4.8.1 为什么说java是平台独立的语言?
平台独立性是指可以在一个平台上编写和编译程序,而在其他平台上运行。
保证java具有平台独立性的机制为“中间码”和“Java虚拟机(JVM)”
java程序被编译后不是生成能在硬件平台上执行的代码,而是生成了一个中间码,不同的硬件平台装有不同的JVM,由JVM来负责把“中间码”翻译成硬件平台能执行的代码
故JVM不具有平台独立性,而是与硬件平台相关的。
解释执行过程分三步进行:代码的装入,代码的校验,代码的执行。
装入代码的工作由类装载器完成,被装入的代码由字节码校验器进行检查。
java字节码的执行也分两种方式:即时编译方式和解释编译方式
即时编译方式指解释器先将字节码编译成机器码,然后再执行该机器码。
解释编译方式指解释器通过每次解释并执行一小段代码来完成java字节码程序的所有操作。
通常采用的是解释执行方式。
笔1:一个java程序运行从上到下的环境依次是:
Java程序,JRE/JVM , 操作系统,硬件
笔2:java程序经编译后会产生字节码
4.8.2 java平台与其他语言平台有哪些区别?
java平台是一个纯软件的平台,这个平台可以运行在一些基于硬件的平台 (Linux,windows)之上。
java平台主要包含连个模块,JVM和Java API
JVM是一个虚构出来的计算机,用来把Java编译生成的中间代码转换为机器可以识别的编码并运行。
每当一个java程序运行时,都会有一个对应的jvm实例,只有当程序运行结束后,这个jvm才退出。
JVM实例通过调用类的main方法来启动一个java程序。
java API是Java为了方便开发人员 进行开发而设计的,提供了许多非常有用的接口,这些接口也是用java语言编写的,并且运行在jvm上。
4.8.3 JVM装载class文件的原理机制是什么?
java语言是一种动态性的解释型语言。类(class)只有被加载到JVM中后才能运行。
当运行指定程序时,JVM会将编译生成的.class文件按照需求和一定的规则加载到内存中,并组织成为一个Java的应用程序。
这个加载过程是由类加载器完成的,即ClassLoader和它的子类来实现的。
类加载器本身也是一个类,其实质是把类文件从硬盘读取到内存中。
类的加载方式分为隐式加载与显示加载两种。
1)隐式加载指:程序在使用new等方式创建对象时,会隐式地调用类的加载器把对应的类加载到JVM中。
2)显示加载指:通过直接用class.forName()方法来把所需的类加载到JVM中。
任何一个工程项目都是由许多个类组成的,当程序启动时,只把需要的类加载到JVM中,其他类只在被使用的时候才会被加载
优点:
1)加快加载速度
2)节约程序运行过程中对内存的开销
在java语言中,每个类或者接口都对应一个.class文件,这些文件可以被看做一个个可以动态加载的单元,因此只有部分类被修改时,只需要重新编译变化的类即可,而不需要重新编译所有文件,因此加快了编译速度。
在Java语言中,类的加载是动态的,它并不会一次性将所有的类全部加载后再运行,而是保证程序运行的基础类(例如基类)完全加载到JVM中,至于其他类,则在需要的时候才加载。
在java语言中,可以把类分为3类:系统类,扩展类和自定义类。
java针对这三种不同的类提供了3中类型的加载器,关系如下:
Bootstrap Loader - 负责加载系统类(jre/lib/rt.jar 的类)

--ExtClassLoader -负责加载扩展类(jar/lib/ext/*.jar的类)
--AppClassLoader -负责加载应用类
classpath指定的目录或jar中的类
以上这三个类是如何协调工作来完成类的加载的呢?
