what is feeding?
通俗点说feed系统就是当你登陆进对应网站后:微信朋友圈的动态、人人网上看到的一件件新鲜事、新浪微博上推到你面前的一条条新围脖等等。系统中的每一条消息就是一个feed。feed的获取方式主要有两种:push(推)以及pull(拉)。也就是接下来所说的读扩散和写扩散。
feed流业务最大的特点是“我们的主页由别人发布的feed组成”,获得朋友圈消息feed流集合,从技术上说,主要有“拉取”与“推送”两种方式。feed流的推与拉主要指的是这里。
feed的特点
-
有好友关系,例如关注,粉丝
-
我们的主页由别人发布的feed组成
feed的经典动作
-
关注,取关
-
发布feed
-
拉取自己的主页feed流
feed的核心元数据
-
关系数据
-
feed数据
feeding流之读扩散?
例如:某feed系统里有ABCD四个用户,其中:
-
A关注了BC,D关注了B
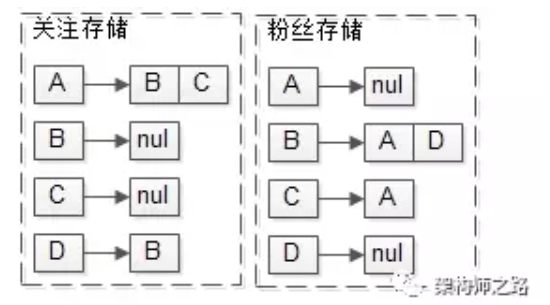
其关系存储又包含关注关系与粉丝关系,“A关注了BC,D关注了B”的潜台词是“B有两个粉丝AD,C有一个粉丝A”。
-
B发布过四条feed:msg1, msg3, msg5, msg10
-
C发布过两条feed:msg2, msg8

每一个用户,都有一个feed队列,记录自己曾经发布的所有feed数据。
在拉模式中,发布一条feed的流程非常简单,例如C新发布了一条msg12:
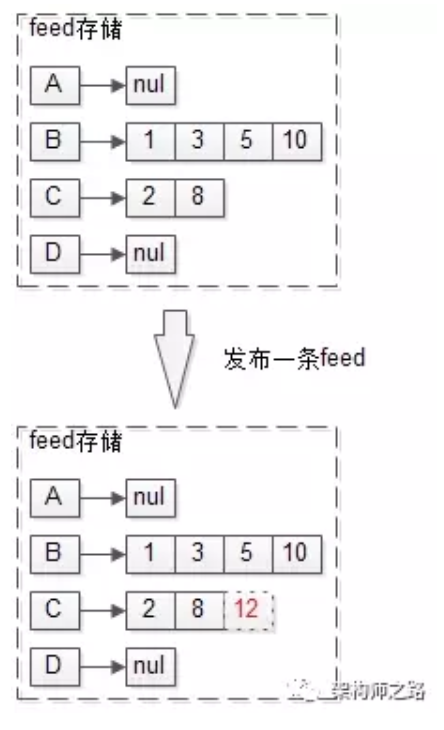
此时只需往C的feed队列里加入一条feed即可。
在拉模式中,取消关注的流程也非常简单,例如A取消关注C:
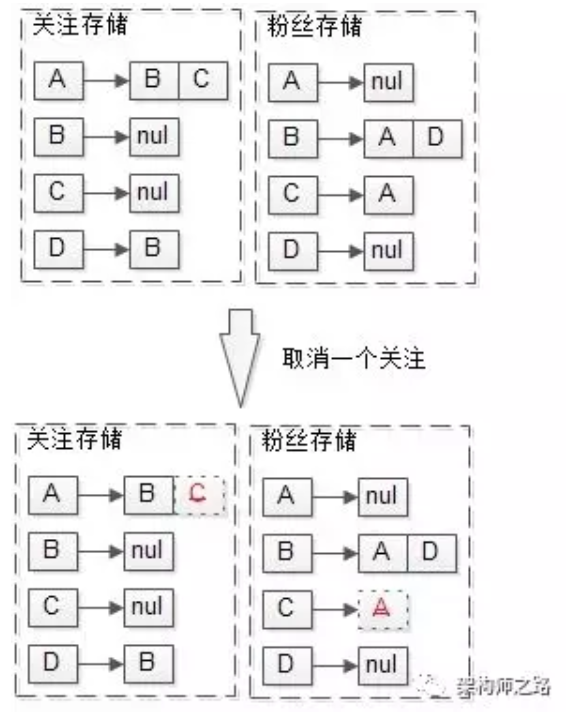
此时只需要在A的关注列表里删除C,并在C的粉丝列表里删除A即可。
在拉模式中,用户A获取“由别人发布的feed组成的主页”的过程比较复杂,此时需要:
-
-
获取A的关注列表
-
list<gz_uid> = select uid from GZ where uid=A
-
-
获取所关注的用户发布的feed
-
list<msg> = NULL;
for(uid in list<gz_uid>){
list<some_msg> =
select * from F where uid=$uid offset | limit
list<msg> += list<some_msg>;
}
-
对消息进行rank排序(假设按照发布时间排序),分页取出对应的一页feeds
sort_msg_by_time(list<msg>);
get_one_page(list<msg>, page_num);
feed流的拉模式(“读扩散”)有什么优缺点?
