1.建立数据对象模型
Django通过自定义python类的形式来定义具体的模型,每个模型代表数据库中的一张表,每个类的实例代表数据表中的一行数据,类中的每个变量代表数据表中的一列字段。Django通过ORM对数据库进行操作,奉行代码优先的理念,将python程序员和数据库管理员进行分工解耦。
假如我们创建两个对象,一个User,一个Diary,以表征用户和日志
from django.db import models
# 设置对象结构(对应数据库的结构)
class User(models.Model):
username = models.CharField(max_length=200) # 字符串类型字段
password = models.CharField(max_length=200) # 整数类型字段
age = models.IntegerField(default=0) # 整数类型字段
date = models.DateField('date registered') # 时间类型字段,参数为人类可读的字段名
class Diary(models.Model):
user = models.ForeignKey(User, on_delete=models.CASCADE) # 外键
content = models.TextField() # 文本类型字段
相当于
CREATE TABLE app1_user (
"id" serial NOT NULL PRIMARY KEY,
"username" varchar(200) NOT NULL,
"password" varchar(200) NOT NULL,
"age" Int(11) NOT NULL,
"date" Date NOT NULL
);
表名
表名app1_user由Django自动生成:app名+下划线+小写class名。你可以使用模型元数据Meta重写这部分功能的机制。后面我们学习关于元数据Meta的相关知识。
主键
Django默认自动创建自增主键id,当然,你也可以自己指定主键。
id = models.AutoField(primary_key=True)
这是一个自增字段,从1开始计数。如果你非要自己设置主键,那么请务必将字段设置为primary_key=True。Django在一个模型中只允许有一个自增字段,并且该字段必须为主键!
字段类型
每一个类都是django.db.models.Model的子类。每一个字段都是Field类的一个实例,例如用于保存字符数据的CharField和用于保存时间类型的DateTimeField,它们告诉Django每一个字段保存的数据类型。
Django内置了许多字段类型,它们都位于django.db.models中,例如models.CharField。这些类型基本满足需求,如果还不够,你也可以自定义字段。
常用字段类型:
| 类型 | 说明 |
|---|---|
| AutoField | 一个自动增加的整数类型字段。通常你不需要自己编写它,Django会自动帮你添加字段:id = models.AutoField(primary_key=True),这是一个自增字段,从1开始计数。如果你非要自己设置主键,那么请务必将字段设置为primary_key=True。Django在一个模型中只允许有一个自增字段,并且该字段必须为主键! |
| CharField | 字符串类型。必须接收一个max_length参数,表示字符串长度不能超过该值。默认的表单标签是input text。最常用的filed,没有之一! |
| DateField | class DateField(auto_now=False, auto_now_add=False, **options)日期类型。一个Python中的datetime.date的实例。在HTML中表现为TextInput标签。在admin后台中,Django会帮你自动添加一个JS的日历表和一个“Today”快捷方式,以及附加的日期合法性验证。两个重要参数:(参数互斥,不能共存) auto_now:每当对象被保存时将字段设为当前日期,常用于保存最后修改时间。auto_now_add:每当对象被创建时,设为当前日期,常用于保存创建日期(注意,它是不可修改的)。设置上面两个参数就相当于给field添加了editable=False和blank=True属性。如果想具有修改属性,请用default参数。例子:pub_time = models.DateField(auto_now_add=True),自动添加发布时间。 |
| BooleanField | 布尔值类型。默认值是None。在HTML表单中体现为CheckboxInput标签。如果要接收null值,请使用NullBooleanField。 |
| DateTimeField | 日期时间类型。Python的datetime.datetime的实例。与DateField相比就是多了小时、分和秒的显示,其它功能、参数、用法、默认值等等都一样。 |
| TimeField | 时间字段,Python中datetime.time的实例。接收同DateField一样的参数,只作用于小时、分和秒。 |
| EmailField | 邮箱类型,默认max_length最大长度254位。使用这个字段的好处是,可以使用DJango内置的EmailValidator进行邮箱地址合法性验证。 |
| FloatField | 浮点数类型,参考整数类型 |
| IntegerField | 整数类型,最常用的字段之一。取值范围-2147483648到2147483647。在HTML中表现为NumberInput标签。 |