他们是通过委托的方式实现的。
即当有类需要被加载时,类加载器就会请求父类来完成这个载入工作,父类会使用其自己的搜索路径来搜索需要被载入的类
如果搜索不到,才会由子类按照其搜索路径来搜索待加载的类。
package cn.itcast.demo;
public class TestLoader {
public static void main(String[] args) {
//调用class加载器
ClassLoader clApp = TestLoader.class.getClassLoader();
System.out.println(clApp);
//调用上一层Class加载器
ClassLoader clExt = clApp.getParent();
System.out.println(clExt);
//调用根部Class加载器
ClassLoader clBoot = clExt.getParent();
System.out.println(clBoot);
}
}
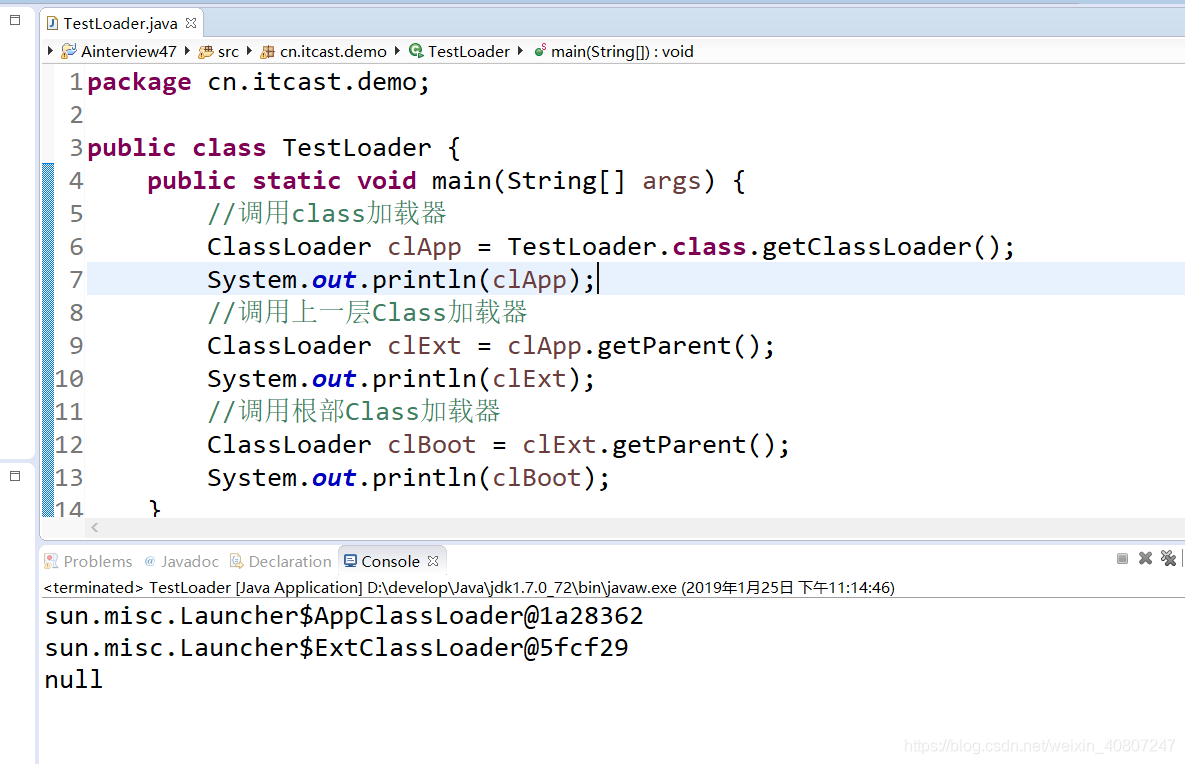
说明:
从上例可以看出,TestLoader类是由AppClassLoader来加载的。
由于Bootstrap Loader是用C++来实现的
因此,在java语言中是看不到它的,会输出null.
4.8.4 什么是GC
gc的主要作用是:回收程序中不再使用的内存。
gc可以自动检测对象的作用域,可自动地把不再被使用的存储空间释放掉
具体而言,gc要负责三项任务:
分配内存
确保被引用对象的内存不被错误地回收
回收不再被引用的对象的内存空间。
gc的优点:
1)提高了开发人员的生产效率
2)避免因开发人员错误地操作内存而导致应用程序的奔溃。
gc的缺点:
为了实现垃圾回收,gc必须跟踪内存的使用情况,释放没用的对象,再完成内存释放后还需要处理堆中的碎片
这些操作必定会增加JVM的负担,降低程序的执行效率。
对对象而言,如果没有任何变量区引用它,那么该对象将不可能被程序访问,因此认为是垃圾信息,可以被回收。
只要有一个以上的变量引用该对象,该对象就不会被回收。
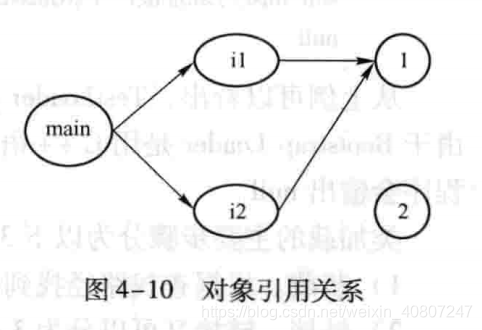
对于GC来说,它使用有向图来记录和管理堆内存中的所有对象,通过 这个有向图就可以识别哪些对象是可达的,
(有引用变量引用),哪些对象是不可达的,所有不可达的对象都是可以被垃圾回收的。
package cn.itcast.demo;
public class Test2{
public static void main(String[] args) {
Integer i1 = new Integer(1);
Integer i2 = new Integer(2);
i2 = i1;
}
}
说明:
执行完i2 = i1;之后此时如果GC正在进行垃圾回收操作,再遍历有向图的时候,资源i2所占的内存是不可达的,gc会回收该块内存空间。
垃圾回收器是依据一定的算法进行的,下面介绍其中几种常见的垃圾回收算法。
1)引用计数算法
简单但效率低。
原理:在堆中对每个对象都有一个引用计数器;当对象被引用时,引用计数器+1
当引用对象被置为空或者离开作用域时,引用计数器-1
