# -*-coding:utf-8-*-
import arcpy
import fileinput
import os
# 采矿权坐标格式举例
# 1,3509447.04,37493933.70
# 2,3509447.05,37495583.71
# 3,3508597.04,37495583.72
# 4,3508597.04,37494783.71
# 5,3508336.97,37494583.71
# 6,3508247.03,37493933.70
# *,1300,-400,,1
#生成的shp图形存放目录
arcpy.env.workspace = r"F:\shp"
fc = "ck.shp"
# 如果工作空间下不存在该FeatureClass,那么新建FeatureClass
isexist = arcpy.Exists(fc)
if not isexist:
print fc + " 要素类不存在!"
# 创建插入游标,txt坐标文件名称就是项目名称
# cursor = arcpy.da.InsertCursor(fc, ["XMMC", "DKID", "DKMC", "MJ", "SHAPE@"])
cursor = arcpy.da.InsertCursor(fc, ["XMMC", "SHAPE@"])
# 遍历所有坐标文件
dirpath = r"F:\ck\\"
txtlist = os.listdir(dirpath)
txtname = ""
try:
# 遍历文件夹目录下所有的txt文件
for txtpath in txtlist:
txtname = txtpath.split(".")[0]
txt = fileinput.input(dirpath + txtpath)
rowstr = txt.readline()
fieldlist = []
# 外圈坐标,即外圈矿山
_xypolylist = []
# 挖空坐标,即挖空矿山
_wkpolylist = []
# 临时坐标
_tempxylist = arcpy.Array()
# 遍历单个txt坐标文件的坐标值
while rowstr:
fieldlist = rowstr.split(",")
fieldcount = len(fieldlist)
# 跳过txt坐标文件前面部门的属性描述
if fieldcount == 5:
isend = fieldlist[0]
iswk = fieldlist[4].replace("\n", "")
# 如果以*开头,标明该行是一个矿山(外圈或者内圈)结束
if isend == r"*" and (iswk == "1" or iswk == "0" or iswk == ""):
_xytemppolygon = arcpy.Polygon(_tempxylist)
_xypolylist.append(_xytemppolygon)
_tempxylist.removeAll()
print rowstr.replace("\n", "") # 一行末尾有换行符
rowstr = txt.readline()
continue
# 挖空矿山的标识是-1
elif isend == r"*" and iswk == "-1":
_wktemppolygon = arcpy.Polygon(_tempxylist)
_wkpolylist.append(_wktemppolygon)
_tempxylist.removeAll()
print rowstr.replace("\n", "") # 一行末尾有换行符
rowstr = txt.readline()
continue
# 读取坐标值
pnt = arcpy.Point()
# 依次为坐标点编号、纵坐标、横坐标
bh = fieldlist[0]
x = fieldlist[2].replace("\n", "")
y = fieldlist[1]
pnt.ID = bh
pnt.X = x
pnt.Y = y
_tempxylist.append(pnt)
print "第{0}个坐标是:{1},{2}".format(bh, y, x)
rowstr = txt.readline()
xypolynum = len(_xypolylist)
wkpolynum = len(_wkpolylist)
# 如果外圈矿山只有1个,挖空矿山1个或者多个,则执行裁剪,即交集取反
if xypolynum == 1 and wkpolynum >= 1:
poly = _xypolylist[0]
for j in range(wkpolynum):
poly = poly.symmetricDifference(_wkpolylist[j])
cursor.insertRow([txtname, poly])
continue
# 对于多个外圈矿山,1个或者多个挖空矿山,无法判断对哪个外圈矿山挖空
if xypolynum > 1 and wkpolynum >= 1:
print txtpath.decode("gbk") + ",无法判断挖空矿山!"
continue
# 遍历形成外圈地块
for i in range(xypolynum):
cursor.insertRow([txtname, _xypolylist[i]])
print txtpath.decode("gbk") + " is finished!"
except Exception as err:
# print (err.args[0]).decode("gbk")
print "请检查坐标格式是否正确,或者坐标存在自相交!"
else:
print "全部生成!"
del cursor
效果图如下:
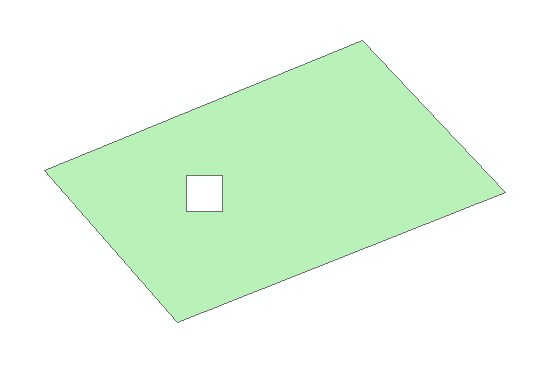
测试数据:
1,3271945.18,38561194.99
2,3272376.19,38562246.99
3,3271873.19,38562717.99
4,3271443.19,38561634.99
*,400,0,,1
5,3271928.18,38561662.99
6,3271928.18,38561782.99
7,3271808.18,38561783.00
8,3271808.18,38561662.99
*,400,0,,-1