| GenericIPAddressField | class GenericIPAddressField(protocol=’both’, unpack_ipv4=False, **options)[source],IPV4或者IPV6地址,字符串形式,例如192.0.2.30或者2a02:42fe::4在HTML中表现为TextInput标签。参数protocol默认值为‘both’,可选‘IPv4’或者‘IPv6’,表示你的IP地址类型。 |
| TextField | 大量文本内容,在HTML中表现为Textarea标签,最常用的字段类型之一!如果你为它设置一个max_length参数,那么在前端页面中会受到输入字符数量限制,然而在模型和数据库层面却不受影响。只有CharField才能同时作用于两者。 |
| URLField | 一个用于保存URL地址的字符串类型,默认最大长度200。 |
字段名称
每一个 Field 实例的名字就是字段的名字(如: username 或者 date )。在你的Python代码中会使用这个值,你的数据库也会将这个值作为表的列名。
你也可以在每个Field中使用一个可选的第一位置参数用于提供一个人类可读的字段名,让你的模型更友好,更易读,并且将被作为文档的一部分来增强代码的可读性。对于模型中的其他字段,机器名称就已经足够我们可读了。
字段参数
一些Field类必须提供某些特定的参数。例如CharField需要你指定max_length。这不仅是数据库结构的需要,同样也用于我们后面会谈到的数据验证功能。
- null:该值为True时,Django在数据库用NULL保存空值。默认值为False。对于保存字符串类型数据的字段,请尽量避免将此参数设为True,那样会导致两种‘没有数据’的情况,一种是NULL,另一种是‘空字符串’。
- blank:True时,字段可以为空。默认False。和null参数不同的是,null是纯数据库层面的,而blank是验证相关的,它与表单验证是否允许输入框内为空有关,与数据库无关。所以要小心一个null为False,blank为True的字段接收到一个空值可能会出bug或异常。
- choices:可选值列表。用于页面上的选择框标签,需要先提供一个二维的二元元组,第一个元素表示存在数据库内真实的值,第二个表示页面上显示的具体内容。在浏览器页面上将显示第二个元素的值。例如:
class Person(models.Model):
SHIRT_SIZES = (
('S', 'Small'),
('M', 'Medium'),
('L', 'Large'),
)
name = models.CharField(max_length=60)
shirt_size = models.CharField(max_length=1, choices=SHIRT_SIZES)
views中使用:
p = Person(name="Fred Flintstone", shirt_size="L")
- db_column:该参数用于定义当前字段在数据表内的列名。如果未指定,Django将使用字段名作为列名。
- db_index:该参数接收布尔值。如果为True,数据库将为该字段创建索引。
- default:字段的默认值,可以是值或者一个可调用对象。如果是可调用对象,那么每次创建新对象时都会调用。设置的默认值不能是一个可变对象,比如列表、集合等等。lambda匿名函数也不可用于default的调用对象,因为匿名函数不能被migrations序列化。注意:在某种原因不明的情况下将default设置为None,可能会引发intergyerror:not null constraint failed,即非空约束失败异常,导致python manage.py migrate失败,此时可将None改为False或其它的值,只要不是None就行。
- editable:如果设为False,那么当前字段将不会在admin后台或者其它的ModelForm表单中显示,同时还会被模型验证功能跳过。参数默认值为True。
- help_text:额外显示在表单部件上的帮助文本。使用时请注意转义为纯文本,防止脚本攻击。
- verbose_name:为字段设置一个人类可读,更加直观的别名。
- primary_key:如果你没有给模型的任何字段设置这个参数为True,Django将自动创建一个AutoField自增字段,名为‘id’,并设置为主键。也就是
id = models.AutoField(primary_key=True)。如果你为某个字段设置了primary_key=True,则当前字段变为主键,并关闭Django自动生成id主键的功能。primary_key=True隐含null=False和unique=True的意思。一个模型中只能有一个主键字段!另外,主键字段不可修改,如果你给某个对象的主键赋个新值实际上是创建一个新对象,并不会修改原来的对象。
关系类型
Django支持通用的关系类型:
一、多对一(ForeignKey)
多对一的关系,通常被称为外键。
class ForeignKey(to, on_delete, **options)[source]
外键需要两个位置参数,一个是关联的模型,另一个是on_delete选项。
on_delete有CASCADE、PROTECT、SET_NULL、SET_DEFAULT、SET()五个可选择的值
- CASCADE:此值设置,是级联删除。,也就是当删除主表的数据时候从表中的数据也随着一起删除.
