官网:https://spark.apache.org/docs/latest/streaming-programming-guide.html
一:介绍
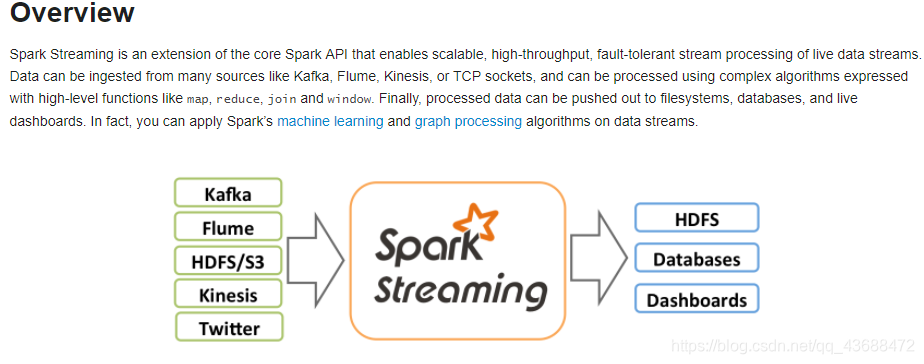
Spark流是核心Spark API的扩展,它支持对实时数据流进行可伸缩、高吞吐量和容错的流处理。数据可以从Kafka、Flume、Kinesis或TCP套接字等多个源获取,也可以使用映射、reduce、join和window等高级函数表示的复杂算法进行处理。最后,可以将处理过的数据推送到文件系统、数据库和实时仪表板。事实上,您可以将Spark的机器学习和图形处理算法应用于数据流。
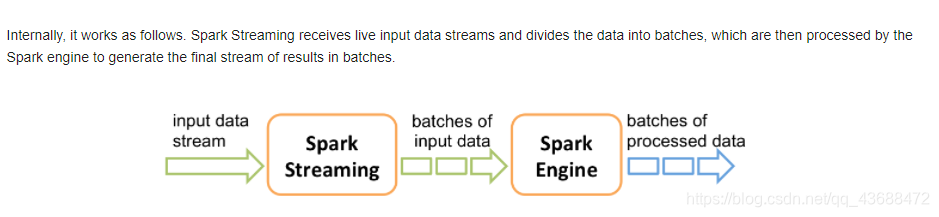
在内部,它的工作原理如下。Spark流接收实时输入数据流,并将数据划分为批,然后由Spark引擎处理这些数据,生成最终的批结果流。
IDEA中操作
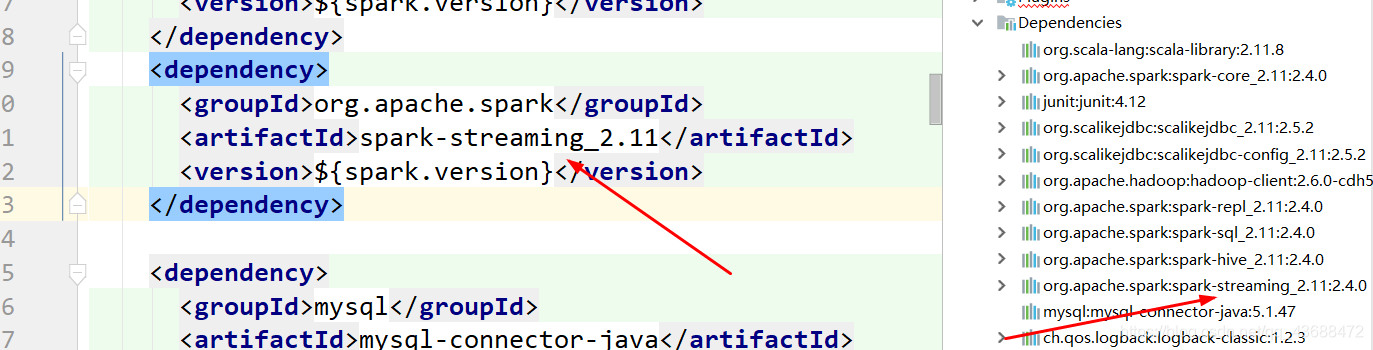
添加pom文件
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
代码:
package g5.learning.Stearing001
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Seconds, StreamingContext}
