版权声明:该版权归博主个人所有,在非商用的前提下可自由使用,转载请注明出处. https://blog.csdn.net/qq_24696571/article/details/86660139
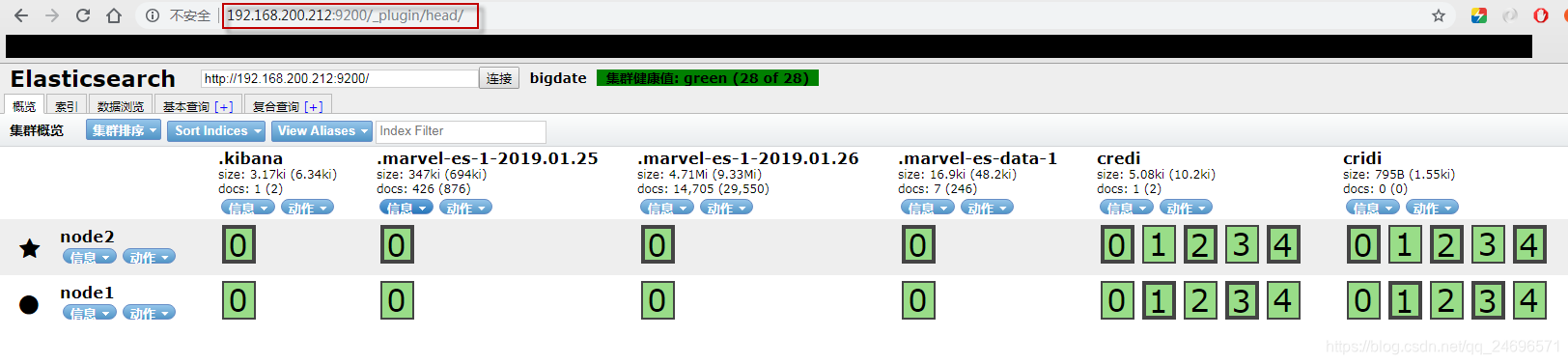
Elasticsearch简介
- Easticsearch是一个基于Lucene的实时分布式搜索和分析的引擎 . 用于云计算中快速搜索 , 稳定可靠又快速 . 它基于RESTful接口
- Lucene是一个库 , 使用的时候需要用java语言集成到应用 . Lucene非常复杂 . Elasticsearch也使用java开发 , 也需要使用lucene作为核心实现搜索和索引 , 但是它通过简单的RESTful API 来让搜索变得简单 .
- 在Elasticsearch之前有同款产品solr , 但是性能没有Elasticsearch好 ,查询速度大约提升了50倍.
Elasticsearch的优点
- 分布式 , 实时分布 , 被称为’Push replication’ .
- 支持Lucene , 接近实时搜索 . 性能相对于solr这样的高级框架更好 .
- 采用 Gateway 概念 , 备份更加简单.
- 服务器节点组成对等的网络结构 , 节点故障会自动分配其他节点 .
和关系型数据库的对比
- 关系型数据库有数据库 , Elasticsearch有索引库(index)
- 关系型数据库有多张表 , Elasticsearch有类型(type)
- 关系型数据库表中的内容是一行 , Elasticsearch是文档(document)
- 关系型数据库的列 , Elasticsearch是字段(field)
- Elasticsearch的类型(type)不太常用, 官网表示之后可能会取消类型 .
- Elasticsearch是通过倒排索引来加速检索 . 倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。
Rest操作
REST的操作分为以下几种:
- GET:获取对象的当前状态;
- PUT:改变对象的状态;
- POST:创建对象;
- DELETE:删除对象;
- HEAD:获取头信息。
启动Elasticsearch
- Linux环境下单台启动
/home/elasticsearch-2.4.5/bin/elasticsearch(集群各节点到自己bin目录下启动elasticsearch) - 后台启动
/home/elasticsearch-2.4.5/bin/elasticsearch -d
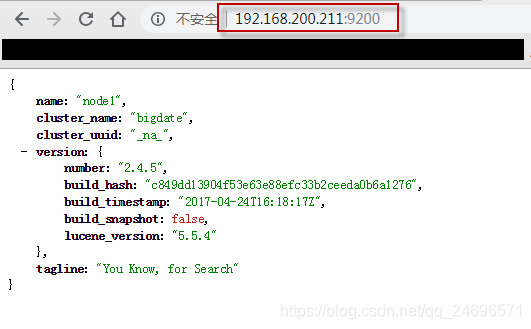
{
name: "node1", //节点别名
cluster_name: "bigdate", //集群别名
cluster_uuid: "_na_",
version: {
number: "2.4.5", //安装版本
build_hash: "c849dd13904f53e63e88efc33b2ceeda0b6a1276",
build_timestamp: "2017-04-24T16:18:17Z",
build_snapshot: false,
lucene_version: "5.5.4" //lucene版本
},
tagline: "You Know, for Search"
}
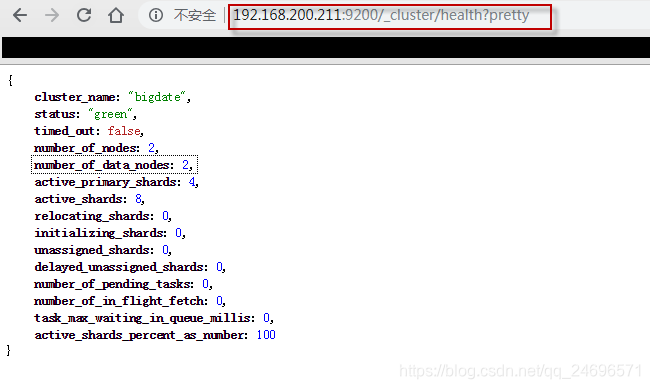
- 集群启动(与单台启动相同,区别在于访问的url不同)
Elasticsearch操作
1. 索引库操作
- 创建索引库
- 格式 :
crul -X[rest] http://[创建库所在节点ip]:9200/[库名]curl -XPUT http://192.168.200.211:9200/credi/或者curl -XPOST http://192.168.200.211:9200/credi/
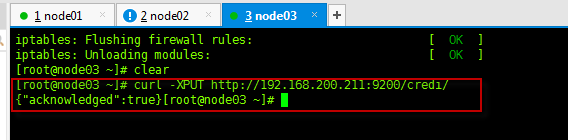
- 格式 :
- 删除索引库
- 格式 :
crul -X[rest] http://[删除库所在节点ip]:9200/[库名]curl -XDELETE http://192.168.200.211:9200/credi/
- 格式 :
2. 文档(document)操作(CURL命令)
- 2.1 创建document(创建后的文件在data目录下)
- post和put都可以创建 , post可以不指定id , 会自动生成. put必须设置id
?pretty让排版更清晰
格式:
curl -XPUT http://192.168.200.211:9200/[库名]/[类型]/[documentID][?pretty] -d '{
