这种局面的原因在于,吞吐和时延本来就是不相容的,就像时间和空间一样,你必须做出取舍或者权衡。SACK的出现
随着网络技术的发展,节点的互联拓扑越来越复杂,分层设计是应对复杂的根本之道。相继出现了各种支持分层的域,组织与组织之间也划分为各种自治域或者路由域,这些对于端到端按序协议比如TCP来讲,是一种挑战!本来在设计之初,数据的传输只是利用基于统计复用的分组交换技术来代替严格TDM/FDM等电路交换技术从而进一步提高线路利用率,至于说节点之间在动态路由协议的管理下大规模自适应互联则是后来的事,因此端到端协议在这个层面上其实工作地并不好,挑战在于“按序”到达!网络节点的大规模随机互联无法保证其中传输数据的到达时序,然而按照分层模型的原则,端到端传输层协议对网络层拓扑变更的漠然以及网络层本身的无状态无连接之间,又产生一组矛盾。解决之道依然是修改TCP而保持网络层的简洁。增加一个TCP选项,由接收端在ACK中设置,在收到乱序到达的数据时,显式告诉发送端它都收到了哪些数据,由发送端自己来判断这些被收到的乱序数据和已经被确认的按序数据之间的空洞是丢失了还是乱序了,从而做出是立即重传还是继续等待重传定时器超时的决策。
超时定时器是一个必不可少的外部时钟
之所以要采用定时器超时重传机制,是因为TCP发送端发出数据后,除了被接收端确认可以明确知道发送成功之外,完全不知道数据发出后发生了什么,因此发送端需要进行判断,数据肯定是丢失了(其实不一定,也可能被网络cache住了,或者说绕远路了),如果此时能有一个机制告诉发送端数据丢失的原因,那将会帮助发送端做出更好的决策。比如,数据因为拥塞被路由器丢弃,那么路由器如果能发送一小段数据告诉发送端“线路已经拥塞,请不要再继续发送”,这就是传说中的“源抑制报文”,但是由于这是一种带外控制报文,不一定会被发送端收到或者处理。另一方面,如果数据是由于线路误码被丢弃了,那么要是可以发送一个消息,告诉发送端该情况,发送端就可以立即重传这个被丢失的数据包。只可惜,TCP无法保证中间网络会发送这样的报文,即便它们发了,也不能保证这些报文不会在回来的路上被拦截...困难重重。因此发送端采用了一种自适应的超时机制择机重传没有被确认的数据。这个超时时间基于RTT来计算,这里就不说了,哪里都有。特别要指出的是,TCP的超时重传采用一种退避的方式,也就是说,在第一次重传仍然没有被确认时,会退避一段更长的时间再来进行重传,随着重传次数的增多,数据始终没有被确认的话,这个退避的时间会越来越久,可以多达数分钟...注意!这是本文接下来讨论的根本。
然而有一种丢包...
然而有一种丢包明明是可以将原因通知到发送端的,但好像没有,这种丢包是由于数据接收端的缓冲区不足引发的。我先说结论吧,然后再详细分析。结论
收到数据接收端的通告窗口从0到非0的Update通知后,应该判断是否存在数据被发送却没有得到确认,如果存在,应该首先立即重传这部分数据并重置超时重传定时器。这个地方会导致性能瓶颈,本质原因在于:明明有一种丢包是数据接收端通知给发送端原因的,可发送端并不感知,依然我行我素。解决之道也简单,让这种通知被发送端感知到即可!
接收缓冲区配额不足引发丢包可以被优化的原因分析
1.为什么会发生由于接收端缓冲区不足而导致的丢包?