- PROTECT:此值设置,是会报完整性错误。
- SET_NULL:此值设置,会把外键设置为null,前提是允许为null
- SET_DEFAULT:此值设置,会把设置为外键的默认值。
- SET():此值设置,会调用外面的值,可以是一个函数。
注意:外键要定义在‘多’的一方!!!。我们使用ForeignKey在Diary中定义了一个外键关系。它告诉Django,每一个Diary关联到一个对应的User。
二、多对多(ManyToManyField)
三、一对一(OneToOneField)
模型的元数据Meta
模型的元数据,指的是“除了字段外的所有内容”,例如排序方式、数据库表名、人类可读的单数或者复数名等等。所有的这些都是非必须的,甚至元数据本身对模型也是非必须的。但是,我要说但是,有些元数据选项能给予你极大的帮助,在实际使用中具有重要的作用,是实际应用的‘必须’。
想在模型中增加元数据,方法很简单,在模型类中添加一个子类,名字是固定的Meta,然后在这个Meta类下面增加各种元数据选项或者说设置项。参考下面的例子:
class Diary(models.Model):
user = models.ForeignKey(User, on_delete=models.CASCADE) # 外键。
content = models.TextField() # 文本类型字段
# 模型的元数据Meta
class Meta: # 注意,是模型的子类,要缩进!
ordering = ["id"]
db_table = 'diary'
强调:每个模型都可以有自己的元数据类,每个元数据类也只对自己所在模型起作用。
- app_label:如果定义了模型的app没有在INSTALLED_APPS中注册,则必须通过此元选项声明它属于哪个app。
- abstract:如果abstract=True,那么模型会被认为是一个抽象模型。抽象模型本身不实际生成数据库表,而是作为其它模型的父类,被继承使用。具体内容可以参考Django模型的继承。
- db_table:指定在数据库中,当前模型生成的数据表的表名。友情建议:使用MySQL数据库时,db_table用小写英文。
- db_tablespace:自定义数据库表空间的名字。默认值是工程的DEFAULT_TABLESPACE设置。
- get_latest_by:Django管理器给我们提供有latest()和earliest()方法,分别表示获取最近一个和最前一个数据对象。get_latest_by元数据选项可以指定一个类似 DateField、DateTimeField或者IntegerField这种可以排序的字段,作为latest()和earliest()方法的排序依据,从而得出最近一个或最前面一个对象。
- ordering:用于指定该模型生成的所有对象的排序方式,接收一个字段名组成的元组或列表。默认按升序排列,如果在字段名前加上字符“-”则表示按降序排列,如果使用字符问号“?”表示随机排列。请看下面的例子:
ordering = ['pub_date'] # 表示按'pub_date'字段进行升序排列
ordering = ['-pub_date'] # 表示按'pub_date'字段进行降序排列
ordering = ['-pub_date', 'author'] # 表示先按'pub_date'字段进行降序排列,再按`author`字段进行升序排列。
- default_permissions:Django默认给所有的模型设置(‘add’, ‘change’, ‘delete’)的权限,也就是增删改。你可以自定义这个选项,比如设置为一个空列表,表示你不需要默认的权限,但是这一操作必须在执行migrate命令之前。
- required_db_vendor:声明模型支持的数据库。Django默认支持sqlite, postgresql, mysql, oracle。
