
本作品采用知识共享署名-非商业性使用-禁止演绎 3.0 中国大陆许可协议进行许可。
介绍
Mathematics Genealogy Project是一个面向网络收集数学家家谱资讯的网站。网站上资料来源于该项目自身搜集与网友提供。资料包括数学家的学生,数学家的导师,毕业年份,毕业学校,国籍,研究领域等。目前收集到的资料将近20万笔,并且还在不断增加中。
我们从该网站上抓取所有(实际上并不是所有的)的数学家资料并绘制成网络图,旨在分析数学界中的聚类情况与师生间继承关系;同时还可研究数学科学的发展历程以及数学教育与国家经济发展和时代发展的关系,期望以这样的资料分析科学发展的模式和轨迹(实际并没有这么高大上)。
资料收集
所有的数学家资料是一棵树的结构,也可以用图表示,一个数学家就是一个节点。因此从一个数学家开始,遍历该数学家所有的学生以及他的导师,然后针对他的导师和每一个学生再重复上述步骤,与深度优先遍历类似。首先使用一个队列存储所有待遍历的节点(数学家),以此获取他的学生列表,导师列表,国籍,毕业学校,毕业年份,研究领域等。然后不断重复上述过程,直到队列为空为止。
资料收集过程使用python语言,使用了bs4和selenium来crawl资料,使用了networkx来构造图。定义了一个类Scientst来存储节点的属性。完整的代码见最后。
资料分析
最后收集了1871~2010年间的数学家关系图,原始数据一共64019个点。但有些节点缺少年份和国籍信息,最后分析时过滤掉没有年份属性和国家属性的数据,以每十年为一个阶段分析。下面选取几个时段进行分析。
1871-1890年
网络图如下图所示。箭头连接的两个节点表示两个数学家是师生关系,箭头指向的节点表示这个数学家是学生。此时德国在数学界的发展雄霸天下。
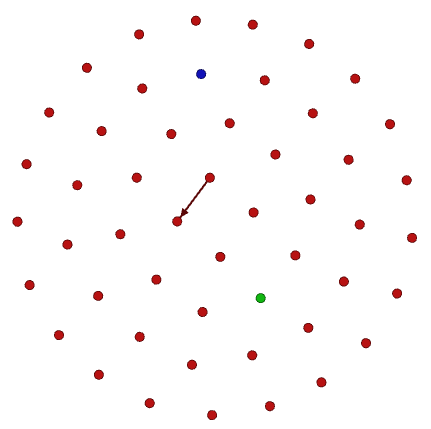
图中红色表示德国,绿色是波兰(只有一个点),蓝色是美国。
1871-1900年
此时正值一战前夕,德国数学家的比例仍占绝对优势,也可以看到一些德国数学家是某些美国数学家的指导教授。有趣的是后来国际数学学科的中心渐渐由德国偏向美国,而一些美国数学家的导师是德国人,或者说是后来很多德国数学家都移民去了美国?
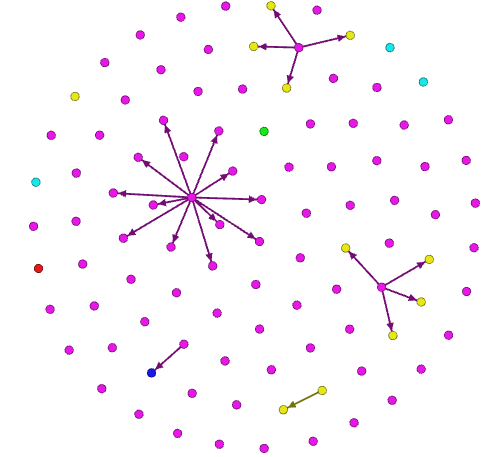

1871-1910年
一战前的十九世纪末期,产生了集合论形成了现代数学的基础。德国数学家D. Hilbert提出了著名的23个问题,几乎左右了本世纪数学发展的进程。其中大约有三分之二以解决或基本解决的问题都伴随着一个个新学科的发展。
如下图所示,上图是该时期的数学家图谱,下图是该图betweenness示意图,节点越大表示betweenness值越大。本时期的核心人物就是D. Hilbert,Klein (克莱因)和Minkowsiki (闵科夫斯基)。闵科夫斯基就是betweenness图中最大的节点。
betweenness示意图:

1871-1920年
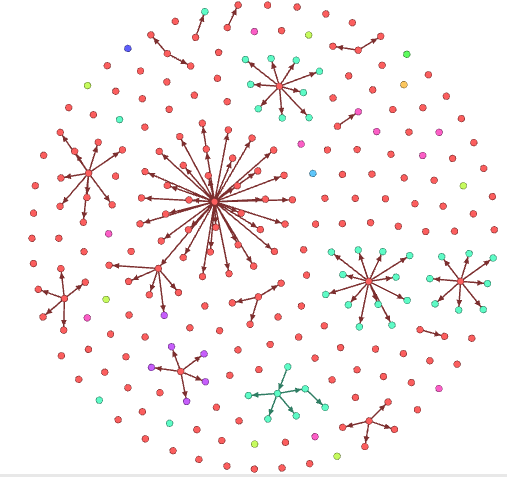
该时期恰逢一战爆发。图中绿色节点表示德国,红色是美国。betweenness图中节点最大的数学家名叫C.L. Ferdinand Lindemann,同时他也是这段时期所带学生最多的数学家,学生数量为45个,该记录直到1960年之后才被美国数学家打破。如下表所示。