也许你要问了,通告窗口即可以再发多少数据不是接收端发给发送端的吗?怎么可能出现发送端发了而接收端收不下的情形呢?我们抛开发送端忽略接收窗口而激进发送不说,仅仅从接收端的角度来讨论。事实上,接收窗口只是说发送端最多只能再发这么多数据,它表示的是接收端发送携带通告窗口的ACK时的剩余缓冲区大小,然而过了大约一个RTT后,当发送端真的发了这么多数据过来,接收端此时是否能成功接收,还要看一个全局配额,如果在此间,其它的TCP连接占据了更多的配额,导致配额剩余不足,数据包还是会被丢弃的。
在Linux的TCP实现中,有一个内核参数:
tcp_mem - vector of 3 INTEGERs: min, pressure, max min: below this number of pages TCP is not bothered about its
memory appetite.
pressure: when amount of memory allocated by TCP exceeds this number
of pages, TCP moderates its memory consumption and enters memory pressure mode, which is exited when memory consumption falls
under "min".
max: number of pages allowed for queueing by all TCP sockets.
Defaults are calculated at boot time from amount of available
memory.
说的就是这回事。其它的实现中有没有这个参数,我不是十分清楚,如果谁清楚细节,可以告知一下,我们一起讨论。在Linux的这部分判断实现中,逻辑还是比较简单的,如下的伪代码所示:
接收端在ACK中通告给发送端的窗口计算公式如下:
window = socket.receive_buffer - socket.alloced;
当接收端收到一个skb的时候,会做如下判断来决定是接收该skb,还是丢弃它:
# check_local仅仅受限于自己的通告窗口,只要发送端严格遵循接收端的通告窗口发送,一般可以通过。
if (check_local(socket, skb_size) != 0)
DROP;
# check_global受限于所有的TCP连接的内存分配,其它的TCP连接可以抢走更多的配额。
else if (check_global(socket, skb_size) != 0)
DROP
else
ACCEPT
我们来看一下check_local的细节:
bool check_local(socket, skb_size)
{
if (socket.alloced + skb_size > socket.receive_buffer)
return 1;
else
return 0;
}
当check_local通过后,意味这数据并没有超过其上一次的通告窗口的大小,进一步要检查一下全局的配额是否允许这个skb被TCP接收:
bool check_global(socket, skb_size)
{
# 首先查看自己的预分配配额。
if (socket.forward_alloc >= skb_size)
{
# 这个skb用掉了其长度大小的配额
socket.forward_alloc -= skb_size;
return 0;
}
# 如果预分配配额不够,则一次性在全局配额中为自己分配一个预分配的配额
else
{
new_forward = ALIGIN(skb_size, PAGE_SIZE);
# 如果超过了内核配置的TCP最大内存使用配额,则失败!这意味新收的skb将要被丢弃!
if (G_mem + new_forward > sysctl_mem)
{
return 1;
}
else
{
# 预分配配额延展成功,累加给socket,此后的skb可以使用这个配额
socket.forward_alloc += new_forward;
G_mem += new_forward;
return 0;
}
}
}
注意,这里并不涉及内存分配的操作,只是检查一下配额,既然skb已经存在并且已经到达了TCP层,内存分配肯定是成功了,这里检查的目的是为了避免TCP连接疯狂的吃内存,因此检查一个限额,超过限额则丢弃skb并释放内存,毕竟在skb被分配的时候,处在底层的逻辑还无法精细识别这个skb的性质,到达TCP层之后,协议栈就可以对TCP配额进行全局检查了。连同上述的check_local,这是一个分层检查体系:
skb的分配:全局内存的检查。
check_local(通告窗口检查):本TCP连接范围内的检查。
check_global(TCP配额检查):TCP协议范围内的检查。
另外需要注意的是,上述的伪代码中,我省略更复杂的逻辑。实际上,内核参数tcp_mem有三个值,分别是安全阈值,警戒阈值,超标阈值,全局的配额在不同的区间时,内核会采取不同的应对策略,更平滑地对待skb的接收,在可能的情况下,协议栈会腾出一部分为优化性能而乱序到达的skb占据的配额供按序到达的skb使用。这部分由于不涉及本文所述优化的根本,就不多说了。
2.收到Window Update时若有已重传未确认的数据,如何确认这些重传不是由于网络拥塞引发的?
首先,采用我的这个优化策略,即“收到数据接收端的通告窗口从0到非0的Update通知后,应该判断是否存在数据被发送却没有得到确认,如果存在,应该首先立即重传这部分数据并重置超时重传定时器。”如果发生误判会怎样?也就是说这个重传并不是由于接收端缓冲区配额不足而引发的,而是由于网络拥塞而引发。如果是这样的话,我们依然首先传输已经重传的那个数据而不是发送新数据的话,会怎样?