优点:
-
-
存储结构简单,数据存储量较小,关系数据与feed数据都只存一份
-
取消关注,发布feed的业务流程非常简单
-
存储结构,业务流程都比较容易理解,非常适合项目早期用户量、数据量、并发量不大时的快速实现
-
缺点也显而易见:
-
-
拉取朋友圈feed流列表的业务流程非常复杂
-
有多次数据访问,并且要进行大量的内存计算,大量数据的网络传输,性能较低
-
在拉模式中,系统的瓶颈容易出现在“用户所发布feed列表”的读取上,而每个用户发布feed的频率其实是很低的,此时,架构优化的核心是通过缓存降低数据存储磁盘IO。
当用户量、数据量、并发量数据逐步增加之后,拉模式会慢慢扛不住了,需要升级优化,但对于“取消关注”与“发布feed”这两个写流程又会有冲击和影响。
feeding流之写扩散?
推模式(写扩散),关系数据的存储与拉模式(读扩散)完全一样。
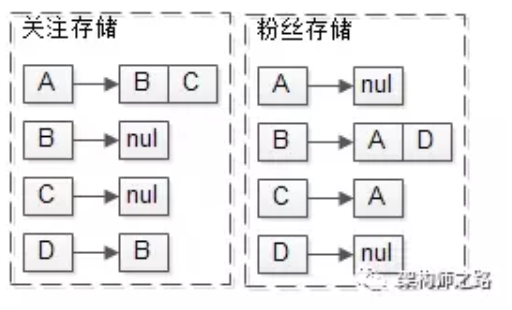
feed数据,每个用户也存储自己发布的feed。
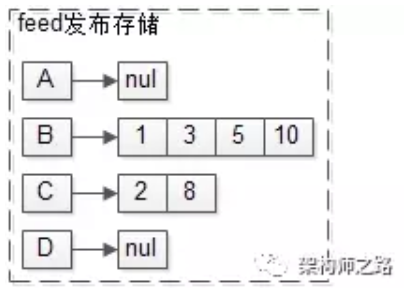
如上图:
-
-
B曾经发布过1,3,5,10
-
C曾经发布过2,8
-
画外音:不妨设,这里的msgid按照feed的发布时间偏序。
feed数据存储,与拉(读扩散)不同的是,每个用户还需要存储自己收到的feed流。
