- 1.2 安装配置
1.2.1 安装jdk1.8
#root vim /etc/profile
export JAVA_HOME=/data/software/jdk1.8.0_191
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib1.2.2 安装hadoop+spark
#root cd /data/app/hadoop #root wget hadoop-2.7.7 #root wget spark-2.4.0-bin-hadoop2.7 #root cd /data/app/hadoop/hadoop-2.7.7 #root mkdir name tmp data #root chown -R hadoop.hadoop /data/app/hadoop #root vim /etc/profile export HADOOP_HOME=/data/app/hadoop/hadoop-2.7.7 export SPARK_HOME=/data/app/hadoop/spark-2.4.0-bin-hadoop2.7 export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop export YARN_HOME=${HADOOP_HOME} export YARN_CONF_DIR=${YARN_HOME}/etc/hadoop Export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$SPARK_HOME/sbin #pyspark开发调试必备 export PYTHONPATH=$SPARK_HOME/python/:$SPARK_HOME/python/lib/py4j-0.10.7-src.zip #hadoop source /etc/profile
- 1.2.3 配置hadoop
Core-site.xml配置
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>[文件系统名称医技访问入口]
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/data/app/hadoop/hadoop-2.7.7/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
</configuration>Hdfs-site.xml配置
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:9001</value>
</property>[从namenode一定避免与主namenode在同台机器]
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/app/hadoop/hadoop-2.7.7/name</value>
</property>[Namdenode数据,如删除它必须要格式主namenode]
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/app/hadoop/hadoop-2.7.7/data</value>
</property>[Datanode数据存储]
<property>
<name>dfs.replication</name>
<value>2</value>
</property>[每个分块复制块,默认是3,建议等于节点数量]
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>Mapperd-site.xml 配置[生产环境大部分已迁移到spark避免使用mapreduce,切记hive依赖于mapreduce]
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
</configuration>
Yarn-site.xml配置
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop01:8088</value>
</property>
</configuration>Hadoop-env.sh 配置
export JAVA_HOME=/data/software/jdk1.8.0_191Yarn-env.sh 配置
export JAVA_HOME=/data/software/jdk1.8.0_191Slaves
Hadoop01
Hadoop02- 1.2.4 spark配置
Spark-env.sh配置
export JAVA_HOME=/data/software/jdk1.8.0_191
export SPARK_MASTER_IP=hadoop01
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1[初始化work个数]
export SPARK_WORKER_MEMORY=512M
export SPARK_LOCAL_IP=192.168.0.102[Spark初始化启动模式是local,必须配置本机ip]
export PYTHONHSlaves
Hadoop01
Hadoop02- 1.2.5 hdfs常用操作
Hdfs启动
#hadoop cd /data/app/hadoop/hadoop-2.7.7
#hadoop ./sbin/start-dfs.sh
#hdfs ui:http://192.168.0.101:50070/explorer.html#/hadoop/upload启动报错,提示:execstack -c libhadoop.so?