其实结果就是无效重传一个数据段而已。如果真的发生了网络拥塞,即便发送新数据也还是有大概率会丢包的。但是接下来我要说的是,收到Window Update后发现依然有数据包发出后未被确认,这件“未被确认”的事情是由于网络拥塞导致的概率是多么地低,以至于你可以认为只要在收到Window Update将窗口从0变为非0的时候仍有数据发出未被确认,几乎就是由于接收端缓冲区配额不足引发的。
假设接收端通告了N大小接收窗口,发送端发送了N个数据,考虑到目前的网络和主机配置,网络基本都是百兆,千兆级,主机的内存以4G为单位,因此窗口N应该是一个不止几个MSS的相对较大的值,也就是说,in flight的报文数量也不止几个MSS:
1).若开头N-3个数据段发生拥塞丢包
由于发生丢包,接收端收到的数据段不会填满通告窗口,丢包将会触发3个重复ACK,将会导致窗口后滑的减缓乃至停滞,因此不待通告窗口被填满即可触发重传。2).若最后3个数据段发生拥塞丢包
若是这样,虽然不会触发快速重传,但会触发超时重传,然后继续着1)或者2)。因此,几乎可以确定,如果在收到接收端的Zero Window消息时仍有数据未被确认,那么原因就是接收端配额满了,造成了丢包。此时发送端将会只能对这些数据进行超时重传。注意,此时由于接收端的Window已经Shrunk to zero,因此即使收到了多个duplicated ACK(其实每一个Zero Window Probe带来的ACK都是一个重复的ACK)也无法进行快速重传了,这个时候可以进行超时重传吗?注意Linux的TCP协议实现中的tcp_retransmit_skb函数,我们知道,在重传定时器超时时,会无条件调用tcp_retransmit_skb,传输传输队列中的第一个skb,该函数中有一段逻辑:
tcp_retransmit_skb(sk, tcp_write_queue_head(sk)):
...
/* If receiver has shrunk his window, and skb is out of
* new window, do not retransmit it. The exception is the
* case, when window is shrunk to zero. In this case
* our retransmit serves as a zero window probe.
*/
if (!before(TCP_SKB_CB(skb)->seq, tcp_wnd_end(tp))
&& TCP_SKB_CB(skb)->seq != tp->snd_una)
return -EAGAIN;
...
err = tcp_transmit_skb(sk, skb, 1, GFP_ATOMIC);注释已经很清楚了,只有重传定时器超时才会在发送窗口不够的情况下把执行流带到tcp_retransmit_skb,理由呢?正如注释所述,将其作为一个zero window probe,这么做的目的看来实现者也想周到了,不浪费一个字节的带宽!
3.收到Window Update时会立即重传仍未确认的数据吗?
不会!我们知道,TCP的数据发送在正常情况下是不依赖外部时钟,它是自时钟驱动的,也就是由ACK来驱动,然而一旦接收端缓冲区配额不足,将会产生丢包并不允许发送端再发送数据,一直到接收端重新拥有足够的缓冲区配额为止!在这段时间内,ACK自时钟是停摆的,我们认为这个时钟已丢失!
