https://zhuanlan.zhihu.com/p/51843485
一、简介
在评估平行语料库的质量时,研究语料库的三个特征,即1)语言/翻译质量,2)单语质量,3)语料库多样性。 基于规则和基于模型的方法都适用于对并行句子对进行评分。
语料库清理任务分为三个部分:
- 高质量的并行句子对应该具有,其目标句子精确地转换为源句子的特性,反之亦然。通过量化翻译质量(也称为双语分数)和句子对的准确性去做。
- 评估平行语料库的目标和/或源语义的质量。
- 我们需要关注所有领域,以便可以广泛使用最终的MT系统。 因此,在对并行结构进行二次采样时,应对多样性进行评估。
最后,将并行语料库的三个特征组合起来构建最终的干净语料库
二、平行句子评分方法
2.1,Bilingual Quality Evaluation
包括一个嘈杂的语料库过滤规则、两种翻译质量评估方法:(1)基于单词对齐的双语评分和(2)基于Bitoken CNN分类器的双语评分
Rule-based Filtering
- 句子长度比。源句子/目标句子。以tokens或者单词为单位。比例范围[0.4,2.5]
- 编辑距离。编辑距离小,则源、目标较相似,这对翻译系统是不好的。所以过滤掉距离距离小于2,或编辑距离比小于0.1的句子对。编辑距离比:编辑距离通过源和目标句子长度的平均长度来标准化。
- 特殊标记的一致性。比如邮箱地址,直接复制即可。
Word Alignment-based Bilingual Scoring

在此任务中,单词对齐模型在WMT18新翻译任务提供的干净平行语料库上进行训练。 我们使用fast align来训练模型,并获得正向和反向单词翻译概率表。
Bitoken CNN Classifier-based Bilingual Scoring
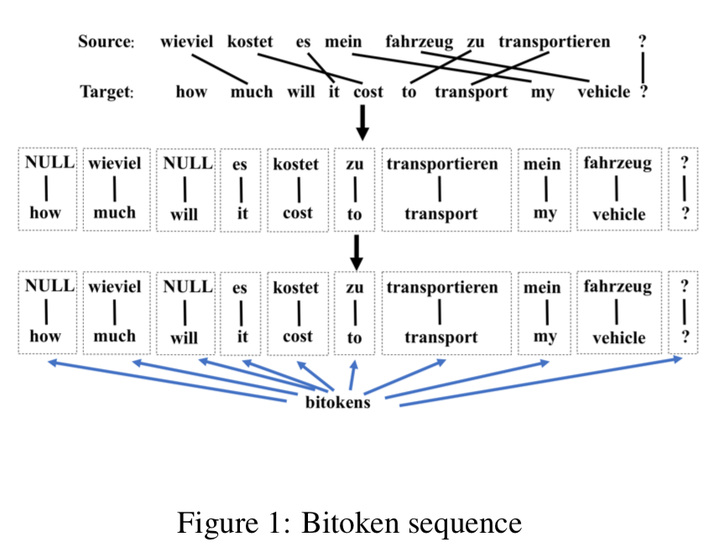
从对齐的句子对中提取bitokens。 序列中的每个bitoken被视为一个单词,每个bitoken序列被视为一个正常的句子。 然后将这些bitoken语句送入CNN分类器以构建双语评分模型。 对于每个候选句子对,该模型将给出两个概率:p(pos)和p(neg),质量得分被视为scorebitoken = p(pos) - p(neg)。
对于训练数据集,从高质量语料库获得的bitoken序列被标记为正。 对于负训练数据,我们根据干净的数据手动构建一些噪声数据。例如,将干净的平行语料库的目标侧面信息随机排序,或随机删除源或目标句子的单词。 因此可以从这个不平行的语料库中获得负bitoken序列。
2.2,Monolingual Quality Evaluation (单语质量评估)
Rule based Filtering
- 删除句子长度不在[2,80]的句子
- 有效token的比率计算为句子的长度。 这里,有效令牌是包含相应语言中的字母的令牌。 例如,英语中的有效令牌应包含英文字母。 如果句子的有效令牌比率小于0.2,则过滤。
