周志华《机器学习》 学习笔记
最近开始学习机器学习,参考书籍西瓜书,做点笔记。
第十一章 特征选择与稀疏学习
11.1 子集搜索与评价
特征选择:从给定的特征集合中选择出相关特征子集的过程(重要的数据预处理过程);
无关特征:与训练任务无关的特征;冗余特征:包含的信息能从其他特征中推演出来;
子集搜索:前向、后向、双向;
子集评价:计算子集增益;
信息增益越大意味着特征自己包含的有助于分类的信息越多;
常见特征分类方法:过滤式、包裹式、嵌入式;
11.2 过滤式选择
对数据及进行特征选择,然后再训练学习器,特征选择过程与学习器学习过程无关;
Relief:特征子集的重要性由每个特征所对应的相关统计量分量之和决定;
相关统计量:;
Relief用于二分类问题,变体Relief-F能解决多分类问题;
pl为第l类样本在数据集D中所占比例;
11.3 包裹式选择
包裹式特征选择直接把最终要使用的学习器的性能作为特征子集的评价准则;
拉斯维加斯方法:可能给出解也可能不给出解;
蒙特卡罗方法:一定会给出解;
11.4 嵌入式选择与L1正则化
嵌入式特征选择:在学习器训练过程中自动的进行了特征选择;
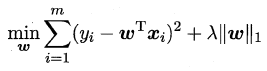
L2范数:倾向于分量取值尽量均衡,即非零分量个数尽量稠密;
L0、L1范数:倾向于分量取值稀疏,即非零分量个数尽量少;
L1范数和L2范数正则化都能有助于降低过拟合风险,但是L1范数更易于获得稀疏解;
11.5 稀疏表示与字典学习
当样本数据是一个稀疏矩阵时,对学习任务来说会有不少的好处,例如很多问题变得线性可分,储存更为高效等。这便是稀疏表示与字典学习的基本出发点。稀疏矩阵即矩阵的每一行/列中都包含了大量的零元素,且这些零元素没有出现在同一行/列,对于一个给定的稠密矩阵,若我们能通过某种方法找到其合适的稀疏表示,则可以使得学习任务更加简单高效,我们称之为稀疏编码(sparse coding)或字典学习;

其中B为字典矩阵,式中第一项希望能很好的重构x,第二项希望ai尽量稀疏;
11.6 压缩感知
目的:根据部分信息恢复全部信息;
压缩感知两个阶段:感知测量、重构恢复;
感知测量:对原始信号进行处理获得稀疏样本;
重构恢复:基于稀疏性从少量观测复原信号;
限定等距性:;
矩阵补全:;
第十一章特征选择与稀疏学习,本章书上介绍比较简单,也有很多理解不是很到位,其中每一块深入都有很深的学问在里面,在以后的应用学习中将加深对这一章介绍内容的理解,在学习的时候头脑里还是需要有一个大概的模型或者图才能更好的理解。
我的笔记做的比较粗糙,还请见谅。