TCP依靠一个外部的定时器取代ACK自时钟丢失期间的时钟,这就是Zero Window Probe机制,TCP发送端会定时发送一个探测包,诱导接收端回应一个ACK,这个ACK中会包含其当前的接收窗口,这个接收窗口反应了自己的缓冲区配额现状,一旦发送端收到了一个通告窗口不为0的ACK,它就可以继续发送数据了,是否立即发送取决于Nagle,CORK等算法。发送端可以发送数据意味着可以重启ACK自时钟了。这一切看似都很合理,但是会有一个性能问题。
如果在收到Window Update的时候,恰恰有数据已经被重传且仍未得到确认(我们已经知道这十有八九是接收端缓冲区配额不足引发的),如果这个时候能立即发送这个数据的话,将会在一个RTT内获得确认,从而TCP发送流继续下去,然而由于ACK时钟的缺失,发送端完全依靠外部的重传定时器来决定什么时候再次重传这个未被确认的数据,而我们知道,重传定时器是执行退避策略的,简单点说就是再次重传的间隔逐渐延长,在发送端收到带有Window Update的ACK时,这个重传定时器离到期的时间可能还很久,这个时候会有以下3种可能,假设发送端禁用了Nagle:
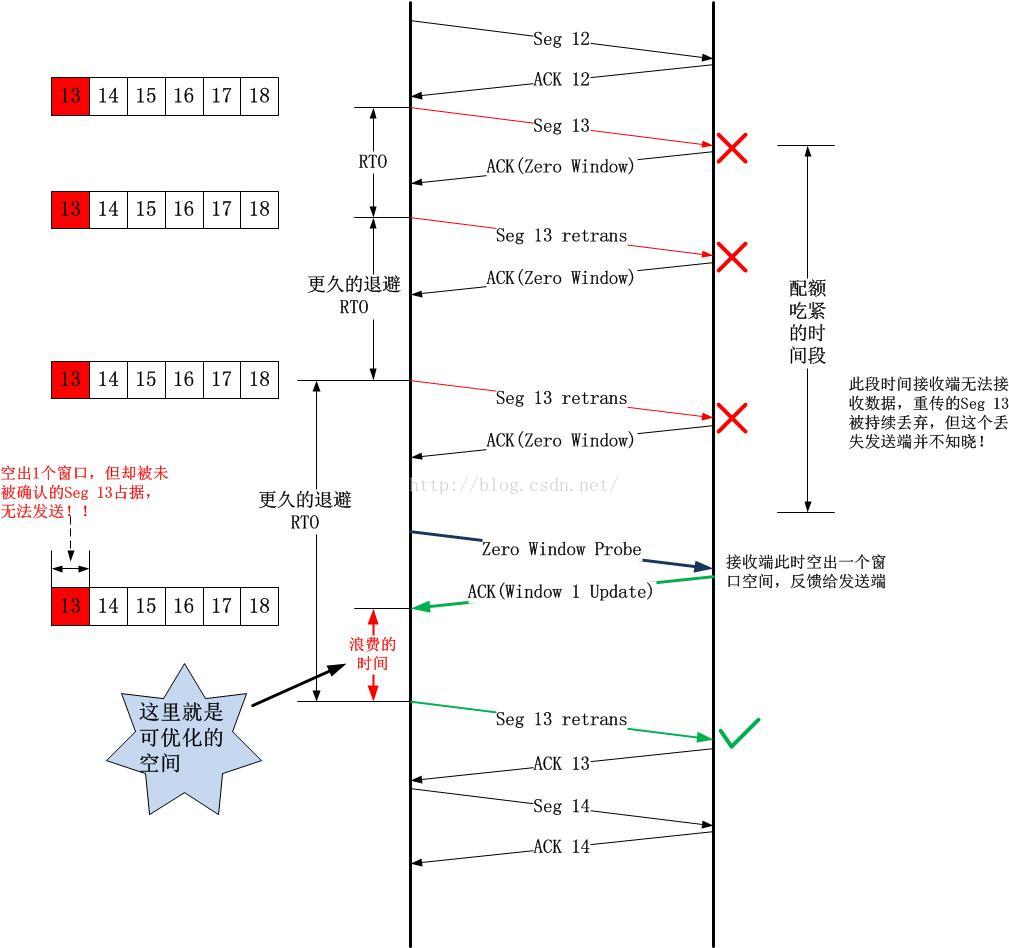
