Python中根据位置取值可以用.loc,.iloc, .ix,还可以通过每一行的索引和列的索引,把需要的行和列单独取出来
.iloc:根据标签的所在位置,从0开始计数,选取列,如果索引是数字,就使用.iloc
loc:根据DataFrame的具体标签选取列,.loc主要是针对字符串的,当索引是字符串时可以使用
一、当每列已有column name时,用 df [ 'a' ] 就能选取出一整列数据。如果你知道column names 和index,且两者都很好输入,可以选择 .loc
import numpy as np
import pandas as pd
df=pd.DataFrame(np.arange(0,200,2).reshape(10,10),columns=list('abcdefghij'))
print(df)
print (df.loc[[1,5],['a','b']])
输出了完整的df,以及第1行和第5行且column name为a和b的数据,由于没有命名index,所以数字0-9是DataFrame自动赋予的
二、如果column name太长,输入不方便,或者index是一列时间序列,更不好输入。那就可以选择 .iloc了。
import numpy as np
import pandas as pd
df=pd.DataFrame(np.arange(0,200,2).reshape(10,10),columns=list('abcdefghij'))
print (df.iloc[2,1])
print (df.iloc[:5,5])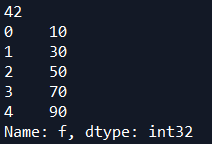
输出了第2行第1列的数据42,以及index为0-4第6列 f的数据。.iloc 使得我们可以对column使用slice(切片)的方法对数据进行选取。
三、.ix 的功能十分强大,它允许我们混合使用下标和名称进行选取。
df.ix [ [ ..1.. ], [..2..] ], 1框内必须统一,必须同时是下标或者名称,2框也一样。
import numpy as np
import pandas as pd
df=pd.DataFrame(np.arange(0,200,2).reshape(10,10),columns=list('abcdefghij'))
print (df.ix[[2,3],[1,2]])
但是一般情况下不建议采用。