说在前面
同一个算法本身存在各种不同的变体,即各种改进版本。一句话+一张图并不能涵盖所有情况,只是尽量用通俗的语言介绍其中经典的算法版本。希望对某算法本身不了解的人看完能迅速get到该算法在干什么;二刷该算法的人能够迅速回忆起算法核心思想和做法,做到能随口讲给别人听。
往期回顾
【机器学习-分类】一句话+一张图 说清楚kNN算法(附案例+代码)
一句话
决策树算法是,通过决定性特征学习数据集中的规则,对未知数据集进行划分的算法;其中叶子节点为决策(分类)结果,非叶子节点为选择进行划分的特征(决定性特征、最优特征)。
一张图
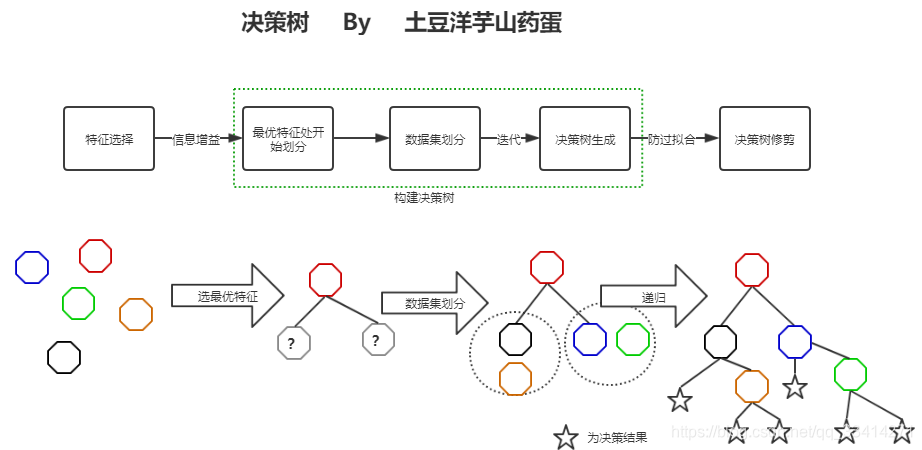
图中关键信息
1.通过信息增益选取最优特征。
2.选择了最优特征还需对数据集进行划分,有时候分类不止两个类别。
3.对决策树进行剪枝,防止过拟合。
案例+代码
根据上面建立决策树的步骤,可以先来看看通用的函数。
1.计算信息熵
def calcShannonEnt(dataSet):
"""calcShannonEnt(calculate Shannon entropy 计算给定数据集的香农熵)
Args:
dataSet 数据集
Returns:
返回 每一组feature下的某个分类下,香农熵的信息期望
"""
# -----------计算香农熵的第一种实现方式start--------------------------------------------------------------------------------
# 求list的长度,表示计算参与训练的数据量
numEntries = len(dataSet)
# 下面输出我们测试的数据集的一些信息
# 例如:<type 'list'> numEntries: 5 是下面的代码的输出
# print type(dataSet), 'numEntries: ', numEntries
# 计算分类标签label出现的次数
labelCounts = {}
# the the number of unique elements and their occurance
for featVec in dataSet:
# 将当前实例的标签存储,即每一行数据的最后一个数据代表的是标签
currentLabel = featVec[-1]
# 为所有可能的分类创建字典,如果当前的键值不存在,则扩展字典并将当前键值加入字典。每个键值都记录了当前类别出现的次数。
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
# print '-----', featVec, labelCounts
# 对于label标签的占比,求出label标签的香农熵
shannonEnt = 0.0
for key in labelCounts:
# 使用所有类标签的发生频率计算类别出现的概率。
prob = float(labelCounts[key])/numEntries
# log base 2
# 计算香农熵,以 2 为底求对数
shannonEnt -= prob * log(prob, 2)
# print '---', prob, prob * log(prob, 2), shannonEnt
# -----------计算香农熵的第一种实现方式end--------------------------------------------------------------------------------
# # -----------计算香农熵的第二种实现方式start--------------------------------------------------------------------------------
# # 统计标签出现的次数
# label_count = Counter(data[-1] for data in dataSet)
# # 计算概率
# probs = [p[1] / len(dataSet) for p in label_count.items()]
# # 计算香农熵
# shannonEnt = sum([-p * log(p, 2) for p in probs])
# # -----------计算香农熵的第二种实现方式end--------------------------------------------------------------------------------
return shannonEnt
2.选择最优特征或出现次数最多的类别
一般情况下我们希望不断迭代的选择最优特征分类可以使最后某类别情况下的分类是唯一的,但要是划不到唯一可以用出现次数最大多的类别当做此类类别。
def chooseBestFeatureToSplit(dataSet):
"""chooseBestFeatureToSplit(选择最好的特征)
Args:
dataSet 数据集
Returns:
bestFeature 最优的特征列
"""
# -----------选择最优特征的第一种方式 start------------------------------------
# 求第一行有多少列的 Feature, 最后一列是label列嘛
numFeatures = len(dataSet[0]) - 1
# label的信息熵
baseEntropy = calcShannonEnt(dataSet)
# 最优的信息增益值, 和最优的Featurn编号
bestInfoGain, bestFeature = 0.0, -1
# iterate over all the features
for i in range(numFeatures):
# create a list of all the examples of this feature
# 获取每一个实例的第i+1个feature,组成list集合
featList = [example[i] for example in dataSet]
# get a set of unique values
# 获取剔重后的集合,使用set对list数据进行去重
uniqueVals = set(featList)
# 创建一个临时的信息熵
newEntropy = 0.0
# 遍历某一列的value集合,计算该列的信息熵
# 遍历当前特征中的所有唯一属性值,对每个唯一属性值划分一次数据集,计算数据集的新熵值,并对所有唯一特征值得到的熵求和。
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
# gain[信息增益]: 划分数据集前后的信息变化, 获取信息熵最大的值
# 信息增益是熵的减少或者是数据无序度的减少。最后,比较所有特征中的信息增益,返回最好特征划分的索引值。
infoGain = baseEntropy - newEntropy
print('infoGain=', infoGain, 'bestFeature=', i, baseEntropy, newEntropy)
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
