Tensorflow实现神经网络
使用神经网络解决分类问题可以分为以下四个步骤:
- 提取问题中实体的特征向量作为神经网络的输入,不同的实体提取不同的特征向量
- 定义神经网络的结构,并定义如何丛神经网络的输入得到输出,这个过程就是神经网络的前向传播算法
- 通过训练数据来调整神经网络中参数的取值,这就是训练神经网络的过程
- 使用训练好的神经网络来预测未知的数据
前向传播算法
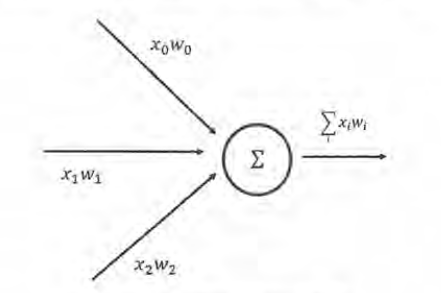
一个简单神经元结构
一个简单神经元有多个输入和一个输出,每个神经元的输入既可以是其他神经元的输出,也可以是整个神经网络的输入。所谓神经网络的结构就是指的不同神经元之间的连接结构,一个最简单神经元的输出就是输入的加权和,而不同输入的权重就是神经元的参数,神经网络的优化过程就是优化神经元中参数取值的过程
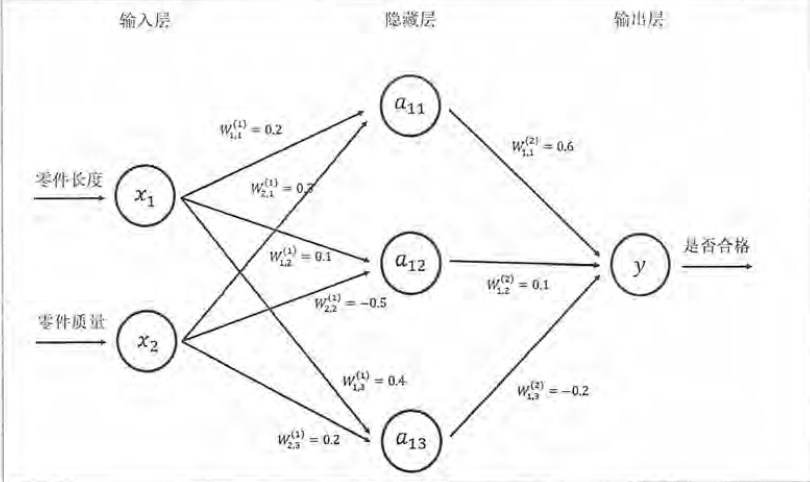
上图是三层全连接神经网络,相邻两层之间任意两个节点之间都有连接
根据权重和输入值可以确定每个神经元节点的值
给出输入层取值x1 = 0.7,x2 = 0.9
a11 = w1.1(1)*x1 + w2.1(1)*x2 = 0.41 类似a12 a13都可以得出
y= w1.1(2)a11 + w1.2(2)a12 + w1,3(2)a13 = 0.116
这个输出值大于0 所以产品合格

我们可以将它表示为矩阵乘法
输入可以表示为x = [x1,x2]
权重表示为w(1) = [w1,1(1) w1,2(1) w1,3(1) 一个2*3的矩阵
w2,1(1) w2,2(1) w2,3(1)]
a(1) = [a11, a12 , a13] = x*w(1)
类似输出层也可以表示为:
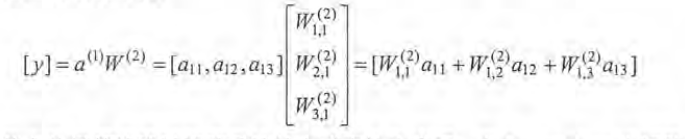
a = tf.matmul(x,w1)
y = tf.matmul(a,w2)
以上程序就实现了前向传播的过程 tf.matmul实现了矩阵乘法的功能
Tensorflow变量
在Tensorflow中,变量tf.Variable的作用就是保存和更新神经网络中的参数。一般用随机数来给变量初始化
以下代码生成一个2*3矩阵变量
weights = tf.Variable(tf.random_normal([2,3], stddev = 2))
产生的矩阵是个2*3的 矩阵中的元素是均值为0,标准差为2的随机数,tf.random_normal函数可以通过mean参数来制定平均值,没有是默认为0,通过满足正态分布的随机数来初始化神经网络比较常用
Tensorflow随机数生成函数
| 函数名称 |
随机数分布 | 主要参数 |
| tf.random_normal | 正态分布 | 平均值、标准差、取值类型 |
| tf.truncated_normal | 正态分布 产生的随机数偏离的值偏离平均值超过两个标准差将会被重新随机 | 平均值、标准差、取值类型 |
| tf.random_uniform | 平均分布 | 最小、最大取值,取值类型 |
| tf.random_gamma | Gamma分布 | 形状参数alpha、尺度参数beta、取值类型 |
Tensorflow常数生成函数
| 函数名称 | 功能 | 样列 |
| tf.zeros | 产生全0的数组 | tf.zeros([2,3],int32) -->[[0,0,0],[0,0,0]] |
| tf.ones | 产生全1的数组 | tf.ones([2,3],int32)--->[[1,1,1],[1,1,1]] |
| tf.fill | 产生一个全部为给定数字的数组 | tf.fill([2,3],9) -->[[9,9,9],[9,9,9]] |
| tf.constant | 产生一个给定值得常量 | tf.constant([1,2,3])-->[1,2,3] |
在神经网络中,偏置项(bias)通常会使用常数来设置初始值 下面代码产生一个初始值全部为0,且长度为3的变量
biases = tf.Variable(tf.zeros([3]))
一些其他设置变量的方式 w3 中是w2初始值的两倍
w2 = tf.Variable(weights.initialized_value()) w3 = tf.Variable(weights.initialized_value() * 2.0)
在Tensorflow中,一个变量的值在被使用之前,这个变量的初始化过程需要被明确的调用