表1:各时段各数学家学生数量
| out-degree | 1871~1900 | 1871~1910 | 1871~1920 | 1871~19300 | 1871~1940 | 1871~1950 | 1871~1960 | 1871~1970 | 1871~1980 | 1871~1990 | 1871~2000 | 1871~2010 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| largest out-degree | 12 | 35 | 43 | 45 | 45 | 45 | 45 | 51 | 63 | 65 | 65 | 105 |
| largest out-deg. name | C.L. Ferdinand Lindemann | C.L. Ferdinand Lindemann | C.L. Ferdinand Lindemann | C.L. Ferdinand Lindemann | C.L. Ferdinand Lindemann | C.L. Ferdinand Lindemann | C.L. Ferdinand Lindemann | Patrick Ledden(US) | David Blackwell | David Blackwell | David Blackwell | C.C.Jay Kuo |
可以清楚看到这段时期C.L. Ferdinand Lindemann的学生都是的国人,但其学生的学生有外国人(蓝色节点)。而之前提到的D. Hilbert就是C.L. Ferdinand Lindemann的学生。
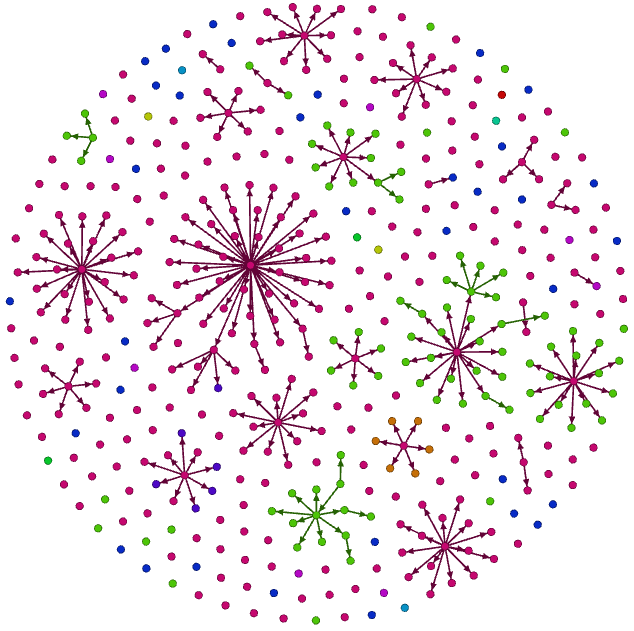
betweenness示意图:
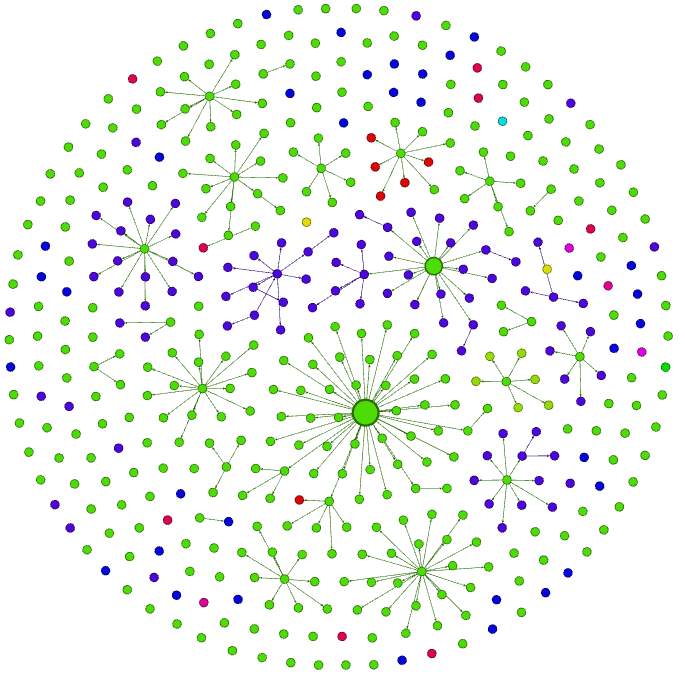
1871-1930年
一战结束,百废待兴。1920~1930年十年间,betweenness最大的数学家被Maxime Bocher取代。Maxime Bocher的betweenness最大的记录一直到1980年之后才被美国数学家Joseph Doob打破。如下表所示:
表2:各时段betweenness
| betweenness | 1871~1900 | 1871~1910 | 1871~1920 | 1871~19300 | 1871~1940 | 1871~1950 | 1871~1960 | 1871~1970 | 1871~1980 | 1871~1990 | 1871~2000 | 1871~2010 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| largest betweenness | 1355 | 3560 | 3560 | 7994 | 26152 | 93587 | 198013 | 337041 | 679789 | |||
| largest btw. name | C.L. Ferdinand Lindemann | Maxime Bocher | Maxime Bocher | Maxime Bocher | Maxime Bocher | Maxime Bocher | Maxime Bocher | Joseph Doob | Joseph Doob | Joseph Doob |