"[字段名]" : "[字段值]"
}'
例子1:
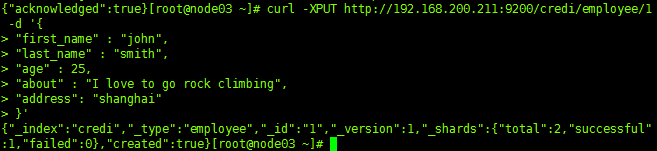
curl -XPUT http://192.168.200.211:9200/credi/employee/1 -d '{
"first_name" : "john",
"last_name" : "smith",
"age" : 25,
"about" : "I love to go rock climbing",
"address": "shanghai"
}'
或者 , 例子2:
curl -XPOST http://192.168.200.211:9200/credi/employee/1?pretty -d '{
"first_name" : "john",
"last_name" : "smith",
"age" : 25,
"about" : "I love to go rock climbing",
"address": "shanghai"
}'
- 2.2 更新document
- 首先建议使用POST
- PUT是全局更新 , 有的字段更新 , 没有的字段删除 .
- POST是局部更新 , 有的字段更新 , 没有的字段也不删除 .
格式:
curl -XPOST http://[节点ip]:9200/[库名]/[类型]/[ID]/_update?pretty -d '
{
"doc":{
"[字段名]":"[字段值]"
}
}'
例1(局部更新):
curl -XPOST http://192.168.200.211:9200/credi/employee/1/_update?pretty -d '
{
"doc":{
"city":"beijing",
"sex":"male"
}
}'
例2(全局更新):
curl -XPUT http://192.168.200.211/credi/employee/1?pretty -d '{
"city":"beijing",
"car":"BMW"
}'
- 2.3 查询document
-i:头文件信息
格式:curl [-i] -XGET http://[节点ip]:9200/[库名]/[类型]/[ID][?pretty]
例子(查询所有):curl -XGET http://192.168.200.211:9200/credi/employee/_search?pretty
例子2(查询指定id):curl -XGET http://192.168.200.211:9200/credi/employee/1?pretty
例子3(查询特定字段):curl -XGET http://192.168.200.211:9200/credi/employee/1?_source=car- 2.4 DSL查询(领域特定语言)
格式:
curl -XGET http://[ip]:9200/[库名]/[类型名]/_search?pretty -d '{
"query":
{"match":
{
"[字段名]":"[字段值]"
}
}
}'
例子1(根据特定的条件查询指定的数据):
curl -XGET http://192.168.200.211:9200/credi/employee/_search?pretty -d '{
"query":
{"match":
{"last_name":"smith"}
}
}'
例子2(多个字段包含中有任何一个包含指定值则返回其数据)
curl -XGET http://192.168.200.211:9200/credi/employee/_search?pretty -d '
{
"query":
{"multi_match":
{
"query":"BMW",
"fields":["car","city"]
}
}
}'
(car和city,只要值等于BMW就把数据返回)
例子3(多个字段都符合条件就把数据返回)
curl -XGET http://192.168.200.211:9200/credi/employee/_search?pretty -d '
{
"query":
{"bool" :
{
"must_not" :
{"match":
{"age":20}
},
"must" :
{"match":
{"car":"BMW"}
}
}
}
}'
(把age不等于20 , car等于BMW的数据返回)
- 2.5 删除文档(document)
curl -XDELETE http://192.168.200.211:9200/credi/employee/1?pretty
删除一个文档也不会立即生效,它只是被标记成已删除。 Elasticsearch将会在你之后添加更多索引的时候才会在后台进行删除内容的清理