前言
我们在编写一些自动化脚本的时候,为了方便,经常需要以txt 文件作为数据输入,今天就跟大家讨论一下如何对txt 文件进行读取并生成对应的列表等程序可操作的数据载体。

开始
1. 载入文件
这步就大家比较熟悉,文件操作中最基本的了。
因为我们只需要读取文件,并不需要写入文件,所以在这里指定mode="r" 为只读模式(默认)。
f = open("C:/foo.txt", "r",encoding='utf-8')
此时就有了这个txt 文件的数据输入流了。
2. 读取数据流
读取数据的方法主要有三个,分别是read()、readline()、readlines()
| 方法 | 作用 |
|---|---|
| read() | 从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| readline() | 读取整行,包括 “\n” 字符。 |
| readlines() | 读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 |
接下来简单展示一下这三种方法的区别:
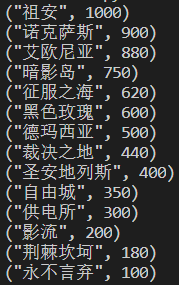
这是foo.txt 中的内容
("祖安", 1000)
("诺克萨斯", 900)
("艾欧尼亚", 880)
("暗影岛", 750)
("征服之海", 620)
("黑色玫瑰", 600)
("德玛西亚", 500)
("裁决之地", 440)
("圣安地列斯", 400)
("自由城", 350)
("供电所", 300)
("影流", 200)
("荆棘坎坷", 180)
("永不言弃", 100)
- read()
和txt 数据格式一致,返回str 类型数据
- readline()
只读取一行(包括换行),返回str 类型数据

- readlines()
全部读取,返回list 类型数据

3. 数据处理
根据上一步,我们可以得到多种形式的数据类型,从而根据我们的需求进行多种处理。
大家可以看到,我的foo.txt 中的数据是满足元组形式的,那我就试着将foo.txt 文件中的字符串类型数据转变成元组吧:
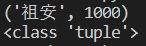
line = f.readline() # 读取一行
tu = eval(line) # 转为元组形式
print(tu)
print(type(tu))
输出:
若需要全部数据都逐行转变为元组,然后整体串成一个列表:
txt_tables = []
f = open("C:/foo.txt", "r",encoding='utf-8')
line = f.readline() # 读取第一行
while line:
txt_data = eval(line) # 可将字符串变为元组
txt_tables.append(txt_data) # 列表增加
line = f.readline() # 读取下一行
print(txt_tables)
之所以while 循环中的
f.readline()能够不断读取下一行,是因为当我们每次执行完一次该语句之后,文件输入流的指针都会移动到下一行的起始位,所以每次再次执行,都是从下一行的第一个字符开始读取。
输出:

4. 关闭文件
是的,不要忘了关闭文件流:
f.close()