可推断假设,当所带学生群体中有外国人时,该节点的betweenness将有机会提升。根据该网络图的特性,betweenness比较高的节点可能有以下两个原因:
- 数学家所带学生中又有很多学生成为大学教授,进而形成若干小团体
- 数学家所带的学生有外国学生,如此该节点就有机会与其他国家的小团体相连
因此,某种程度而言,betweenness可以代表一个数学小圈子的繁荣状况。
1871-1940年
从图中可以看出,学成后一些美国数学家又带了很多美国学生,进而在最后提升了美国数学家人数所占之比例。
这个时期,美国数学家所占比例与德国数据学家人数比例逐渐缩小。推断:因为希特勒上台,德国政局动荡,使得大批德国数学家赴美,再加上之前德国数学家所带的美国学生,使得美国数学家数量可以赶超德国(?);或者,当时德国在集权统治下,有由于战争需要,科学发展繁荣,使得大批美国赴德学习(?)。但无论何种原因,此时恰逢二战爆发,世界数学中心开始由德国向美国转移。

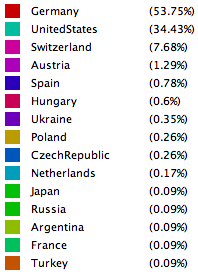
1871-1960年
这个时期第三次科技革命开始,加剧了资本主义各国之间发展的不平衡,使资本主义各国的国际地位发生了新的变化。并且社会主义国家在与西方资本主义国家抗衡的斗争中,贫富差距逐渐拉大,促进了世界范围内社会生产关系的变化。
或许近现代数学的开端是在德国,或是德国家里了系统的近现代数学体系?而后被美国反超,而且德国被远远甩在美国后面。

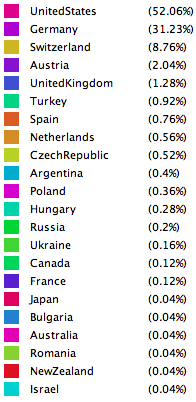
1871-2000年
此时美国数学家比例已经占绝对优势。

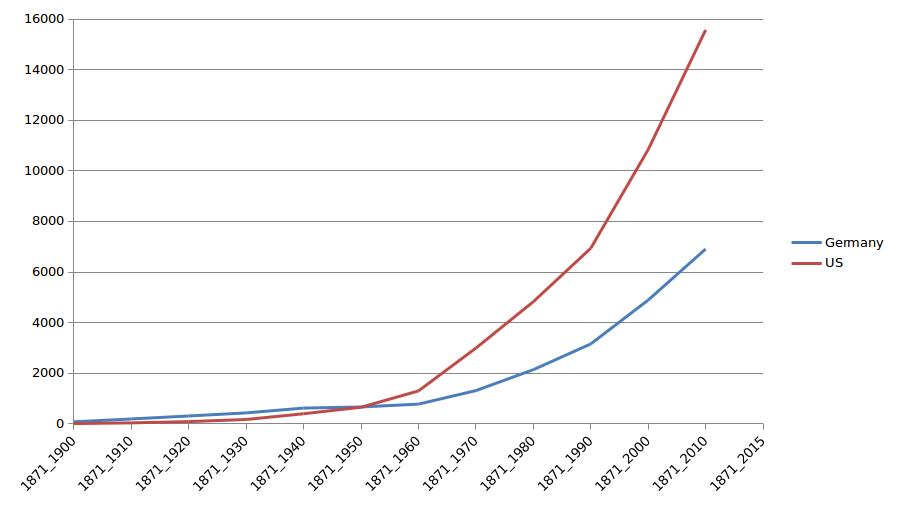
1871-2010年间数学家数量变化
下图是1871至2010年之間每隔10年的結點數量曲線圖。由圖可知該網站收錄的數學家呈指數遞增。表明數學學科的發展越來越繁榮,也越來越細分。
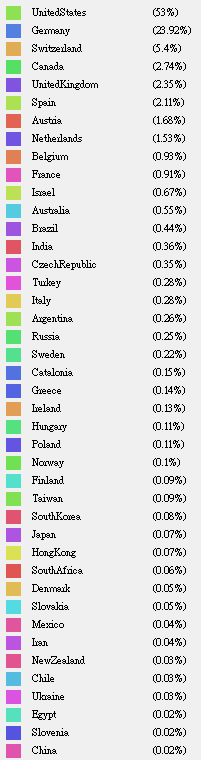
中国数学家情况
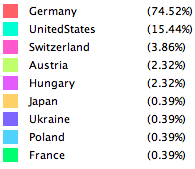
该网站上收录的中国数学家共135个(抓取的数量),占全世界的比例相当少。想必是大部分中国数学家后来都已转国籍。如下图,不同颜色表示不同的毕业学校。
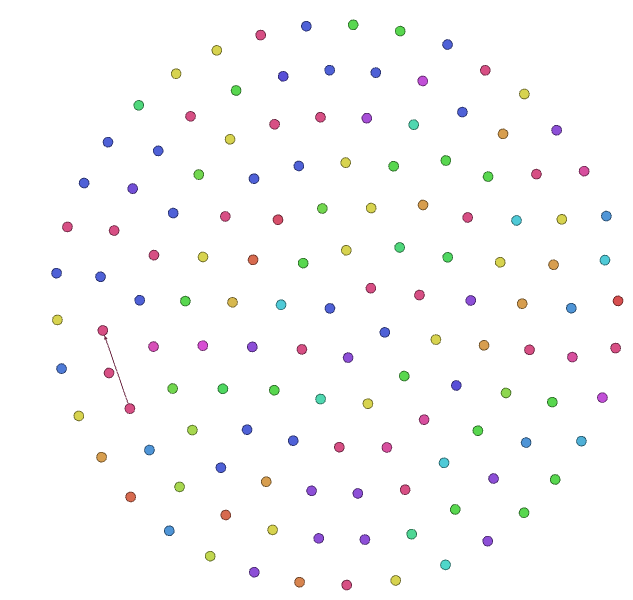
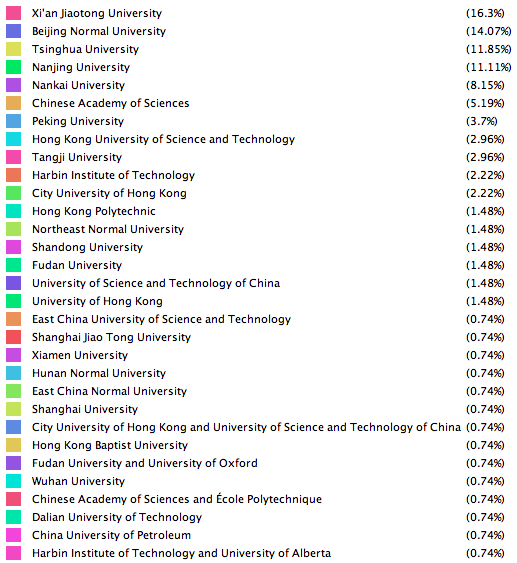
台湾数学家
台湾数学家一共60个(抓取的数量),大部分毕业于台湾大学。从图上看中国和台湾两个地区的数学家都喜欢单打独斗,基本没有形成一个完整的社群网络。而且基本都毕业与台湾的学校。而实际上台湾知名院校的教授几乎都有留学经历,因此该部分值得进一步讨论。
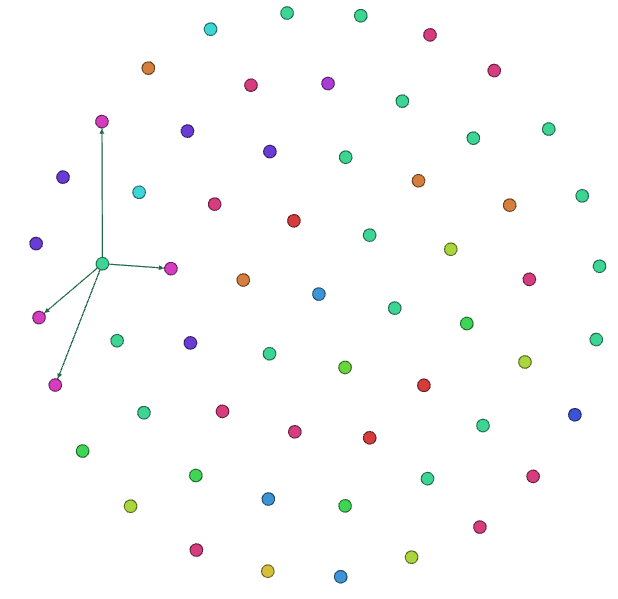
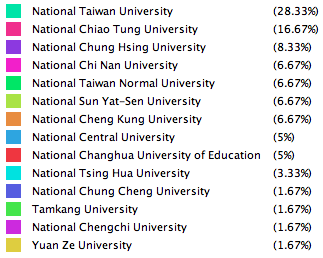
缺陷
该分析作为一个简单的研究实例,实际上有许多缺陷