1).接收端腾出的窗口空间太小
以下的TCP时序图描述了这种情况:
2).接收端腾出的窗口刚刚好
在1)的基础上,请看以下的时序图: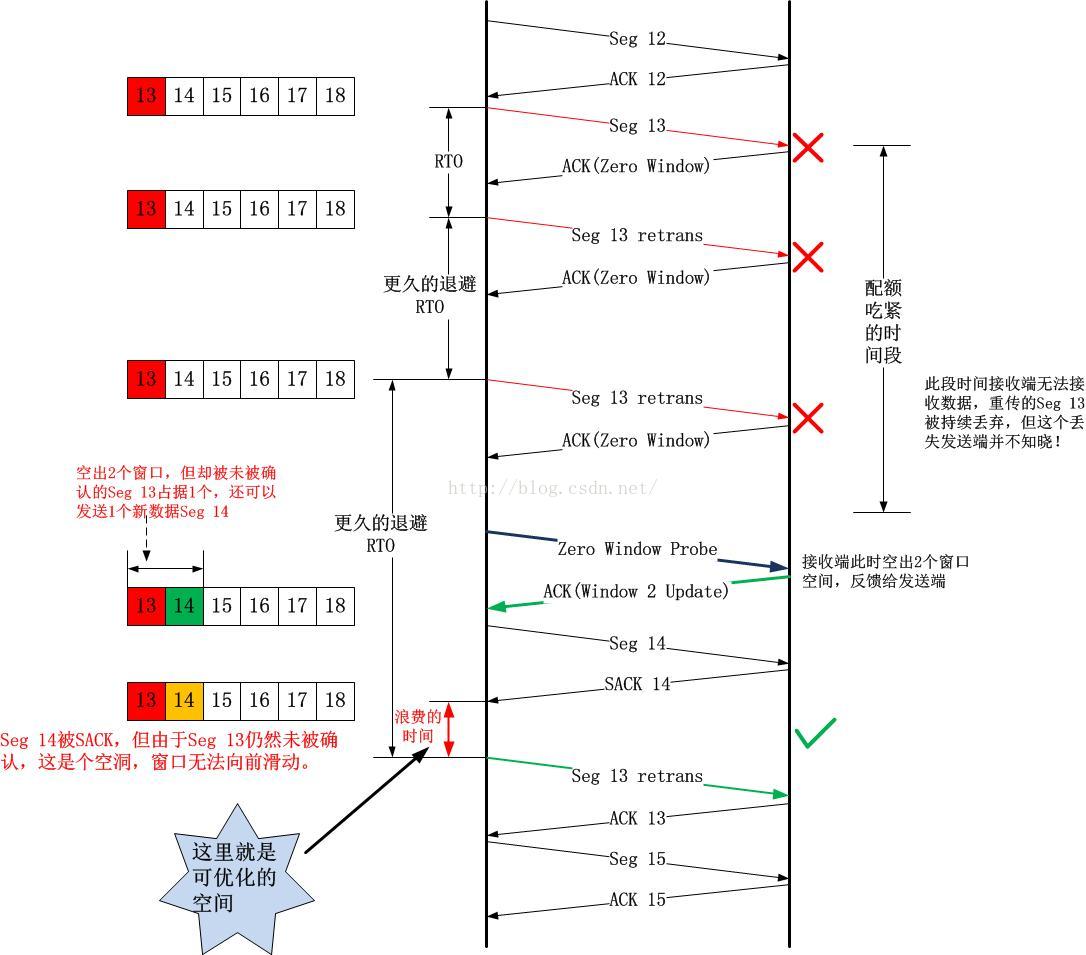
3).接收端腾出的窗口足够大
这种情形跟上面的2)没有本质的区别,上图中红色的“浪费的时间”在本场景中到底能否被弥补或者说到底有多大,取决于“接收端空出的窗口大小”以及“离Seg 13超时还有多久”之间的关系,如果在Seg 13超时之前,空出的窗口内新数据均已经被发送,那么将会出现红色的“浪费的时间”,如果到达Seg 13重传定时器到期,空闲窗口内的数据仍未被发送完毕,这就不会浪费时间。但是这种情况有多大的发生概率呢?这种事情发生的概率会非常低!因为主机的发送时延和网络时延(体现在RTT上)根本不在一个量级上,如果说在超高速网络上主机延时是一笔很大的开销并且可能大于网络延时,但是如果真的是在超高速网络上,接收端产生Zero Window的概率也是极低的,不是有个原则叫做“在超高速网络上,优化端主机的收益大于优化网络本身的收益”吗?此时端主机是瓶颈,如果连这个都还没搞定,别的还搞毛啊!