- unique_together:这个元数据是非常重要的一个!它等同于数据库的联合约束!unique_together接收一个二维的元组((xx,xx,xx,…),(),(),()…),每一个元素都是一个元组,表示一组联合唯一约束,可以同时设置多组约束。例如下面的代码新添加的记录如果和已存在的记录username和password两个字段都相同时无法添加,当age和date两个字段都相同时也无法添加。
unique_together = (('username', 'password',),( 'age','date'),) # 联合唯一,当任一元组参数中所有字段都相同时无法添加
- verbose_name:最常用的元数据之一!用于设置模型对象的直观、人类可读的名称。可以用中文。如果你不指定它,那么Django会使用小写的模型名作为默认值。
- label:等同于app_label.object_name。例如app1.User,app1是应用名,User是模型名。这个属性为只读。
2.激活数据类型
上面的代码看着有点少,但却给予Django大量的信息,据此,Django会做下面两件事:
- 创建该app对应的数据库表结构
- 为User和Diary对象创建基于python的数据库访问API
1.将自定义的数据结构更新到项目修改记录中,以便提供基于python的数据库访问api。在cmd窗口中先cd到manage.py目录下,再执行以下命令
python manage.py makemigrations app1
如果你是以pycharm打开的项目。
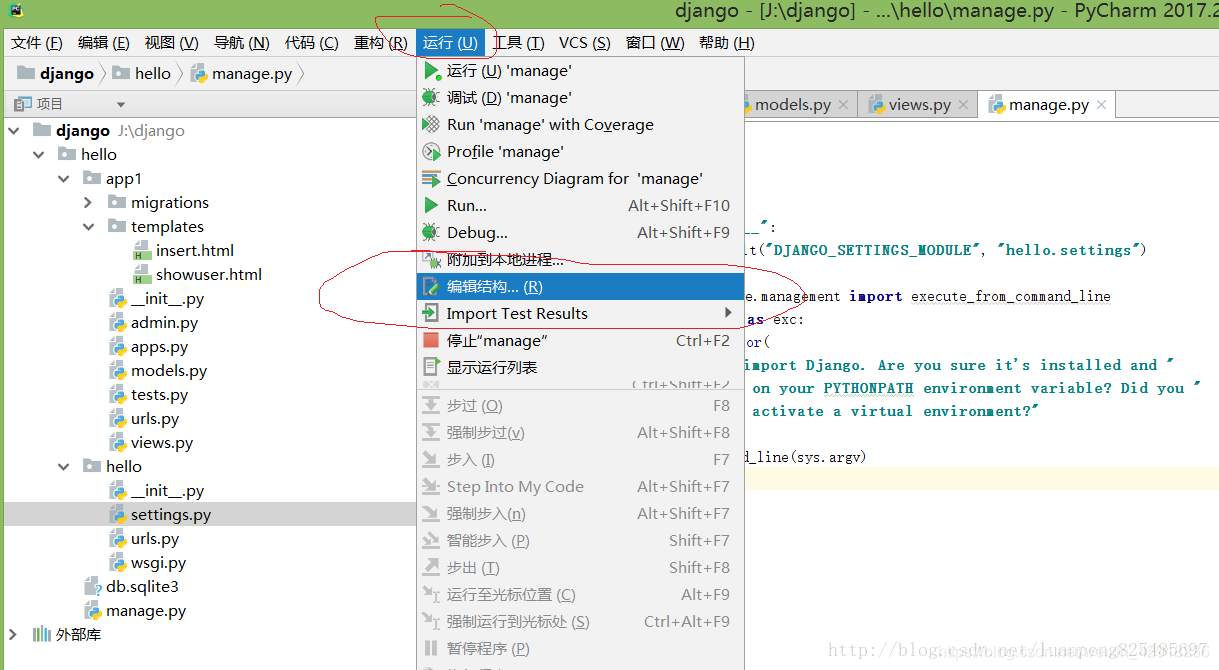
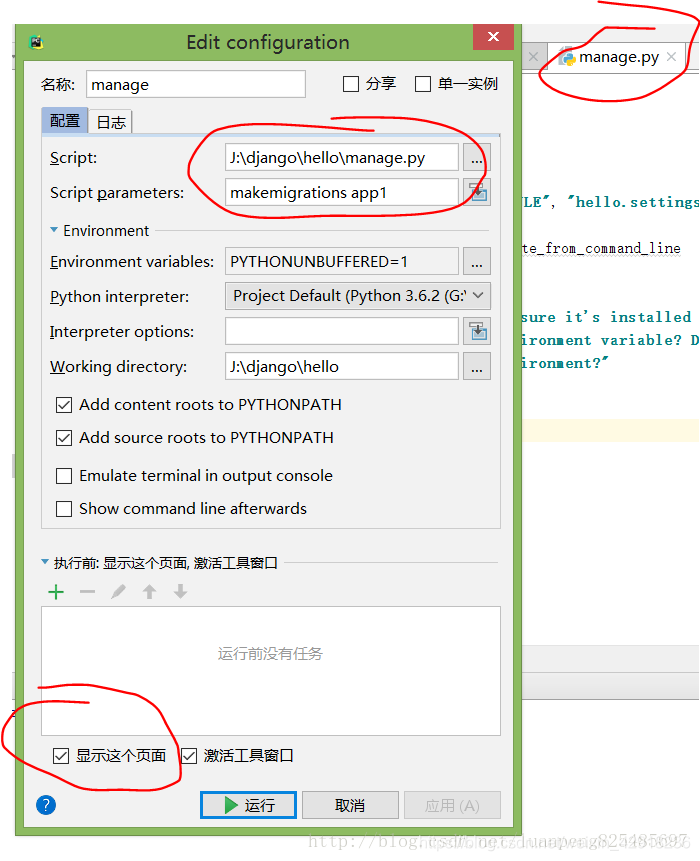
2.将数据结构更新到数据库
当你每次在INSTALLED_APPS处增加新的APP时,请务必执行命令
python manage.py migrate
将数据结构更新到数据库中。有可能要先make migtrations。
如果你是以pycharm打开的项目。
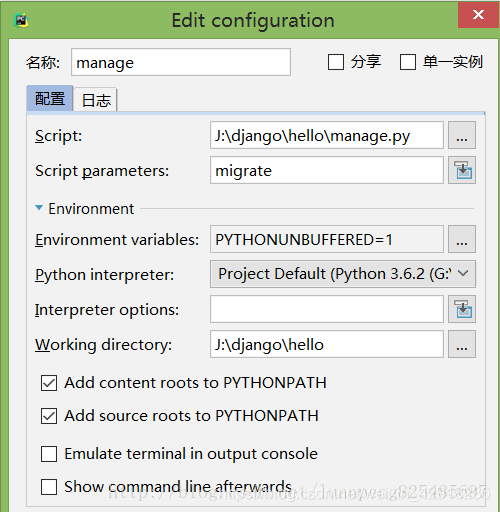
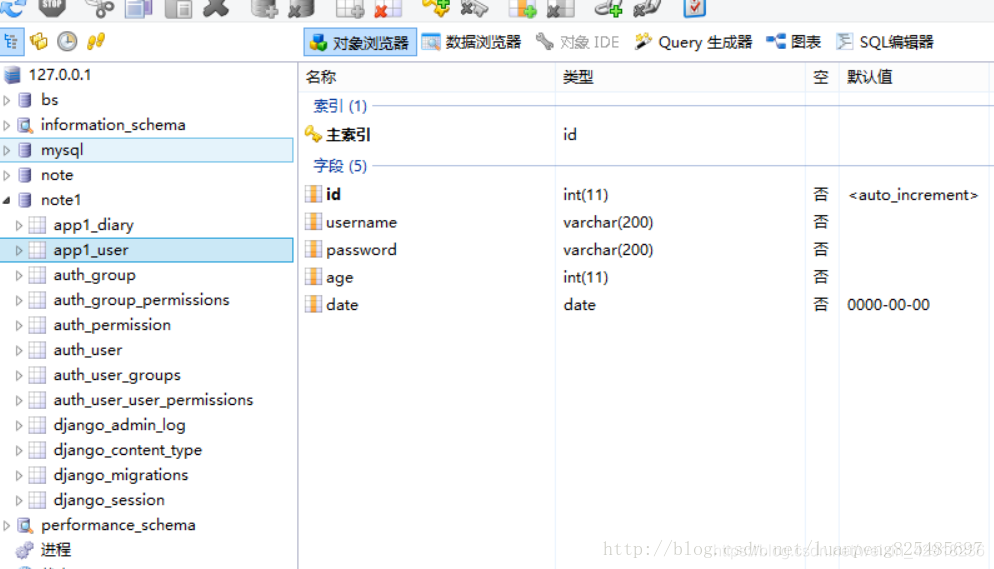
进入mysql-font客户端,我们可以看到数据库note1已经被修改了。
3.models模块数据库操作
定义了models数据结构、Django也自动生成了数据库结构和调用数据的api。那么我们就来看看怎么在函数中操作数据。
3.1、记录增加
from .models import User,Diary
# 增加记录——方法一
User.objects.create(username=username, password=password,date=time.strftime('%Y-%m-%d',time.localtime(time.time())))
# 增加记录——方法二
b = User(username=username, password=password, date=time.strftime('%Y-%m-%d', time.localtime(time.time())))
b.save()
# 增加带有外键的记录
diary = Diary(user=user,content='用户注册')
# diary.user=user # 修改主键时可以使用设置对象属性的方式
diary.save()
3.2、查询
想要从数据库内检索对象,你需要基于模型类,通过管理器(Manager)构造一个查询结果集(QuerySet)。
QuerySet这个集合类型对象,你可以简单的理解为Python列表,可迭代、可循环、可索引、但是不知道负数索引。
查询所有记录
# 查询所有对象
users = User.objects.all() # 可以同数组一样进行操作
for item in users: #再遍历缓存
print(item.username)
查询指定列或多列