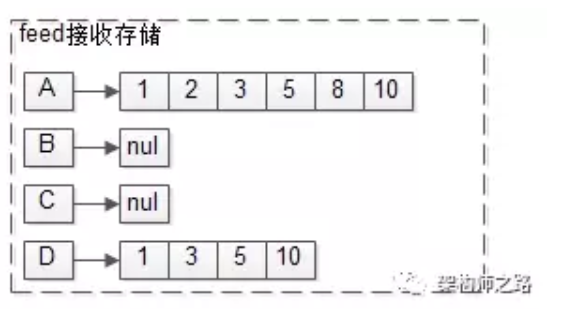
如上图:
-
-
A关注了BC,所以A的接收队列是1,2,3,5,8,10
-
D关注了B,所以D的接受队列是1,3,5,10
-
在推模式(写扩散)中,获取“由别人发布的feed组成的主页”会变得异常简单,假设一页消息为3条feed,A如果要看自己朋友圈的第二页消息,直接返回1,2,3即可。
画外音:第一页朋友圈是最新的消息,即5,8,10。
在推模式(写扩散)中,发布一条feed的流程会更复杂一点。
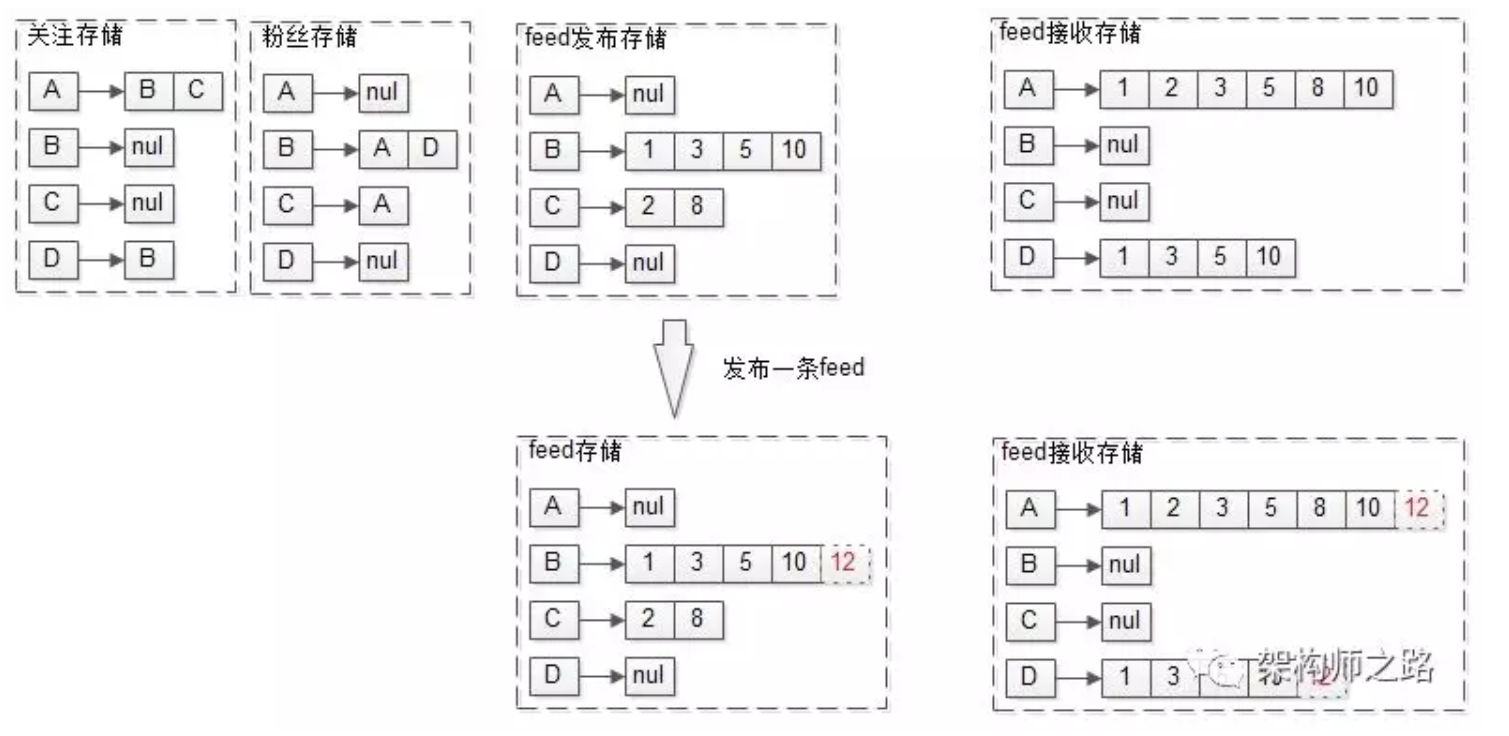
例如B新发布了一条msg12:
-
-
在B的发布feed存储里加入消息12
-
查询B全部粉丝AD
-
在粉丝AD的接收feed存储里也加入消息12
-
之所以该方案称为推模式(写扩散),就是因为,用户发布feed的时候:
-
-
直接将feed推到了粉丝的接收列表里,故称为“推模式”
-
不止写发布feed存储,而且要写多个粉丝的接收feed存储,故称为“写扩散”
-
在推模式(写扩散)中,添加关注的流程也会变得复杂。
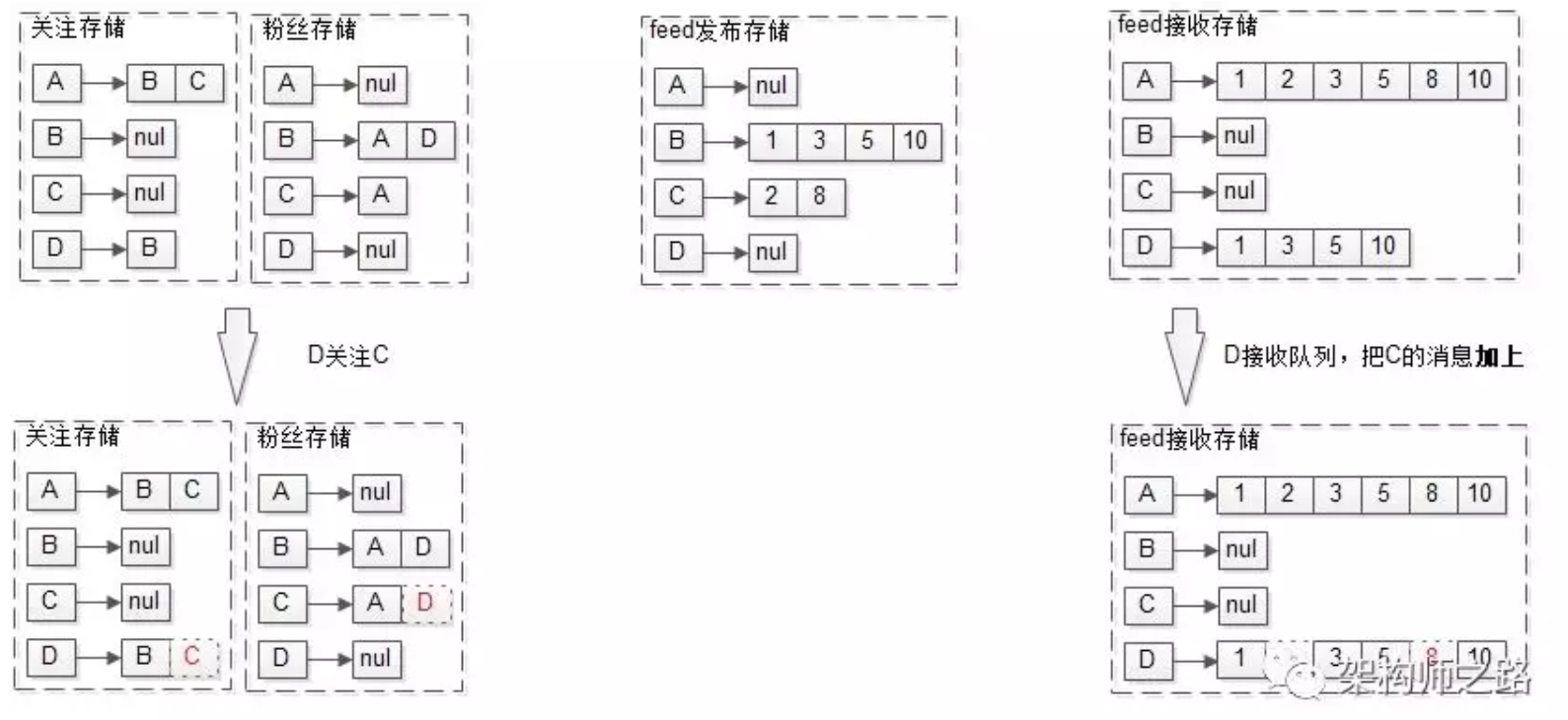
例如D新增关注C:
-
-
在D的关注存储里添加C
-
在C的粉丝存储里添加D
-
在D的接收feed存储里加入C发布的feed
-
画外音:有些产品有这样的逻辑,“关注之后才能看到feed”,这样的话就不需要第三步,旧feed无需插入。