- 语言过滤。如果源、目标语言,不是我们想要的语言,则过滤掉。
Language Model Scoring
语言模型可用于过滤掉不合语法的数据。
2.3, Corpus Diversity(语料库多样性)
Rule-based Filtering
我们可以使用一个简单的规则来减少类似句子对的数量。在我们的实验中,对于英语句子,通过删除除英文字母之外的所有字符来完成泛化。之后,如果某些句子对具有相同的通用源或目标句子,则将选择具有最高质量分数的句子对。
N-gram based Diversity Scoring
基于N-gram的多样性评分通常用于选择具有高度多样性的单语句
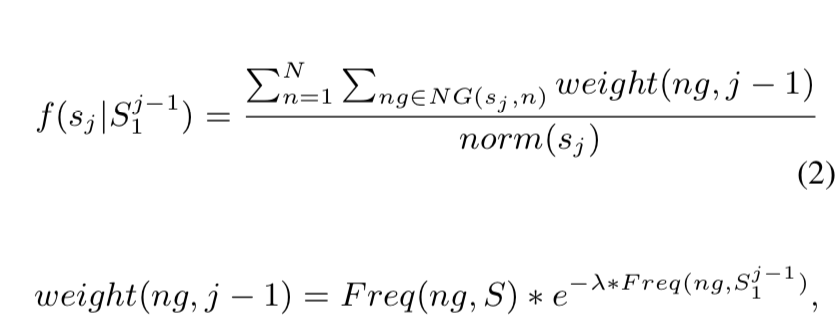
Parallel Phrases Diversity Scoring
在这里,我们的目标是选择包含各种平行短语的双语语料库。 有了这种语料库,MT模型将学习更多的翻译知识。
首先,我们使用fast align toolkit来训练单词对齐模型。 然后可以使用Moses toolkit提取语料库的短语表。 接下来,我们可以使用最大匹配方法从短语表中获得每个句子对的并行短语对。 最后,遵循基于N-gram的多样性评分部分中描述的方法,相同的选择过程(其中,N-gram被短语对替换)用于句子对的评分。 在我们的系统中,当短语长度小于7时,它最有效。
2.4, Methods Combination and corpus sampling
在我们的语料库过滤系统中,所有方法都组合成一个管道。
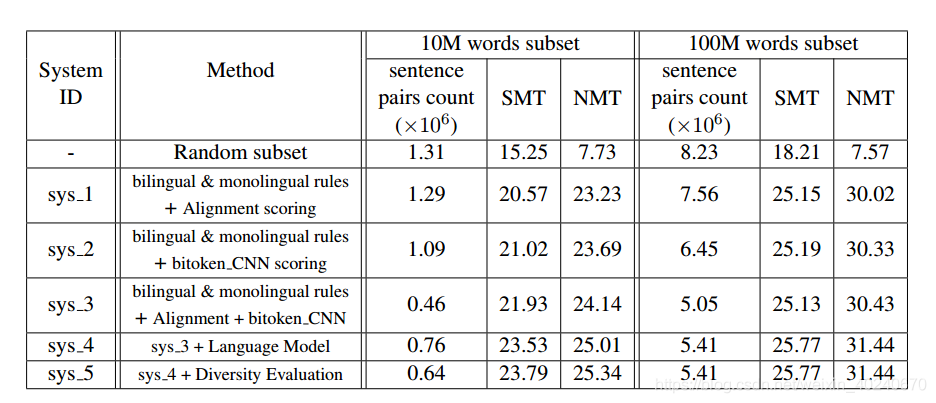
首先,我们应用所有双语和单语规则来过滤非常嘈杂的句子对。 然后,通过上述相应模型可以产生两个双语分数和目标侧语言模型分数。 这三个分数被单独标准化,然后线性组合以产生单一质量分数。 之后,我们按照相应的质量得分按降序对句子对进行排序。 然后使用多样性方法重新评分/重新排序语料库。 最后,我们选择了两组前N个句子对,其中包含总共1000万个单词和1亿个单词。
通过逐次增加方法,构造出五个模型,在SMT和NMT的baseline上,We find that the diversity method (only Parallel Phrases Diversity Scoring is used in sys 5 system)works well in selecting the smaller subset corpus,e.g. the 10 million words corpus. For large subset corpus selection, it almost has no improvement. We attribute this to the sufficiently high diversity of larger subset corpus