目录
1、spark运行时架构

运行时架构描述:
- spark-submit启动驱动器
- 驱动器和集群管理器通信,为执行器申请资源
- 集群管理器启动执行器
不同结点的职责:
| 结点类型 |
职责 |
| 驱动器 |
|
| 执行器 |
|
| 集群管理器 |
1、启动驱动器 2、启动执行器 |
2、两种操作:转化操作和行动操作
转化操作,返回一个新的RDD/Dataframe,例如常见的转化操作包括filter、map、distinct、union等。转化操作时惰性求值,只有在行动操作中用到这些RDD/Dataframe时,才会被计算。
行动操作,是把结果返回驱动器程序或写入外部系统的操作,会触发实际的计算,例如常用的行动操作包括count、take等。每当我们调用一个新的行动操作时,整个RDD/Dataframe会从头开始计算,要避免这种低效的行为,用户可以将中间结果持久化。
3、在集群上运行应用程序
YARN集群管理器启动驱动器程序有两种模式:客户端模式(client)和集群模式(cluster)。
采用集群模式启动驱动器程序,驱动器程序会被传输并执行于主节点上:
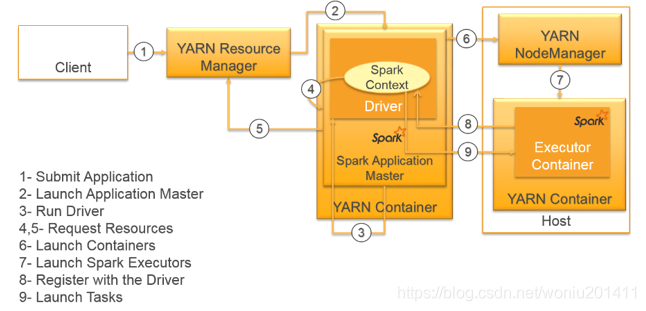
1,2:客户端提交程序给集群管理器,集群管理器启动驱动器
3:集群管理器运行驱动器程序
4,5:驱动器与集群管理器通信,为执行器申请资源
6,7:集群管理器分配资源,启动执行器
8:执行器向驱动器程序注册
9:驱动器程序为执行器节点调度任务
采用客户端模式启动驱动器程序,驱动器程序运行在spark-submit被调用的这台机器上:

1:客户端运行驱动器程序
2,3:客户端提交程序给集群管理器,集群管理器启动驱动器
4,5:驱动器与集群管理器通信,为执行器申请资源
6,7:集群管理器分配资源,启动执行器
8:执行器向驱动器程序注册
9:驱动器程序为执行器节点调度任务
如果使用客户端模式,驱动器程序运行在集群外,驱动器程序和执行器通信的时间花销会增大。
4、使用spark-submit部署应用
Spark-submit提交应用时,提供各种选项控制应用每次运行的各项细节,主要包含两类:一类是调度信息如申请的资源量,另一类是应用的运行时依赖。
运行时依赖例如:
spark-submit --deploy-mode cluster --jars /usr/lib/spark/jars/mysql-connector-java-5.1.43-bin.jar clusterStart.py
调度信息设置:
spark-submit --driver-memory 8G --executor-memory 20G --executor-cores 3 --conf spark.default.parallelism=100 clusterStart.py
通常将调度信息设置在启动集群的Configurations配置中,spark-submit会自动读取,调度信息的配置见https://blog.csdn.net/woniu201411/article/details/81985666。
参考资料:
《spark快速大数据分析》
https://amazonaws-china.com/cn/blogs/big-data/submitting-user-applications-with-spark-submit/