1、语言模型(language model)与翻译模型(translate model)
参考:https://zh.wikipedia.org/wiki/%E7%BB%9F%E8%AE%A1%E6%9C%BA%E5%99%A8%E7%BF%BB%E8%AF%91
经常接触两个名词,语言模型(LM)和翻译模型(TM),这一概念最早是从统计机器翻译中来的,统计机器翻译的首要任务是为语言的产生构造某种合理的统计模型,并在此统计模型基础上,定义要估计的模型参数,并设计参数估计算法。早期的基于词的统计机器翻译采用的是噪声信道模型(生成式模型),采用最大似然准则进行无监督训练,而近年来常用的基于短语的统计机器翻译则采用区分性训练方法,一般来说需要参考语料进行有监督训练。
噪声信道模型假定,源语言中的句子




利用贝叶斯公式,并考虑对给定

由此,我们得到了两部分概率:
,指给定信源,观察到信号的概率。在此称为翻译模型。
,信源发生的概率。在此称为语言模型
可以这样理解翻译模型与语言模型,翻译模型是一种语言到另一种语言的词汇间的对应关系,而语言模型则体现了某种语言本身的性质。翻译模型保证翻译的意义,而语言模型保证翻译的流畅。从中国对翻译的传统要求“信达雅”三点上看,翻译模型体现了信与达,而雅则在语言模型中得到反映。
原则上任何语言模型均可以应用到上述公式中,因此以下讨论集中于翻译模型。在IBM提出的模型中,翻译概率被定义为:


词对齐示例
其中的

其中



其中
简单地说,语言模型就是用来计算一个句子的概率的模型,利用语言模型,可以确定哪个词序列的可能性更大,或者给定若干个词,可以预测下一个最可能出现的词语。举个音字转换的例子来说,输入拼音串为nixianzaiganshenme,对应的输出可以有多种形式,如你现在干什么、你西安再赶什么、等等,那么到底哪个才是正确的转换结果呢,利用语言模型,我们知道前者的概率大于后者,因此转换成前者在多数情况下比较合理。再举一个机器翻译的例子,给定一个汉语句子为李明正在家里看电视,可以翻译为Li Ming is watching TV at home、Li Ming at home is watching TV、等等,同样根据语言模型,我们知道前者的概率大于后者,所以翻译成前者比较合理。
语言模型主要包括统计语言模型、神经语言模型。其中统计语言模型主要包括LSI、n-gram(贝叶斯)等,而神经语言模型主要包括n-gram(Bengio)、word2vec(skip-gram、CBOW)
翻译模型针对源语言到目标语言的转换过程进行立即建模,他从真实的训练语料中学习翻译知识,并融合了上下文信息。
翻译模型如seq2seq、transformer等
2、反向翻译(back-translation)
参考论文:
Rico Sennrich, Barry Haddow, and Alexandra Birch.2016. Edinburgh neural machine translation systems for wmt 16. arXiv preprint arXiv:1606.02891.
Rico Sennrich, Barry Haddow, and Alexandra Birch. 2016a. Improving Neural Machine Translation Models with Monolingual Data. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL 2016), Berlin, Germany.
3、微调(Fine-tuning)
参考论文:Minh-Thang Luong and Christopher D Manning. 2015.Stanford neural machine translation systems for spoken language domains. In Proceedings of the International Workshop on Spoken Language Translation, pages 76–79
阿里在WMT2018上的论文中提到他们 first train a model on a large out-of-domain corpus and then continue a few epochs only on a small in-domain corpus
注:out-of-domain 和 in-domain ,比如在新闻类的翻译模型中,先使用体育类语料进行训练,再用新闻类语料进行微调,这里体育类语料就是out-of-domain ,而新闻类语料为in-domain
4、模型集成(Model ensembling)
将多个模型进行集成,阿里的文章Alibaba’s Neural Machine Translation Systems for WMT18中提到了一种基于贪婪策略选择模型的的集成方法,称为Greedy Model Selection based Ensembling。定义了两个list,称为keep list,redemption list,先把第一个模型放到keep list,然后每次抽一个模型,将两个模型进行集成,如果bleu值高,就加入keep list,否则放入redemption list,然后keep list中的模型有一定几率被淘汰,redemption list中的模型有一定几率复活就这样。
5、重排序(reranking)
典型的端到端Seq2Seq,直接将解码(如beam search)搜索得分最高的结果作为输出。但很多时候,由于encoder-decoder模型存在误差,解码时得分最高的结果并不一定是最好的,重排序对这一问题做了优化。具体做法很简单,比如说,使用beam search解码,保留得分最高的前k个候选句子,然后,在解码得分的基础上,引入若干特征(如输出句子在外部语言模型上的概率得分、与输入句子的编辑距离),对这k个候选句子重新排序,然后选择新的得分最高的句子作为最终输出。
阿里在4中所提论文中还提到了一种基于贪婪特征选择的重排序方法,称为greedy feature selection based reranking。如图所示:
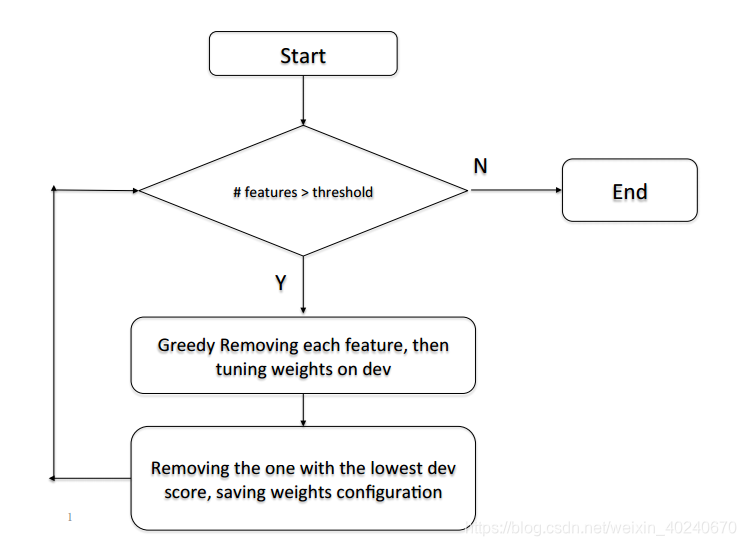