# 查询一列生成列表
names = User.objects.all().values('username') # 只取username列,并生成列表,每个元素是字典
for item in names: #再遍历缓存
print(item)
# 查询多列生成列表
id_names = User.objects.all().values('id','username') # 取出id和username列,并生成列表,每个元素是字典
for item in id_names: #再遍历缓存
print(item)
# 查询多列生成列表
id_names = User.objects.all().values_list('id', 'username') # 取出id和username列,并生成一个列表,每个元素是一个元组
for item in id_names: #再遍历缓存
print(item)
查询多列
id_names = UserInfo.objects.all().values_list('id', 'username') # 取出id和username列,并生成一个列表
查询特定记录
- filter(**kwargs):返回一个根据指定参数查询出来的QuerySet
- exclude(**kwargs):返回除了根据指定参数查询出来结果的QuerySet
注意:filter和exclude的结果依然是个QuerySet,因此它可以继续被filter和exclude,这就形成了链式过滤。链式过滤不修改源QuerySet,而是产生新的QuerySet。
注意:filter、exclude方法始终返回的是QuerySets,那怕只有一个对象符合过滤条件,返回的也是包含一个对象的QuerySets
# 过滤查询
users = User.objects.filter(username=username) # 查询name==username的记录
users = users.filter(password=password) # 数据集也可以进行查询
# 排除查询
others = User.objects.exclude(username=username) # 查询name!=username的记录
在查询时django提供了一些快捷字符查询方式
__exact 精确等于 like ‘aaa’
__iexact 精确等于 忽略大小写 ilike ‘aaa’
__contains 包含 like ‘%aaa%’
__icontains 包含 忽略大小写 ilike ‘%aaa%’,但是对于sqlite来说,contains的作用效果等同于icontains。
__gt 大于
__gte 大于等于
__lt 小于
__lte 小于等于
__in 存在于一个list范围内
__startswith 以…开头
__istartswith 以…开头 忽略大小写
__endswith 以…结尾
__iendswith 以…结尾,忽略大小写
__range 在…范围内
__year 日期字段的年份
__month 日期字段的月份
__day 日期字段的日
__isnull=True/False
__isnull=True 与 __exact=None的区别
pk就是primary key的缩写,也就是主键的快捷查询方式。通常情况下,一个模型的主键为“id”,所以下面三个语句的效果一样:
User.objects.get(id__exact=14) # Explicit form
User.objects.get(id=14) # __exact is implied
User.objects.get(pk=14)
我们可以利用这些特殊字来查询。例如查询2018年1月1号前注册的用户
users = User.objects.filter(date__lte='2006-01-01') # 利用特殊字段的查询,例如查询2018年1月1号前注册的用户
