awk
awk命令可以处理数据流。他支持关联数组、递归函数、条件语句等功能。awk命令也可以从stdin中读取输入。
awk脚本的结构如下:
awk ‘BEGIN{ print “start” } pattern {commands} END{ print “end” }’ file
awk脚本通常由3部分组成:BEGIN、END和带模式匹配选项的公共语句块,这三个部分都是可选的,可以不用出现在脚本中。
awk以逐行的形式处理文件。BEGIN之后的命令会先于公共语句u执行。对于匹配PATTERN的行,awk会对其执行PATTERN之后的命令。最后,在处理完整个文件之后,awk会执行END之后的命令。
awk工作原理
awk命令的工作方式:
(1)、首先执行BEGIN{ commands }语句块中的语句
(2)、接着从文件或者stdin中读取一行,如果能够匹配pattern,则执行随后的commands语句块。重复这个过程,直到文件全部读取完毕。
(3)、当读至输入流末尾时,执行END{commands}语句块。
BEGIN语句块在awk开始从输入流中读取行之前被执行。这是一个可选的语句块,诸如变量初始化,打印输出表格的表头等语句通常都可以放在BEGIN语句块中。
END语句块和BEGIN语句块类似。他在awk读取完输入流中所有的行之后被执行。像打印所有行的分析结果这种常见任务都是在END语句块中实现的。
最重要的部分就是和pattern关联的语句块。这个语句块同样是可选的。如果不提供,则默认执行{ print },即打印所读取到的每一行。awk对于读取到的每一行都会执行该语句块。这就像一个用来读取行的while循环,在循环体中提供了相应的语句。
每读取一行,awk就会检查该行是否匹配指定的模式。模式本身可以是正则表达式、条件语句以及行范围等。如果当前行匹配该模式,则执行{}中的语句。
模式是可选的。如果没有提供模式,那么awk就认为所有行都是匹配的:
echo -e “line1 \nline2” | awk 'BEGIN{ print “start” } { print } END{ print “end” }'

当使用不带参数的print时,它会打印出当前行。
print能够接受参数。这些参数以逗号分隔,在打印参数时则以空格作为参数之间的分隔符,在awk的print语句中,双引号被当作拼接操作符使用。例如:
echo | awk '{ var1=“v1”;var2=“v2”;var3=“v3”; print var1,var2,var3;}'
echo命令向标准输出写入一行,因此awk的{}语句块中的语句只被执行一次。如果awk的输入中包含多行,那么{}语句块中的语句也就会被执行相应的次数。

拼接的使用方法如下:
echo | awk '{ var1=“v1”;var2=“v2”;var3=“v3”; print var1 “-” var2 “-” var3;}'

{}就像一个循环体,对文件中的每一行进行迭代。
TIP:我们通常将变量的初始化语句(如var=0;)放入BEGIN语句块中。在END{}语句块中,往往会放入用于打印结果的语句。
补充内容
awk命令与诸如grep、find和tr这类命令不同,它功能众多,而且拥有很多能够更该命令行为的选项。awk命令是一个解释器,它能够解释并执行程序,和shell一样,它也包括了一些特殊变量。
特殊变量
以下是awk可以使用的一些特殊变量。
NR:表示记录编号,当awk将行作为记录时,改变量相当于当前行号。
NF:表示字段数量,在处理当前记录时,相当于字段数量。默认的字段分隔符是空格。
$0:改变量包含当前记录的文本内容。
$1:改变量包含第一个字段的文本内容。
$2:该变量包含第一个字段的文本内容。
例如:
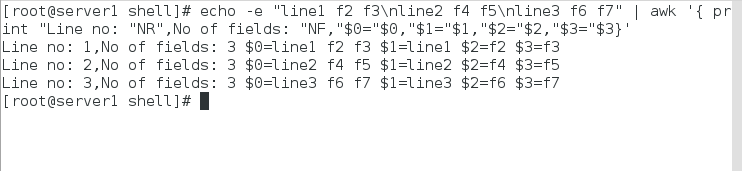
echo -e “line1 f2 f3\nline2 f4 f5\nline3 f6 f7” | awk '{ print “Line no: “NR”,No of fields: “NF, “$0=”$0,”$1=”$1,"$2="$2,"$3="$3 }'
我们可以用print $NF打印一行中最后一个字段,用 $(NF-1)打印倒数第二个字段,其他字段以此类推。awk也支持printf()函数,其语法和c语言中的同名函数一样。
下面的命令会打印出每一行的第二和第三个字段:
awk ‘{ print $3,$2 }’ file