- betweenness的选择。实际上数学家关系图应该是一个有向图,但是有向图的betweenness并不容易分析。因此在分析中betweenness的计算均是基于无向图的计算
- 有些数据未能抓取到国籍与年份信息,也未能抓取该网站的所有数据,造成数据集不完整,影响分析。
- 不同年代的网络尺度不同,对closeness与betweenness进行归一化比较恰当。但是归一化后会出现多个最大值一样的情况,给分析造成不便,考虑到并没有进行横向比较,因此最后没有计算归一化的值
资料抓取代码python
版本:python 2.7
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from selenium import webdriver
import urllib2
import time
from collections import deque # 隊列
import networkx as nx
#import matplotlib.pyplot as plt
from networkx.readwrite import json_graph
import json
t = time.time()
today = str(time.strftime('%m/%d', time.localtime(t)))
spans = list()
titles = list()
hrefs = list()
sciDict = {} # 空字典,用於存放整個scientist的網絡結構,key為id
baseUrl = "http://genealogy.math.ndsu.nodak.edu/"
# seedID = 'id.php?id=7298' # 從David Hilbert開始
seedID = 'id.php?id=17946' # 從Gustav Peter Lejeune Dirichlet開始,測試從不同的人開始中心性的排序是否會有所不同
class Scientst(object):
"""docstring for Scientst"""
def __init__(self):
self.idURL = ""
self.name = ""
self.year = ""
self.num = ""
self.country = ""
self.school = ""
def readPage(url):
webURL = urllib2.urlopen(baseUrl + url)
content = webURL.read()
soup = BeautifulSoup(content)
return soup
def readPage2(scientistID):
webURL = urllib2.urlopen(baseUrl + scientistID)
content = webURL.read()
soup = BeautifulSoup(content)
return soup
def isEighteen(soup):
return soup.find(True, {'class':['over18-notice']})
def clickSubmit(board):
driver = webdriver.Firefox()