users =User.objects.filter(pk__in=[11, 14, 17]) #select * where id in{11,14,17}
users = User.objects.filter(pk__gt=14) # select * where id>14
users = User.objects.filter(username__startswith='aa') # select * where username LIKE 'aa%';
users = User.objects.filter(username__endswith='aa') # select * where username LIKE '%aa';
users = User.objects.filter(username__contains='aa%') #select * where username LIKE '%aa%\%'; Django自动转义了%
通过get函数查询单个对象。
在get方法中你可以使用任何filter方法中的查询参数,用法也是一模一样。
注意:get函数如果在查询时没有匹配到对象,那么get()方法将抛出DoesNotExist异常。在使用get()方法查询时,如果结果超过1个,则会抛出MultipleObjectsReturned异常。所以get函数只在你确定一定且只存在一个匹配对象时使用,还要使用try except包含查询函数。
try:
user = User.objects.get(id=10) # select * where id=10;
user = User.objects.get(id__exact=10) # select * where id=10;
user = User.objects.get(pk=10) # select * where id=10; pk表示id__exact
except:
print('没有查询到记录')
查询外键
Django提供了强大并且直观的方式解决跨越关联的查询,它在后台自动执行包含JOIN的SQL语句。要跨越某个关联,只需使用关联的模型字段名称,并使用双下划线分隔,直至你想要的字段(可以链式跨越,无限跨度)。例如:
# 关于外键从查询
diarys = Diary.objects.filter(user__id__exact=3) # 查询id等于3的用户的所有日志
diarys = Diary.objects.filter(user__id=3) # 查询id等于3的用户的所有日志,同上
diarys = Diary.objects.filter(user__pk=3) # 查询id等于3的用户的所有日志,同上
注意:跨越多值的关系查询:
下面代码表示同时满足两个条件的日志
Diary.objects.filter(user__id=11, qun__id=13)
下面代码表示满足任一条件的日志
Diary.objects.filter(user__id=11).filter(qun__id=13)
使用F表达式引用模型的字段
前面的查询都是字段值与常值的比较。Django提供的F表达式用来支持同一模型中多个字段之间的相互运算查询。比如查询一个字段的值大于另一个字段的所有记录。例如
User.objects.filter(attr1__gt=F('attr2'))
使用Q对象进行复杂查询
普通filter函数里的条件都是“and”逻辑。django.db.models.Q,用于封装关键字参数的集合。
可以使用“&”或者“|”或“~”来组合Q对象,分别表示与或非逻辑。它将返回一个新的Q对象。
默认情况下,以逗号分隔的都表示AND关系:
User.objects.get(
Q(username__startswith='Who'),
Q(date=date(2005, 5, 2)) | Q(date=date(2005, 5, 6))
)