综上所述,无论哪种情况,首先立即重传已经被重传的数据并重置重传定时器都是不错的选择。
如何优化这个现象带来的性能损失
如此一来,如何优化就是非常简单的事情了。我是基于tcp_probe做的测试,修改了tcp_probe里面的HOOK函数,本例中我HOOK的是tcp_ack函数:static inline int tcp_may_update_window_ok(const struct tcp_sock *tp,
const u32 ack, const u32 ack_seq,
const u32 nwin)
{
return (after(ack, tp->snd_una) ||
after(ack_seq, tp->snd_wl1) ||
(ack_seq == tp->snd_wl1 && nwin > tp->snd_wnd));
}
static int jtcp_ack(struct sock *sk, struct sk_buff *skb, int flag)
{
const struct tcp_sock *tp = tcp_sk(sk);
const struct inet_sock *inet = inet_sk(sk);
struct tcphdr *th = tcp_hdr(skb);
struct inet_connection_sock *icsk = inet_csk(sk);
u32 ack_seq = TCP_SKB_CB(skb)->seq;
u32 ack = TCP_SKB_CB(skb)->ack_seq;
u32 rnwin = ntohs(tcp_hdr(skb)->window);
u32 nwin = rnwin;
u32 owin = tp->snd_wnd;
if (likely(!tcp_hdr(skb)->syn))
nwin <<= tp->rx_opt.snd_wscale;
if ((port == 0 || ntohs(inet->dport) == port || ntohs(inet->sport) == port) &&
tcp_may_update_window_ok(tp, ack, ack_seq, nwin) &&
(owin < nwin && owin <= 2*tp->mss_cache)) {
printk("hit! owin: %u, nwin: %u\n", owin, nwin);
icsk->icsk_retransmits++;
tcp_retransmit_skb(sk, tcp_write_queue_head(sk));
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
icsk->icsk_rto, TCP_RTO_MAX);
}
jprobe_return();
return 0;
}在正式的代码中,上述逻辑填入tcp_ack即可。测试结果也是非常符合预期的。唯一的难点就是现象不是太好模拟。为了模拟缓冲区配额不足导致的丢包,我需要执行以下的脚本:
id=$(ps -e|grep curl|awk -F ' ' '{print $1}') ;
echo $id;
while true; do
kill -STOP $id;
sleep 10;
kill -SIGCONT $id;
# sleep 10ms,为了避免一次性腾出太多的空间!
sleep 0.01;
done
然而TCP会自动降低发送速率的,为了制造突发而丢包,我尝试在发送端制造了突发队列,但这并无卵用。最简单的就是使用tcp_probe机制在发送端忽略接收端的通告窗口,直接修改tp->snd_wnd字段即可。模拟现象是令人痛苦的,最好的方式就是在真实网络上抓包,比较优化前后的抓包结果,同时比较优化前后的效率统计结果。
关于模拟测试这种事情本来就不能精确化每一次测试,如果没有统计意义,测试就是没有意义的,毕竟,任意一次的TCP测试任何人使用任何技术都无法把控细节,它跟全世界的人们的行为有关,很有可能,处在石家庄的一个人突然感觉心情不好,然后打开电脑开始看电影,就会影响你的一次测试结果!这是个混沌系统,蝴蝶效应时刻会影响测试结果。
理解现象的本质比知道怎么优化更加重要和有用,因为只要你对一个现象有足够深入的理解,你会发现优化方案远不止一个,本例中,还有一种优化方案就是在重发一个数据作为Zero Window Probe之后,如果收到的是一个Zero Window ACK,那么就不再执行退避,我不知道Linux目前是不是这么实现的,带我认为这是合理的,为什么说合理呢?因为退避是为网络拥塞的判定而退避的,然而当你被一个重传作为Probe并且确实得到了回应时,就可以下结论网络并没有拥塞,同时可以下结论这个丢包是由于接收端缓冲区配额不足引发的。爆炸!
