上一篇文章讲解在win系统中如何安装solr并创建一个名为test_core的Core,接下为text_core配置Ikanalyzer 分词器
1、打开text_core的instanceDir目录,并进入conf文件夹:
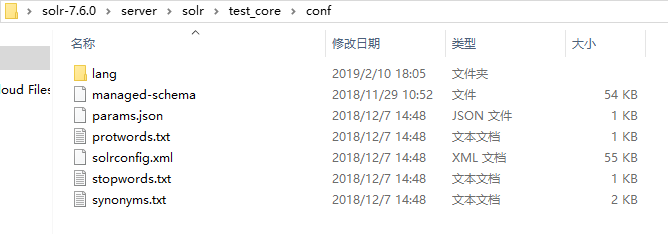
2、修改managed-schema文件,在里边添加如下配置:
<fieldType name="text_ik" class="solr.TextField"> <analyzer type="index"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" conf="ik.conf" useSmart="false"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" conf="ik.conf" useSmart="true"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
3、添加Ikanalyzer分词器的依赖jar,将下载好的jar放入如下路径:
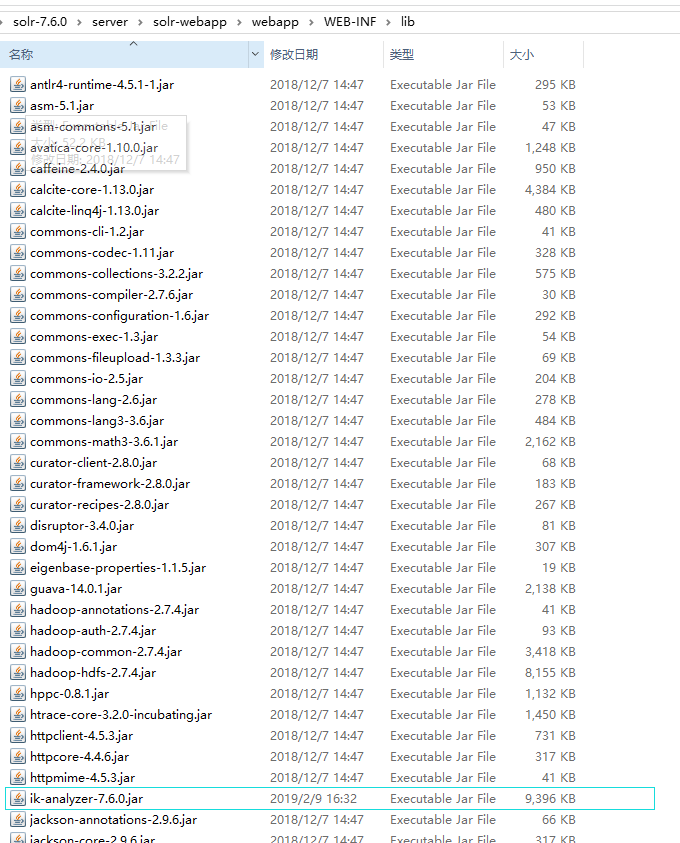
4、测试效果如下:
