Introduction
An “interactive” TCP connection is one in which user input such as keystrokes, short messages, or joystick/mouse movements need to be delivered between a cli- ent and a server.
If small segments are used to carry such user input, the protocol imposes more overhead because there are fewer useful payload bytes per packet exchanged.
On the other hand, filling packets with more data usually requires them to be delayed, which can have a negative impact on delay-sensitive appli- cations such as online games and collaboration tools.
We shall investigate tech- niques with which the application can trade off between these two issues.
After discussing interactive communications, we discuss the methods used by TCP for achieving flow control by dynamically adapting the window size to ensure that a sender does not overrun a receiver.
This issue primarily impacts bulk data transfer (i.e., noninteractive communications) but can also affect inter- active applications.
Interactive Communication
Bulk data segments tend to be relatively large (1500 bytes or larger), while interactive data segments tend to be much smaller (tens of bytes of user data).
As we investigate ssh, we will see how delayed acknowledgments work and
how the Nagle algorithm reduces the number of small packets across wide area net- works.
The same algorithms apply to other applications supporting remote login capability such as Telnet, rlogin, and Windows Terminal Services.
Many newcomers to TCP/IP are surprised to find that each interactive key- stroke normally generates a separate data packet.
That is, the keystrokes are sent from the client to the server individually (one character at a time rather than one line at a time).
Furthermore, ssh invokes a shell (command interpreter) on the remote system (the server), which echoes the characters that are typed at the cli- ent.
A single typed character could thus generate four TCP segments:
the inter- active keystroke from the client, an acknowledgment of the keystroke from the server, the echo of the keystroke from the server, and an acknowledgment of the echo from the client back to the server (see Figure 15-1(a)).
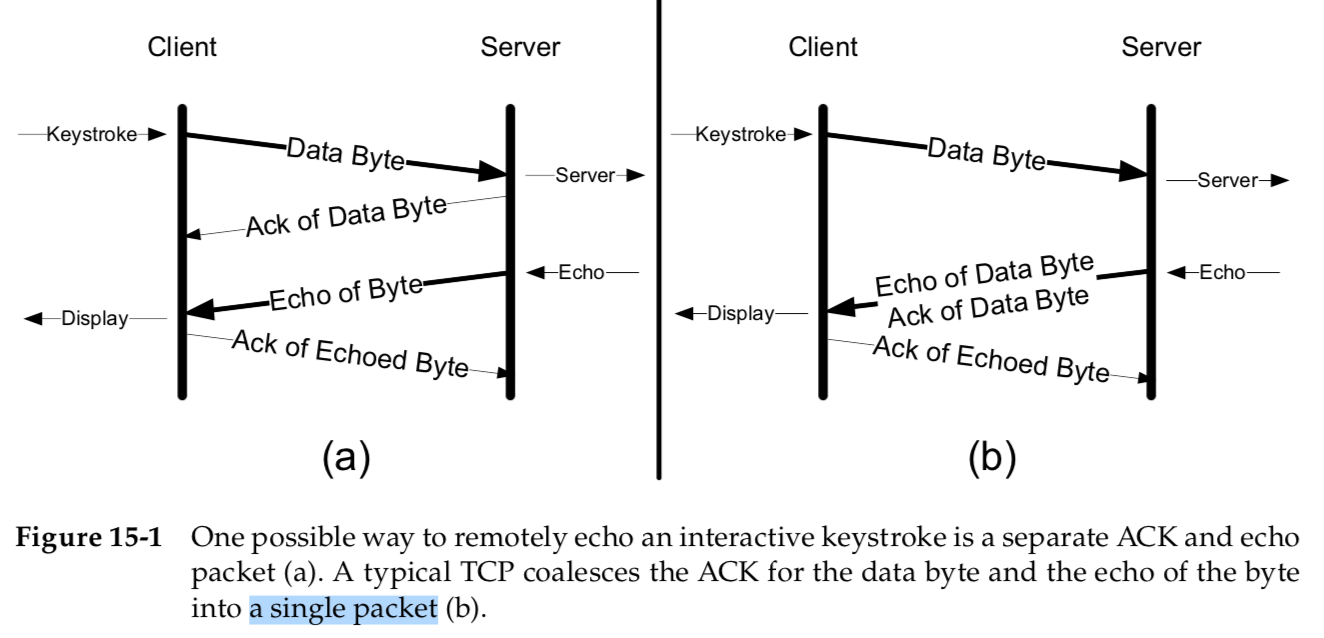
Normally, however, segments 2 and 3 are combined—in Figure 15-1(b),the acknowledgment of the keystroke is sent along with the echo of the characters typed.