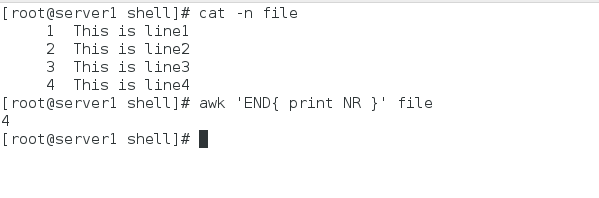
我们可以使用NR统计文件的行数:
awk ‘END{ print NR }’ file
这里只用到了END语句块。每读入一行,awk都会更新NR。当达到文件末尾时,NR中的值就是最后一行的行号。你可以将每一行中第一个字段的值按照下面的方法累加:
seq 5 | awk 'BEGIN{ sum=0;print “Summation:” } { print $1"+";sum+=$1 } END{ print “==”;print sum}'

将外部变量值传递给awk
借助选项-v,我们可以将外部值(并非来自stdin)传递给awk:
var=10000
echo | awk -v VARIABLE=$var '{ print VARIABLE }'

还有一种灵活的方法可以将多个外部变量传递给awk。例如:
var1="variable1";var2="variable2"
echo | awk '{ print v1,v2 }' v1=$var1 v2=$var2

当来自于文件而非标准输入时,使用下列命令:
awk ‘{ print v1,v2 }’ v1=$var1 v2=$var2 file

在上面的方法中,变量以键值对的形式给出,使用空格分隔(v1=$var1 v2=$var2),作为awk的命令行参数紧随在BEGIN、{}、END语句块之后。
用getline读取行
awk默认读取文件中的所有行。如果只想读取某一行,可以使用getline函数。她可以用在BEGIN语句块中读取文件的头部信息,然后在主语句块中处理余下的实际数据
该函数的语法为:getline var。变量var中包含了特定行。如果调用时不带参数,我们可以用$0、$1和$2访问文本的内容。例如:
seq 5 | awk 'BEGIN{ getline; print “Read ahead first line”,$0} { print $0 }'

使用过滤模式对awk处理的行进行过滤
我们可以为需要处理的行指定一些条件:
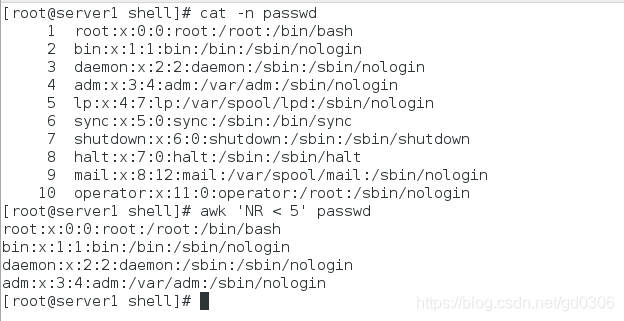
awk 'NR < 5' # 行号小于5的行
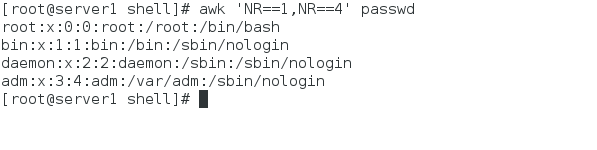
awk 'NR==1,NR==4' # 行号在1-5之间的行,不包括第五行
awk '/linux/' # 包含模式为linux的行(可以用正则表达式指定模式)
awk '!/linux/' # 不包含模式为linux的行

设置字段分隔符
默认的字段分隔符是空格。我们也可以用选项-F指定不同的分隔符:
awk -F: ‘{ print $NF }’ passwd
或者
awk ‘BEGIN{FS=":"} {print $NF}’ passwd

在BEGIN语句块中可用OFS="delimiter"设置输出字段分隔符。
从awk中读取命令输出
awk可以调用命令并读取输出。把命令放入引号中,然后利用管道将命令输出传入getline:
"command" | getline output;
下面的代码从/etc/passwd文件中读入一行,然后显示出用户登录名及其主目录。在BEGIN语句块中将字段分隔符设置为:,在主语句块中调用了grep。
echo | awk 'BEGIN{FS=":"} {“grep root /etc/passwd” | getline; print $1,$6}'

awk关联数组
除了数字和字符串类型的变量,awk还支持关联数组。关联数组是一种使用字符串作为索引的数组。你可以通过中括号中索引的形式来分辨出关联数组。
arrayName[index]
就像用户定义的简单变量一样,你也可以使用等号为数组元素赋值:
myarray[index]=value
在awk中使用循环
在awk中可以利用for循环,其格式与C语言中的差不多
awk ‘BEGIN{FS=":"} {nam[$1]=$5} END{for (i in nam) {print i,nam[i]}}’ passwd