object streamingWCApp {
def main(args: Array[String]): Unit = {
//准备工作
val conf = new SparkConf().setMaster("local[2]").setAppName("streamingWCApp")
val ssc = new StreamingContext(conf, Seconds(10))
//业务逻辑
val lines = ssc.socketTextStream("hadoop001", 9999)
val results = lines.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_)
results.print()//默认打十条结果
//streaming 不需要关掉
//streaming的启动
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
}
}
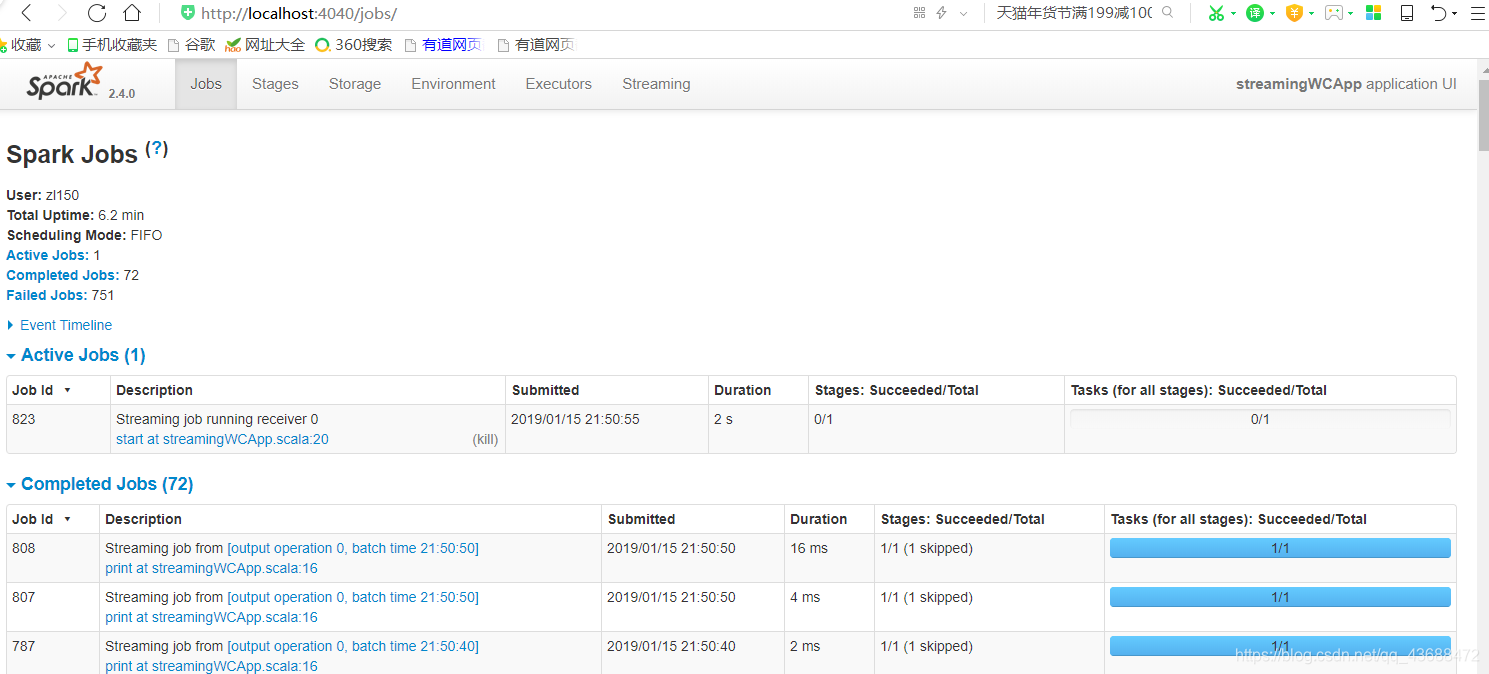
localhost:4040端口查询
[hadoop@hadoop001 conf]$ nc -lk 9999
a,a,a,a,a,a,a,a,a,a,d,d,