拥塞窗口和接收窗口
本文中没有提到拥塞窗口,因为这是一篇讲端到端控制的文章,与网络拥塞无关,也就忽略了网络拥塞,当然也就不提拥塞窗口的事了。但是我还是想在最后来简单说一下接收窗口和拥塞窗口的几点不同。几乎所有人都知道,TCP的发送端以拥塞窗口和接收窗口之间的最小值来作为发送窗口发送数据。其实这么理解是不足的,原因在于拥塞窗口的约束更小。直接点说,拥塞窗口不是滑动窗口,它是一个标量,只控制可以发送数据的多少而不控制数据之间的序列,而接收窗口则是一个滑动窗口,它是一个向量,不但控制发送数据的多少(由对端缓冲区配额决定),也控制发送数据的顺序(由TCP的按序接收决定)。这么规定是合理的,因为目前的网络基本是一个无状态无连接的IP网络,网络不会要求TCP的数序,它只关心TCP发送的数据是否超过了它的处理能力,然而接收端却除了要关注数据是否超过了自身处理能力之外,还要关心是否按序。所以说,在TCP数据发送或者重发的时候,对两种窗口的配额检测是不同的,分别如下:
1).检查拥塞窗口配额
这里的检查非常简单,只检查大小即可:if (segments_in_flight < congestion_window)
TRUE;
else
FALSE;
只要是TRUE,就可以继续发送skb,而根本不管是哪个skb!
2).检查接收窗口配额
对于接收窗口,不但要检查大小,还要检查数序,因此这需要和当前发送的skb相关联:if (skb.end_seqence - tcp.una < receive_window)
TRUE;
else
FALSE;
只有两种窗口的配额检测全部通过,数据才能被发送。
写在后面
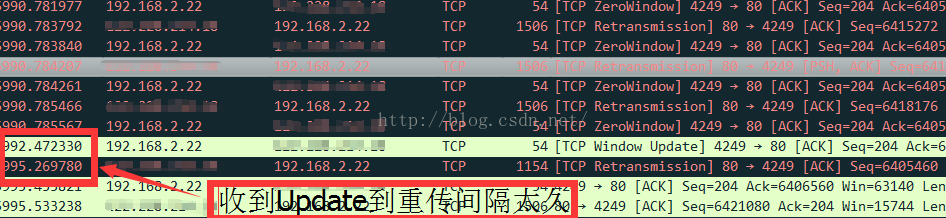
这个问题并不是凭空想出了的,也不是看代码看出来的,它来自于一个真实的问题,这个问题自出现已经有一年多了,就在前几天被现同事抓包给重现了,虽然它很难被模拟,但是就那一次被揪住现行就不错了。我把这个抓包贴图如下:
非常明确,在收到Window Update的时候,重传的1461号数据超时时间已经退避到分钟级别了,虽然从抓包上看,并没有窗口为0的ACK,这是因为ACK在Qidsc队列里丢失导致,此时如果在收到Window Update的时候,能立即重传它,就可以节省约一分钟的时间。另外还有一个例子:
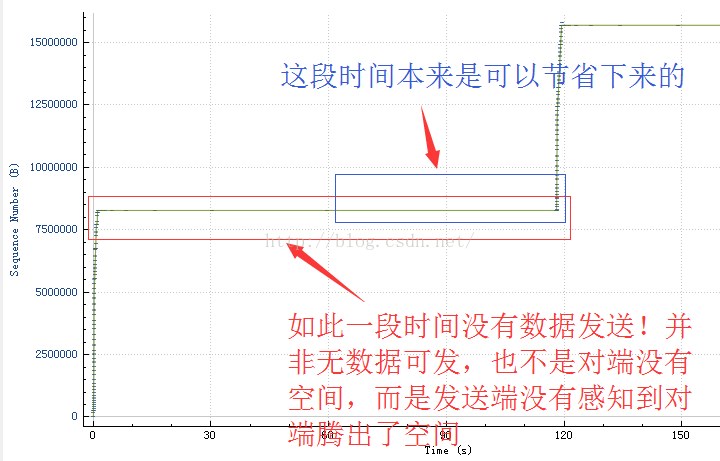
因此就有了本文。
再分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到我们人工智能的队伍中来!https://blog.csdn.net/jiangjunshow