上表是挑选出的一些特征,全部特征为50+,每次挑出一个特征,利用的特征进行rerank,将得分最高的句子进行输出,得到一个BLEU值,最终选出使BLEU值降低程度最大的特征,认为是有效特征,直到剩下的特征数量少于阈值。
也可以自己手动挑一些特征出来给句子打分,算BLEU值,找BLUE值最高的,其实是一样的。
6、Swish
参考 :https://zhuanlan.zhihu.com/p/30332306
一种新的激活函数,形式为 f(x) = x · sigmoid(x)
7、exposure bias
所有基于seq2seq或RNN、序列模型、翻译模型都会遇到这一问题,在应用时,下一时刻的输出是和上一时刻的输出相关的,而由于没有标准答案,上一时刻犯下的错会迅速累积,称为exposure bias problem
As a result the errors made along the way will quickly accumulate. We refer to this discrepancy as exposure bias which occurs when a model is only exposed to the training data distribution, instead of its own predictions
使用Beam Search也会导致exposure bias,因为下一个词的概率是由上一个词决定的,出现错误会迅速累加。
这种错误是无法避免的,只能去减轻,或者利用后验去修正。
8、GELU激活函数
参考论文:GAUSSIAN ERROR LINEAR UNITS (GELUS)
BERT中用到的激活函数,全称为Gaussian error linear units,高斯误差线性单元。
GELU函数的定义为:

或者可以进行估计:


论文中实验证明,在好几个任务中都优于RELU
9、warm up(预热)
深度学习常用的方法,先用小的学习率(如0.01)进行训练,训练一定步数以后再转成正常的学习率(如0.1)
也可以用一些其他的策略,但基本都是先小后大这样。