由于无法解决相互引用的问题,因此JVM没有采用这种算法。
2)追踪回收算法
追踪回收算法利用JVM维护的对象引用图,从根节点开始遍历对象大的应用图,同时标记遍历到的对象。
当遍历结束时,未被标记的对象就是目前已不被使用的对象,可以被回收。
3)压缩回收算法
把堆中活动的对象移动到堆中一端,这样就在堆中另一端留出很大的一块空闲空间,
相当于对堆中的碎片进行处理,但是每次处理都会带来性能的损失。
4)复制回收算法
把堆分成两个大小相同的区域,在任何时刻,只有其中的一块区域被使用,直到这个区域被消耗完,此时gc中断程序的执行。
通过遍历的方式把所有活动的对象复制到另一个区域中,在复制的过程中他们是紧挨着布置的,可以消除内存碎片
当复制过程结束后程序会接着运行,直到这块区域被使用完,然后采用上面的方式进行回收。
优点:在进行垃圾回收的同时对对象的布置也进行了安排,消除了内存碎片
缺点:
对于指定大小的堆来说,需要两倍大小的内存空间;
在内存调整的过程中要中断当前程序的执行,降低了程序的执行效率。
5)按代回收算法
复制回收算法的缺点主要是:每次算法执行时候,所有处于活动状态的对象都被复制,效率太低。
由于程序有“程序创建的大部分对象的生命周期都很短,只有一部分对象有较长的生命周期"
因此据此进行优化算法
把堆分成两个或多个子堆,每一个子堆被视为一代。
算法在运行的过程中优先收集那些年幼的对象,
如果一个对象经过多次收集仍然存活,那么就可以把这个对象转移到高一级堆中,减少对其扫描次数。
笔1:当Float对象在 第二行被创建后,什么时候能够被垃圾回收?
public Object m(){
Object o = new Float(3.14F);
Object[] oa = new Object[1];
oa[0] = o;
o = null;
oa[0] = null;
print 'return 0'
}
当执行完oa[0] = null后,不会再有对象引用了,所以可以被回收了。
笔2:下列关于垃圾回收器的说法中正确的是:D
A:一旦一个对象成为垃圾,就立刻被回收掉。
B:对象空间被回收掉之后,会执行该对象的finalize()方法
C:finalize方法和C++中的析构函数完全是一回事
D:一个对象称为垃圾是因为不再有引用指着它,但是线程并非如此。
说明:
成为垃圾的对象,只有在下次垃圾回收器运行时才会被回收,而不是马上被清理。
finalize方法是在对象空间被回收前调用的
C++中调用了析构函数后,对象一定被销毁,而java调用了finalize方法 ,垃圾却不一定被回收
当一个对象不再被引用后就成为垃圾可以被回收,但是线程就算没有被引用也可以独立运行的,因此与对象不同。
笔3:是否可以主动通知JVM进行垃圾回收?
开发人员不能够实时调用垃圾回收器对某个对象进行垃圾回收
但是可以通过调用System.gc()来通知垃圾回收器运行。当然JVM也并不会保证垃圾回收器马上就会运行。
由于System.gc()会停止所有的响应,去检查内存中是否有可回收的对象,对程序的正常运行有大威胁,不建议频繁使用。
4.8.5 Java是否存在内存泄漏问题?
内存泄漏是指:一个不再被程序使用的对象或变量还在内存中占有存储空间。
java中既然有GC,那么是否还存在内存泄漏问题呢?