#root rpm-Uvh http://www.rpmfind.net/linux/fedora/linux/releases/29/Everything/x86_64/os/Packages/e/execstack-0.5.0-15.fc29.x86_64.rpm
#root rpm -ivh /data/software/execstack-0.5.0-15.fc29.x86_64.rpm
#cd /data/app/hadoop/hadoop-2.7.7/lib/native
#root execstack -c libhadoop.so
1 注意提示错误信息
2 hadoop、spark压缩包在windows上解压上传到linux会修改到so包的头文件,execstack时会报非法文件错误]Hdfs常用命令
1 格式化namenode
#hadoop ./bin/hdfs namenode -format[首次启动必须先格式化namenode]
hadoopt Hadoop fs -mkdir -p /hadoop/upload
#hadoop hadoop fs -ls /hadoop/upload
#hadoop hadoop fs -put /data/app/hadoop/hadoop-2.7.7/etc/hadoop/core-site.xml /hadoop/upload
2 查看所有文件分块存储结点信息
#hadoop hdfs fsck /hadoop/upload -files -locations -blocks
1) 验证hdfs集群是否运行,如集群异常文件存储在单节点上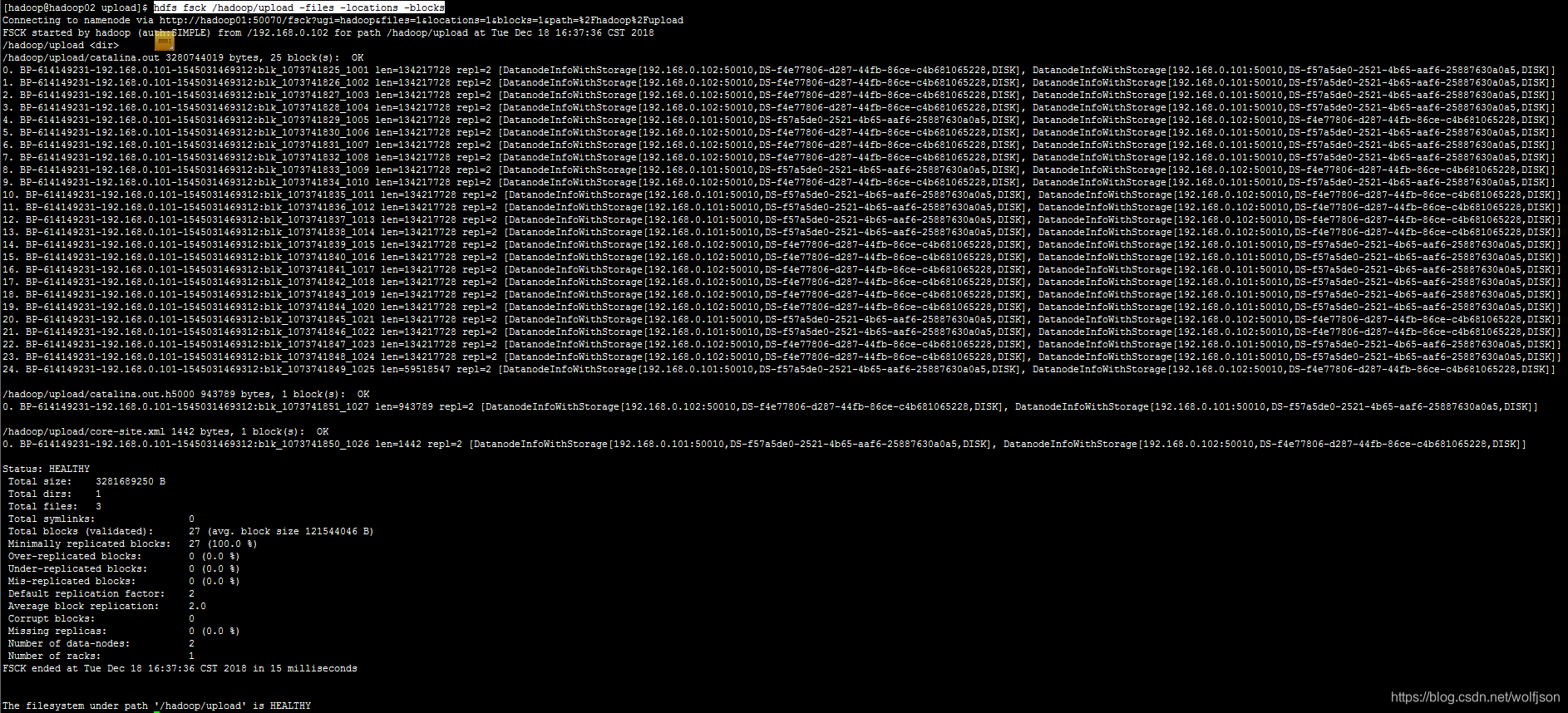
2) 验证配置的relica是否生效
3) 观察文件系统状态The filesystem under path '/hadoop/upload' is HEALTHY]
3 查看文件系统容量
#root hadoop fs -df -h
4 启动日志文件,密切观察日志文件输出
#hadoop jps[发现datanode只有master,原因:slaves未配置]
Master:namenode datanode进程
Slave:secondarynode datanode进程
hadoop-hadoop-namenode-hadoop01.log
hadoop-hadoop-namenode-hadoop01.out
hadoop-hadoop-secondarynamenode-hadoop02.log
hadoop-hadoop-secondarynamenode-hadoop02.out
hadoop-hadoop-datanode-hadoop02.log
hadoop-hadoop-datanode-hadoop02.out
hadoop-hadoop-datanode-hadoop01.log
hadoop-hadoop-datanode-hadoop01.out- 1.2.6 spark standalone模式
启动集群
#hadoop cd /data/app/hadoop/spark-2.4.0-bin-hadoop2.7
#hadoop ./sbin/start-all.sh
Spark UI:http://hadoop01:8080/(启动提示端口)
#hadoop jps
Master:master woker
Slave:work[work数量是在spark-env.sh配置的初始化work数量]机器上调试python-spark
[前提:
1 /etc/profile export PYTHONPATH=$SPARK_HOME/python/:$SPARK_HOME/python/lib/py4j-0.10.7-src.zip
2 spark-env.sh import PYTHONPATH
这种调试是运行local模式spark ui看不到
]
#hadoop cd /data/app/hadoop/spark-2.4.0-bin-hadoop2.7/test
#hadoop python anlysis_hislog.py集群提交
#hadoop ./spark-submit --master spark://hadoop01:7077 --executor-memory 500m
../test/wordcount.py hdfs://hadoop01:9000/hadoop/upload/catalina.out
[Work获取不到资源,请观察机器内存大小与配置的executor-memory,默认是1G]1.2.7 spark on yarn
不需要启动spark master、work进程
启动yarn
#hadoop ./sbin/start-yarn.sh
Spark submit
./bin/spark-submit --master yarn --executor-memory 500m --num-executors 1 /data/app/hadoop/spark-2.4.0-bin-hadoop2.7/test/logdev/rdd_test.pyQA:虚拟内存不够?
<!--虚拟内存=yarn.scheduler.minimum-allocation-mb *
yarn.nodemanager.vmem-pmem-ratio-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>9000</value>
<discription>每个任务最多可用内存,默认8182MB</discription>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>3072</value>
<discription>每个任务最小可用内存</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>3</value> <!--###物理内存和虚拟内存比率-->
</property>