We describe the technique that combines these (called delayed acknowledg- ments with piggybacking) in the next section.
We purposely use ssh for this example because it generates a packet for each character typed from the client to the server.
If the user types especially fast, however, more than one character might be carried in a single packet.
One other observation we can make about this trace is that each packet with data in it (not zero length) also has the PSH bit field set.
As mentioned earlier, this flag is conventionally used to indicate that the buffer at the side sending the packet has been emptied in conjunction with sending the packet.
In other words, when the packet with the PSH bit field set left the sender, the sender had no more data to send.
Delayed Acknowledgments
In many cases, TCP does not provide an ACK for every incoming packet.This is possible because of TCP’s cumulative ACK field (see Chapter 12).
Using a cumula- tive ACK allows TCP to intentionally delay sending an ACK for some amount of time, in the hope that it can combine the ACK it needs to send with some data the local application wishes to send in the other direction.
This is a form of piggyback- ing that is used most often in conjunction with bulk data transfers.
Obviously a TCP cannot delay ACKs indefinitely; otherwise its peer could conclude that data has been lost and initiate an unnecessary retransmission.
Delaying ACKs causes less traffic to be carried over the network than when ACKs are not delayed because fewer ACKs are used.
A ratio of 2 to 1 is fairly com- mon for bulk transfers.
The use of delayed ACKs and the maximum amount of time TCP is allowed to wait before sending an ACK can be configured, depend- ing on the host operating system.
Linux uses a dynamic adjustment algorithm whereby it can change between ACKing every segment (called “quickack” mode) and conventional delayed ACK mode
For the reasons mentioned earlier, TCP is generally set up to delay ACKs under certain circumstances, but not to delay them too long.
We will see extensive use of delayed ACKs in Chapter 16, when we look at how TCP’s congestion control behaves during bulk transfers with large packets.
When smaller packets are used, such as for interactive applications, another algorithm comes into play.
The com- bination of this algorithm with delayed ACKs can lead to poor performance if not handled carefully, so we will now look at it in more detail.
Nagle Algorithm
The Nagle algorithm says that when a TCP connection has outstanding data that has not yet been acknowledged, small segments (those smaller than the SMSS) cannot be sent
until all outstanding data is acknowledged.
Instead, small amounts of data are collected by TCP and sent in a single segment when an acknowledg- ment arrives.
This procedure effectively forces TCP into stop-and-wait behavior—it stops sending until an ACK is received for any outstanding data.
The beauty of this algorithm is that it is self-clocking: the faster the ACKs come back, the faster the data is sent.
On a comparatively high-delay WAN, where reducing the number of tinygrams is desirable, fewer segments are sent per unit time.
Said another way, the RTT controls the packet sending rate.
We saw in Figure 15-3 that the RTT for a single byte to be sent, acknowledged, and echoed can be small (under 15ms).
To generate data faster than this we would have to type more than 60 characters per second.
This means that we rarely encounter any observable effects of this algorithm when sending data between two hosts with a small RTT, such as when they are on the same LAN.
To illustrate the effect of the Nagle algorithm, we can compare the behaviors of an application using TCP with the Nagle algorithm enabled and disabled.
This is the trade-off the Nagle algorithm makes: fewer and larger packets are used, but the required delay is higher.
The different behaviors can be seen even more clearly in Figure 15-6.