# 它相当于
# SELECT * from user WHERE username LIKE 'Who%'
AND (date = '2005-05-02' OR date = '2005-05-06')
3.3、更新记录
更新对象(先查询,再更新)
# 一次更新多个值
User.objects.filter(username=username).update(username='new_name')
# 一次更新所有值
User.objects.all().update(password='12345')
# 一次更新一个值
users = User.objects.filter(username='new_name')
for item in users:
item.username = 'new_name1'
item.save()
3.4、删除记录
# 删除特定对象
User.objects.filter(username='new_name1').delete()
# 删除所有对象
User.objects.all().delete()
4.使用mysql等数据库语言直接操作数据库
可以自定义这样的函数,再在函数中调用。
# 使用mysql语言直接操作
from django.db import connection
def my_custom_sql(username):
cursor = connection.cursor()
cursor.execute('SELECT * FROM app1_user WHERE username = %s', [username])
row = cursor.fetchone()
return row
5.其他的查询API
前面我们知道了查询数据的函数filter、exclude、get。
Django还提供了一系列其他的查询API供我们做更加丰富的筛选工作。
*order_by(fields)
默认情况下,根据模型的Meta类中的ordering属性对QuerySet中的对象进行排序
Diary.objects.order_by('user__username', '-content')
上面的结果将按照User模型的username属性升序排序,然后再按照content降序排序。”-content”前面的负号表示降序顺序。 升序是默认的。 要随机排序,使用”?”。
reverse()
反向排序QuerySet中返回的元素。 第二次调用reverse()将恢复到原有的排序。
如要获取QuerySet中最后五个元素,可以这样做:
my_queryset.reverse()[:5]
这与Python直接使用负索引有点不一样。 Django不支持负索引,只能曲线救国。
distinct(fields)
去除查询结果中重复的行。
默认情况下,QuerySet不会去除重复的行。当查询跨越多张表的数据时,QuerySet可能得到重复的结果,这时候可以使用distinct()进行去重。
values(fields, expressions)
将查询到的模型实例集合转化为字典集合。
该方法接收可选的位置参数*fields,它指定values()应该限制哪些字段。如果指定字段,每个字典将只包含指定的字段的键/值。如果没有指定字段,每个字典将包含数据库表中所有字段的键和值。
# 列表中包含的是User对象
User.objects.filter(usernaname='luanpeng')
返回:<QuerySet [<User: luanpeng User>]>
# 列表中包含的是数据字典
User.objects.filter(usernaname='luanpeng').values('id', 'username')
返回:<QuerySet [{'id': 1, 'username': 'luanpeng'}]>
*values_list(fields, flat=False)
与values()类似,只是在迭代时返回的是元组而不是字典。每个元组包含传递给values_list()调用的相应字段或表达式的值,因此第一个项目是第一个字段等。
