哥伦比亚大学 NLP 第三章(第二部分)
目录
本部分关于上下文无关相关符号的约定均基于第一部分,本部分将继续沿用不再定义
第三章第一部分传送门:https://blog.csdn.net/scanf_yourname/article/details/86777756
概率上下文无关文法
(PCFGs)
为什么引入概率上下文无关文法?
- 我们之前讲过与上下文无关文法,它的问题是会因为生成的分析树结构不同,也就是句式结构的不同引起歧义。
- 我们现在考虑一种方法解决这个问题,就是概率与上下文无关文法。在现实生活中,我们在面对一个歧义句的时候能够分辨那个是正确的语意,在很多情况下是因为有的句式结构下产生的句子是不符合逻辑的。所以,概率与上下文无关文法的目的就是为每一种可行的句式加上一个概率以判断什么是合理的句式结构。
定义概率上下文无关文法
- 概率上下文无关文法继承了上下文无关文法的四元组,在此基础之上
PCFG为
R中的每一个映射关系定义一个条件概率
q(βj∣αi),其中
αiϵV,
βjϵ∑,
αi→βjϵR。
意味映射关系
αi→βj出现的概率为
q(βj∣αi)
规定:
∑j=0maxq(βj∣αi)=1
- 由于之前规定的左侧优先原则,我们便可根据上面的条件概率计算出每一种结构对应的概率,从而估计最可能结构。
假设
t是一种可能存在的分析树结构,根据左侧优先原则,那么它的每一步映射都是确定的:
α1→β1,
α1→β1......
αn→βn
则这颗分析树对应的概率
P(t)=∏i=1nq(βi∣αi)
假设我们要列举所以可能的分析树比较他们的概率,这个所有生成树构成的集合是
τ(s),
Tϵτ(s)
最终我们要求的就是所有可能分析树概率最大者:
argmaxtϵτ(s)p(t)

上图给出了求解右侧分析树概率的方法,按照树的先序遍历首先是
S→VP,再依次是
VP→Verb,
Verb→Book.....,
Noun→fight。我们就按照这个顺序将所有的概率乘到一起得到最后的概率。
如何通过数据学习一个
PCFG模型
- 数据来源:
Treebank,分析树的数据,数据规模是
50000,数据是手工标记的分析树。
40000数据作为训练集,
2400作为测试集,其他可能做交叉验证集了。
- 确定集合
R:
R是所有训练集数据中涉及到的映射
(α→β)的集合。
- 确定
q(β∣α):这里采用似然估计用样本概率估计总体概率,公式如下:
qML(β∣α)=Count(α)Count(α→β)
CKY 算法
CKY 算法是做什么的?
- 我们之前只是定义了一个分析树的概率大小,但是分析树的构建实际上是多种多样的,但是我们自然希望能够找到概率最大的那颗分析树,我们可以通过
CKY算法实现这一目的。
CKY 算法的思想
-
CKY是一个动态规划的算法,最终目标是求解
maxtϵτ(s)p(t)
- 首先是定义一些符号:
n=句子中单词的个数
ωi=句子中的第
i个单词
V=句中非终结符的集合
S=句子/分析树的开始符
π[i,j,X]这是一个动态规划表,这个表中记录的是从单词
ωi到单词
ωj之间包含非终结符
X的概率最大值,其中
iϵ[1,n],jϵ[1,n],i≤j且
Xϵ[ωi,ωj],XϵV
比如:
π(2,5,NP)代表的意思就是从第二个单词到第五个单词间包含非终结符
NP的最大概率。
所有有了上述定义我们就把问题归结为求解
π(1,n,S)
- 初始条件:
π(i,i,X)=q(X→ωi) 其中
(iϵ[i,n],XϵN)
如果没有存在从
X直接或间接生成
ωi的文法那么
q(X→ωi)=0
- 状态转移方程:
π(i,j,X)=maxX→YZϵR,sϵ[i...(j−1)](q(X→YZ)∗π(i,s,Y)∗π(s+1,j,Z))
这个区间
dp感觉那状态转移方程描述好苍白啊,我觉得特别像最短路的迪杰斯特拉算法,同样是跑三层的循环,其中两层负责控制区间的两个端点
i,j,第三层负责在区间中间扫一遍,看看加入
X这个非终结符后,是否存在一个新的解析方法概率更大。

上图是课件中的一个例子,我们现在要计算
π(3,8,VP),如右侧所示
VP具有两种映射方式,我们依次对每一种映射方式重复下面的过程:对于一种映射关系,我们用变量
s遍历端点
i,j的每一种情况,如上图的前三行所示,实际上一共涉及五种情况。这样这两种映射关系实际上就一共有十种情况。这十种情况都是能够计算出一个具体的概率值的,而
π(3,8,VP)取他们中最大值
CKY算法的具体实现
- 输入:一个句子
s=x1...xn和一个概率上下文无关模型(包括那五元组)
- 初始化:
π(i,i,X)=q(X→ωi)
if
X→ωiϵR
π(i,i,X)=0
otherwise
- 算法实现过程
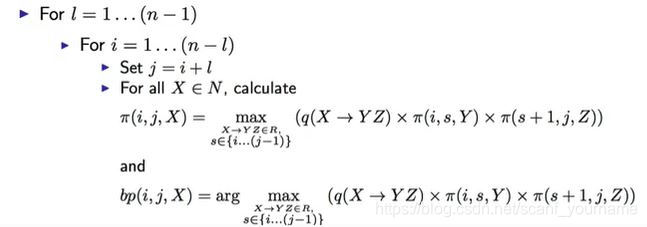
循环的最外层是区间的长度由
1到
n−1,在长度确定的条件下不断更改区间的端点并通过状态转移方程更新
π的值。这里需要注意的是在更新
π值的同时不要忘了更新它对应的分析树,因为最后我们要得到的不是最大值,而是其对用的分析树结构。