Delayed ACK and Nagle Algorithm Interaction
If we consider what happens when the delayed ACK and Nagle algorithms are used together, we can construct an undesirable scenario.
Consider a client using delayed ACKs that sends a request to a server, and the server responds with an amount of data that does not quite fit inside a single packet (see Figure 15-7).
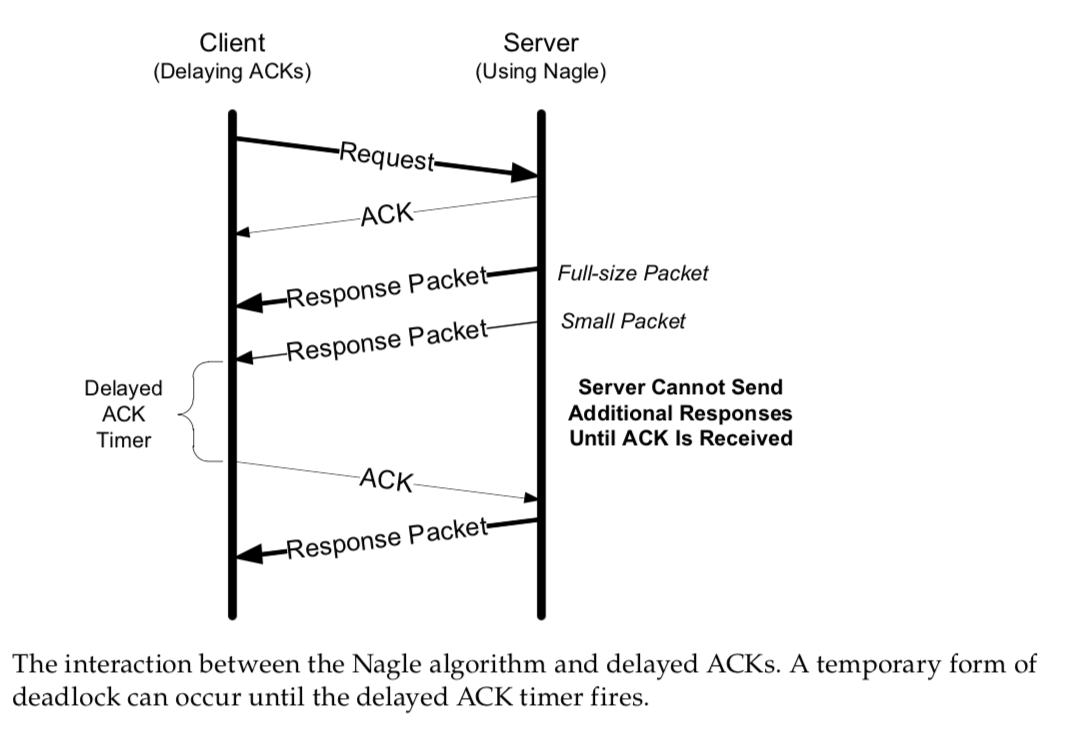
Here we see that the client, after receiving two packets from the server, with- holds an ACK, hoping that additional data headed toward the server can be piggy- backed.
Generally, TCP is required to provide an ACK for two received packets only if they are full-size, and they are not here.
At the server side, because the Nagle algorithm is operating, no additional packets are permitted to be sent to the client until an ACK is returned because at most one “small” packet is allowed to be outstanding.
The combination of delayed ACKs and the Nagle algorithm leads to a form of deadlock (each side waiting for the other) [MMSV99][MM01].
Fortu- nately, this deadlock is not permanent and is broken when the delayed ACK timer fires, which forces the client to provide an ACK even if the client has no additional data to send.
However, the entire data transfer becomes idle during this deadlock period, which is usually not desirable.
The Nagle algorithm can be disabled in such circumstances, as we saw with ssh.
Disabling the Nagle Algorithm
As we might conclude from the previous example, there are times when the Nagle algorithm needs to be turned off.
Typical examples include cases where as little delay as possible is required.
An application can specify the TCP_NODELAY option when using the Berkeley sockets API.