周志华《机器学习》 学习笔记
最近开始学习机器学习,参考书籍西瓜书,做点笔记。
第九章 聚类
9.1 聚类任务
聚类是无监督学习中研究最多,应用最广的方法;
聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个簇;
分类后的每个簇的由使用者根据特征和需求命名;
9.2 性能度量
聚类的性能度量大致两类:将聚类结果于某个参考模型比较的外部指标;直接考察聚类结果而不利用任何参考模型的内部指标;
常用的聚类性能外部指标:Jaccard系数、FM指数、Rand指数;以上度量结果在[0,1]区间内,值越大越好;
常用的聚类性能内部指标:DB指数(DBI)、Dunn指数(DI);DBI值越小越好,DI越大越好;
9.3 距离计算
距离度量的基本性质:非负性(距离大于等于0)、同一性(当且仅当样本相同时距离为0)、对称性(dist(xi,xj)=dist(xj,xi))、直递性(三角不等式,两边和大于第三边);
闵可夫斯基距离(Lp范数):;
欧氏距离(p=2):;
曼哈顿距离(p=1):;
有序属性:能直接计算属性值的距离;
无序距离:不能直接计算属性值的距离;对无序属性性采用VDM;
将闵可夫斯基距离和VDM结合即可处理有序属性和无序属性混合的情况:
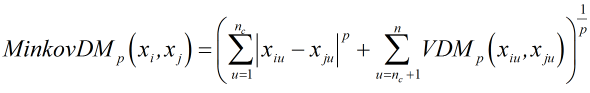
根据样本空间中不同属性的重要性不同,可以使用加权距离:
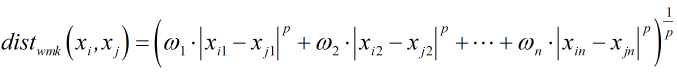
9.4 原型聚类
1.k均值算法(k-means)
k-means算法针对聚类所得簇划分最小化平方误差:;
其中是簇Ci的均值向量;
从公式中可以看出E值越小簇内样本相似度越高;
聚类收敛:聚类中心不再有变化、每个样本到对应聚类中心的聚类中心的距离值和不再有很大变化、迭代更新后的聚类结果保持不变;
举例参考书上对西瓜数据4.0的分析;
2.学习向量量化
学习向量量化(LVQ)试图找到一组原型向量刻画聚类结构,LVQ带有类别标记;
LVQ关键是在原型向量的更新,更新公式:;
则更新后的原型向量与样本xj的距离为:,从公式可以看出在更新后原型向量和样本xj更接近;
类似的,标记不同则增加距离:;
例题参考书籍;
3.高斯混合聚类
高斯混合聚类采用概率模型表达聚类原型;
对n维样本空间X中的随机向量x,若x服从高斯分布,则其概率密度函数:;
我们可以定义高斯混合分布:;
根据贝叶斯定理: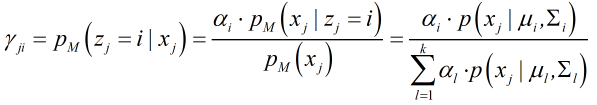
利用极大似然估计和EM算法,求出相应参数:
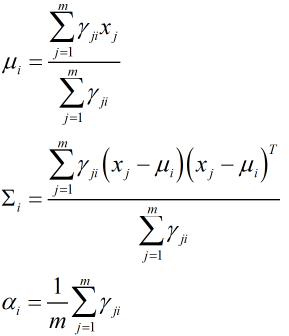
9.5 密度聚类
DBSCAN基于一组邻域参数来刻画样本分部紧密程度;
邻域、核心对象、密度直达、密度可达、密度相连概念;
DBSCAN中簇的概念:由密度可达关系导出的最大密度相连样本集合;
9.6 层次聚类
层次聚类试图在不同层次对数据集进行划分,从而形成属性的聚类结构;
AGNES是一种采用自底向上聚合策略的层次聚类算法;
AGNES将数据集中的每个样本看做一个初始聚类簇,然后在算法的每一步中找出距离最近的两个聚类簇进行合并,不断重复这个过程,直到达到预设的聚类簇个数;
计算聚类簇之间的距离:最小距离、最大距离、平均距离;
例题参考书上;
k-means算法和层次聚类对比:
1.k-means算法这种扁平聚类产生一个聚类结果,层次聚类能根据聚类程度不同有不同结果;
2.k-means算法需要指定聚类个数k,层次聚类不需要;
3.通常k-means要比层次聚类快;
第九章聚类是学到的第一个无监督学习方法,聚类中最重要的是距离的概念,即簇中距离小簇间距离大。在学习聚类的时候可以通过画图的方式便于理解,在高斯混合模型中使用较多概率统计的东西,有点不太容易理解,需要在补一补概率统计。
我的笔记做的比较粗糙,还请见谅。