在java中判断一个内存空间是否符合垃圾回收的标准有两个:
第一:给对象赋予新值null,以后再没有被使用过
第二:给对象赋予了新值,重新分配了内存空间。
内存泄漏主要有两种情况:
1)在堆中申请的空间没有被释放
2)对象已不再被使用,但还仍然在内存中保留。
GC可以解决第一种内存泄漏,但是对于第二种情况,则无法保证不再使用的对象会被释放。
因此,Java语言中的内存泄漏主要指的是第二种情况。
例1:
public class Test{
public static void main(String[] args) {
Vector v = new Vector(10);
for (int i = 0; i < 10; i++) {
Object o = new Object();
v.add(o);
}
}
}
说明:
当退出循环后,o的作用域就会结束,但是由于V在使用这些对象,因此GC无法回收。
造成内存泄漏,只有将这些对象从Vector中删除才能释放创建的这些对象
在java语言中,容易引起内存泄漏的原因很多,如下几种:
1)静态集合类:
例如HashMap和Vector。如果这些容器为静态的,由于他们的生命周期与程序一致,那么容器中的对象在程序结束之前将不能被释放,从而造成内存泄漏。如上例。
2)各种连接:
例如数据库连接,当不再使用时候,需要调用close方法释放连接,gc才能回收相应的对象,否则,如果不显示的关闭Connection,Statement,或ResultSet,将会造成大量的对象无法被回收,引起内存泄漏。
3)监听器:
通常一个应用中会用到多个监听器,但在释放对象的同时往往没有相应地删除监听器,引起内存泄漏。
4)变量不合理的作用域。
一个变量定义的作用域范围大于其使用范围,造成内存泄漏。另一方面如果没有及时把对象设置为null,很可能会导致内存泄漏的发生。
例1:
class Server{
private String msg;
public void receiveMsg(){
readFromNet();//从网络接受数据保存到msg中
saveDB();//把msg保存到数据库中
}
}
说明:
把msg保存到数据库中以后,此时msg已经没用了,但是由于msg的生命周期与对象的生命周期相同,此时msg还不能被回收,造成了内存泄漏。
两种解决办法:
1)msg的作用范围 只在 readFromNet方法中,因此可以将msg设置为readFromNet内局部变量
2)在使用完msg之后将msg设置为null,这样GC就能够进行回收。
5)单例模式可能会造成内存泄漏
单例模式的实现有好多种,下例就可能会造成内存泄漏。
例1:
class BigClass{
//class body
}
class Singleton{
private BigClass bc;
private static Singleton instance = new Singleton(new BigClass());
private Singleton(BigClass bigClass) {
this.bc = bigClass;
}
public Singleton getInstance(){
return instance;
}
}
在上述实现的单例模式中,Singleton存在一个对对象BigClass的引用,由于单例对象以静态变量的方式存储
因此在JVM的整个生命周期都存在
同时由于它有一个对对象的引用,这样会导致BigClass类的对象不能够被回收。
4.8.6 Java中的堆和栈有什么区别?
在java语言中,堆栈都是内存中存放数据的地方。
基本数据类型和对象的引用变量,其内存都分配在栈上,变量出了作用域就会被释放。而引用类型的变量,其内存分配在堆上或者常量池(字符串常量或基本数据类型常量),需要通过new等方式进行创建。
具体而言:
栈内存主要存放基本数据类型和引用变量
栈内存的管理是通过压栈和弹栈操作来完成的,以栈帧为基本单位来管理程序的调用关系。
每当有函数调用时,就会通过压栈方式创建新的栈帧,每当函数调用结束后就会通过弹栈的方式释放栈帧。
堆内存存放运行时创建的对象
通过new关键字创建的对象都存放在堆内存中。
JVM是基于堆栈的虚拟机,每个java程序都运行在一个单独的JVM实例上,每一个实例唯一对应一个堆
一个java程序内的多个线程也运行在同一个JVM实例上,这些线程之间会共享堆内存。
因此,多线程在访问堆中的数据时需要对数据进行同步。
java开发人员只需要申请所需要的堆空间而不需要考虑释放的问题。
在堆中产生了一个数组或对象之后,还可以在栈中定义一个特殊的变量,让栈中的这个变量的取值=数组或对象在堆内存中的首地址,栈中的这个变量就成了数组或对象的引用变量。
引用变量相当于为数组和对象起的名称,以后可以在程序中使用栈中的引用变量来访问堆中的数组或对象。即java中的引用。
从堆栈的功能和作用来比较,堆用来存放对象的,栈用来执行程序的。相比堆,栈的存取速度更快,但栈的大小和生存期确定,缺乏灵活性。堆可以在运行时动态分配内存,导致存取速度缓慢。
例1:
class Rectangle{
private int width;
private int length;
public Rectangle(int width,int length){
this.width = width;
this.length = length;
}
}
public class Test{
public static void main(String[] args) {
int i = 1;
Rectangle r = new Rectangle(3, 5);
}
}
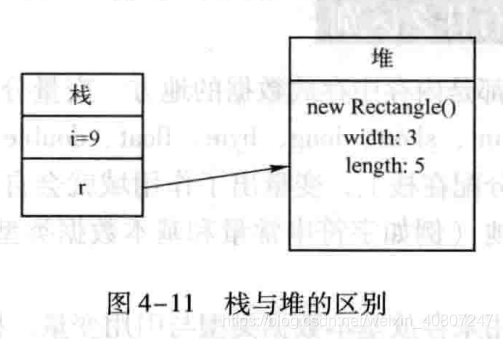
说明:在上述程序进入main()方法后,数据的存储关系如下:
当main()方法退出后,存储在栈中的i和r通过压栈和弹栈操作将会在栈中被回收
而存储在堆中的对象将有GC来自动回收。