# -----------选择最优特征的第一种方式 end------------------------------------
# # -----------选择最优特征的第二种方式 start------------------------------------
# # 计算初始香农熵
# base_entropy = calcShannonEnt(dataSet)
# best_info_gain = 0
# best_feature = -1
# # 遍历每一个特征
# for i in range(len(dataSet[0]) - 1):
# # 对当前特征进行统计
# feature_count = Counter([data[i] for data in dataSet])
# # 计算分割后的香农熵
# new_entropy = sum(feature[1] / float(len(dataSet)) * calcShannonEnt(splitDataSet(dataSet, i, feature[0])) \
# for feature in feature_count.items())
# # 更新值
# info_gain = base_entropy - new_entropy
# print('No. {0} feature info gain is {1:.3f}'.format(i, info_gain))
# if info_gain > best_info_gain:
# best_info_gain = info_gain
# best_feature = i
# return best_feature
# # -----------选择最优特征的第二种方式 end------------------------------------
def majorityCnt(classList):
"""majorityCnt(选择出现次数最多的一个结果)
Args:
classList label列的集合
Returns:
bestFeature 最优的特征列
"""
# -----------majorityCnt的第一种方式 start------------------------------------
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
# 倒叙排列classCount得到一个字典集合,然后取出第一个就是结果(yes/no),即出现次数最多的结果
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
# print 'sortedClassCount:', sortedClassCount
return sortedClassCount[0][0]
# -----------majorityCnt的第一种方式 end------------------------------------
# # -----------majorityCnt的第二种方式 start------------------------------------
# major_label = Counter(classList).most_common(1)[0]
# return major_label
# # -----------majorityCnt的第二种方式 end------------------------------------
3.分割数据集
主要是为了去除那些已经选过为最优特征对应的那列数据,用剩下数据继续建树。
python小知识:extend和append的区别
list.append(object) 向列表中添加一个对象object
list.extend(sequence) 把一个序列seq的内容添加到列表中
1、使用append的时候,是将new_media看作一个对象,整体打包添加到music_media对象中。
2、使用extend的时候,是将new_media看作一个序列,将这个序列和music_media序列合并,并放在其后面。
result = []
result.extend([1,2,3])
print result
result.append([4,5,6])
print result
result.extend([7,8,9])
print result
结果:
[1, 2, 3]
[1, 2, 3, [4, 5, 6]]
[1, 2, 3, [4, 5, 6], 7, 8, 9]
def splitDataSet(dataSet, index, value):
"""splitDataSet去除那些已经选过为最优特征对应的那列数据,用剩下数据继续建树。
Args:
dataSet 数据集 待划分的数据集
index 表示每一行的index列 划分数据集的特征
value 表示index列对应的value值 需要返回的特征的值。
Returns:
index列为value的数据集【该数据集需要排除index列】
"""
# -----------切分数据集的第一种方式 start------------------------------------
retDataSet = []
for featVec in dataSet:
# index列为value的数据集【该数据集需要排除index列】
# 判断index列的值是否为value
if featVec[index] == value:
# chop out index used for splitting
# [:index]表示前index行,即若 index 为2,就是取 featVec 的前 index 行
reducedFeatVec = featVec[:index]
reducedFeatVec.extend(featVec[index+1:])
# [index+1:]表示从跳过 index 的 index+1行,取接下来的数据
# 收集结果值 index列为value的行【该行需要排除index列】
retDataSet.append(reducedFeatVec)
# -----------切分数据集的第一种方式 end------------------------------------
# # -----------切分数据集的第二种方式 start------------------------------------
# retDataSet = [data for data in dataSet for i, v in enumerate(data) if i == axis and v == value]
# # -----------切分数据集的第二种方式 end------------------------------------
return retDataSet
4.建树
构建决策树
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