User.objects.values_list('id', 'username')
返回 <QuerySet [(1, 'luanpeng'), ...]>
union(other_qs, all=False)
使用SQL的UNION运算符组合两个或更多个QuerySet的结果。例如:
qs1.union(qs2, qs3)
intersection(*other_qs)
使用SQL的INTERSECT运算符返回两个或更多个QuerySet的共有元素。例如:
qs1.intersection(qs2, qs3)
select_related(fields)
沿着外键关系查询关联的对象的数据。这会生成一个复杂的查询并引起性能的损耗,但是在以后使用外键关系时将不需要再次数据库查询。
using(alias)
如果正在使用多个数据库,这个方法用于指定在哪个数据库上查询QuerySet。方法的唯一参数是数据库的别名,定义在DATABASES
raw(raw_query, params=None, translations=None)
接收一个原始的SQL查询,执行它并返回一个django.db.models.query.RawQuerySet实例。
这个RawQuerySet实例可以迭代,就像普通的QuerySet一样。
6.其他不返回QuerySets的API
前面我们知道了使用get查询一个对象,除此之外还有很多函数不返回QuerySets来丰富我们的使用。
get_or_create(defaults=None, kwargs)
任何传递给get_or_create()的关键字参数,除了一个可选的defaults,都将传递给get()调用。 如果查找到一个对象,返回一个包含匹配到的对象以及False 组成的元组。 如果查找到的对象超过一个以上,将引发MultipleObjectsReturned。如果查找不到对象,get_or_create()将会实例化并保存一个新的对象,返回一个由新的对象以及True组成的元组。
obj, created = User.objects.get_or_create(
username='luanpeng',
password='xxxxxx',
defaults={'age':18, 'date':date(2018, 1, 9)},
)
update_or_create(defaults=None, kwargs)
update_or_create方法尝试通过给出的kwargs 去从数据库中获取匹配的对象。 如果找到匹配的对象,它将会依据defaults 字典给出的值更新字段。 如果没找到对象,则创建一个新的对象,再依据defaults 字典给出的值更新字段。
defaults是一个由 (field, value)对组成的字典,用于更新对象。defaults中的值可以是可调用对象(也就是说函数等)。
该方法返回一个由(object, created)组成的元组,元组中的object是一个创建的或者是被更新的对象, created是一个标示是否创建了新的对象的布尔值。
obj, created = User.objects.update_or_create(
username='luanpeng', password='xxxxx',
defaults={'username': 'luanpeng1'},
)
count()
返回在数据库中对应的QuerySet对象的个数。count()永远不会引发异常。
# 返回包含有'luanpeng'的对象的总数
User.objects.filter(username='luanpeng').count()
latest(field_name=None)
按指定字段排序返回最新的一个记录。例如下面返回日期最近的一个用户对象
User.objects.latest('date')
earliest()、first()、last()
类同latest()。