在推模式(写扩散)中,取消关注的流程也会变得复杂。

例如A取消关注C:
-
-
在A的关注存储里删除C
-
在C的粉丝存储里删除A
-
在A的接收feed存储里删除C发布的feed
-
feed流的推模式(写扩散)的优点是:
-
-
消除了拉模式(读扩散)的IO集中点,每个用户都读自己的数据,高并发下锁竞争少
-
画外音:拉模式(读扩散)中,用户发布feed存储容易称为IO瓶颈。
-
-
拉取朋友圈feed流列表的业务流程异常简单,速度很快
-
拉取朋友圈feed流列表,不需要进行大量的内存计算,网络传输,性能很高
-
画外音:feed业务是典型的读多写少业务场景,读写比甚至高于100:1,即平均发布1条消息,有至少100次阅读。
其缺点是:
-
-
极大极大消耗存储资源,feed数据会存储很多份,例如杨幂5KW粉丝,她每次一发博文,消息会冗余5KW份
-
画外音:有朋友提出,可以存储一份消息实体,只冗余msgid,这样的话,拉取feed流列表时,还要再次拉取实体,网络时延会更长,所以很多公司选择直接冗余消息实体,当然,这是一个用户体验与存储量的折衷设计。
-
-
新增关注,取消关注,发布feed的业务流会更复杂
-
小结
feed流业务的推拉模式小结:
-
-
拉模式,读扩散,feed存一份,存储小,用户集中访问数据,性能差
-
推模式,写扩散,feed存多份,用冗余存储换锁冲突,性能高
-