# 如果数据集的最后一列的第一个值出现的次数=整个集合的数量,也就说只有一个类别,就只直接返回结果就行
# 第一个停止条件:所有的类标签完全相同,则直接返回该类标签。
# count() 函数是统计括号中的值在list中出现的次数
if classList.count(classList[0]) == len(classList):
return classList[0]
# 如果数据集只有1列,那么最初出现label次数最多的一类,作为结果
# 第二个停止条件:使用完了所有特征,仍然不能将数据集划分成仅包含唯一类别的分组。
if len(dataSet[0]) == 1:
return majorityCnt(classList)
# 选择最优的列,得到最优列对应的label含义
bestFeat = chooseBestFeatureToSplit(dataSet)
# 获取label的名称
bestFeatLabel = labels[bestFeat]
# 初始化myTree
myTree = {bestFeatLabel: {}}
# 注:labels列表是可变对象,在PYTHON函数中作为参数时传址引用,能够被全局修改
# 所以这行代码导致函数外的同名变量被删除了元素,造成例句无法执行,提示'no surfacing' is not in list
del(labels[bestFeat])
# 取出最优列,然后它的branch做分类
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
# 求出剩余的标签label
subLabels = labels[:]
# 遍历当前选择特征包含的所有属性值,在每个数据集划分上递归调用函数createTree()
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
# print 'myTree', value, myTree
return myTree
5.分类
利用决策树进行分类
def classify(inputTree, featLabels, testVec):
"""classify(给输入的节点,进行分类)
Args:
inputTree 决策树模型
featLabels Feature标签对应的名称
testVec 测试输入的数据
Returns:
classLabel 分类的结果值,需要映射label才能知道名称
"""
# 获取tree的根节点对于的key值
firstStr = list(inputTree.keys())[0]
# 通过key得到根节点对应的value
secondDict = inputTree[firstStr]
# 判断根节点名称获取根节点在label中的先后顺序,这样就知道输入的testVec怎么开始对照树来做分类
featIndex = featLabels.index(firstStr)
# 测试数据,找到根节点对应的label位置,也就知道从输入的数据的第几位来开始分类
key = testVec[featIndex]
valueOfFeat = secondDict[key]
print('+++', firstStr, 'xxx', secondDict, '---', key, '>>>', valueOfFeat)
# 判断分枝是否结束: 判断valueOfFeat是否是dict类型
if isinstance(valueOfFeat, dict):
classLabel = classify(valueOfFeat, featLabels, testVec)
else:
classLabel = valueOfFeat
return classLabel
6.获得树高
def get_tree_height(tree):
"""
Desc:
递归获得决策树的高度
Args:
tree
Returns:
树高
"""
if not isinstance(tree, dict):
return 1
child_trees = list(tree.values())[0].values()
# 遍历子树, 获得子树的最大高度
max_height = 0
for child_tree in child_trees:
child_tree_height = get_tree_height(child_tree)
if child_tree_height > max_height:
max_height = child_tree_height
return max_height + 1
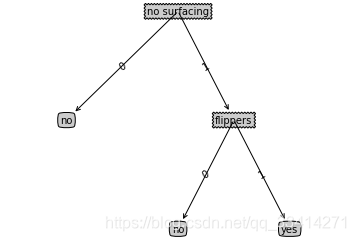
案例:判断海洋中的生物是否为鱼类
特征有两个:是否浮出水面才能生存;是否有脚蹼。
1.准备数据
def createDataSet():
"""DateSet 基础数据集
Args:
无需传入参数
Returns:
返回数据集和对应的label标签
"""
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
# dataSet = [['yes'],
# ['yes'],
# ['no'],
# ['no'],
# ['no']]
# labels 露出水面 脚蹼
labels = ['no surfacing', 'flippers']
# change to discrete values
return dataSet, labels
2.测试
def fishTest():
# 1.创建数据和结果标签
myDat, labels = createDataSet()
# print myDat, labels
# 计算label分类标签的香农熵
# calcShannonEnt(myDat)
# # 求第0列 为 1/0的列的数据集【排除第0列】
# print '1---', splitDataSet(myDat, 0, 1)
# print '0---', splitDataSet(myDat, 0, 0)
# # 计算最好的信息增益的列
# print chooseBestFeatureToSplit(myDat)
import copy
myTree = createTree(myDat, copy.deepcopy(labels))
print(myTree)
# [1, 1]表示要取的分支上的节点位置,对应的结果值
print(classify(myTree, labels, [1, 1]))
# 获得树的高度
print(get_tree_height(myTree))
# 画图可视化展现
dtPlot.createPlot(myTree)
运行结果
参考文献
《机器学习实战》
ApacheCN
里面使用了画图的程序,如果需要可以评论区留言哦
系统性学习
如果想了解和系统学习更多机器学习理论和项目实践,CSDN学院中有一系列精品AI课,分为大课和小课,包含数学基础、Python基础、算法和企业级项目 等,适合并不同类型的人群,值得拥有!
CSDN学院⼤课链接:
https://edu.csdn.net/topic/ai30?utm_source=lqy
CSDN学院⼩课链接:
https://edu.csdn.net/course/detail/6601?utm_source=lqy