driver.get("https://www.ptt.cc/bbs/" + board + "/index.html")
button = driver.find_element_by_class_name('btn-big')
button.click()
soup = BeautifulSoup(driver.page_source)
driver.quit()
return soup
def getDivInformation(div):
span = div.findChildren('span')[0].text
try:
if int(span) >= 80 and len(div.findChildren('a')) > 0:
href = div.findChildren('a')[0].attrs['href']
title = div.findChildren('a')[0].text
spans.append(int(span))
titles.append(title)
hrefs.append(href)
except:
if len(div.findChildren('a')) > 0:
href = div.findChildren('a')[0].attrs['href']
title = div.findChildren('a')[0].text
spans.append("爆")
titles.append(title)
hrefs.append(href)
# 獲取一個scientist頁面中該scientist的信息
# 其它信息很難取,先取國家
def getSciInfo(idURL):
country = ""
year = ""
soup = readPage(idURL)
divs = soup.findAll('div', {"id": "paddingWrapper"})
if len(divs) > 0:
img = divs[0].findChildren('img')
if len(img) > 0:
country = img[0]['title']
else:
country= ""
spans = divs[0].findChildren('span')
if len(spans) > 0:
year = spans[0].text
year = year[-4:] # 年份為text的最後四位
else:
country = ""
year = ""
sciItem = Scientst()
sciItem.country = country
return sciItem
def getCountry(idURL):
country = ""
soup = readPage(idURL)
img = soup.findAll('div', {"id": "paddingWrapper"})
if len(img) > 0:
img2 = img[0].findChildren('img')
if len(img2) > 0:
country = img2[0]['title']
else:
country= ""
else:
country = ""
return country
# 在學生的頁面找該學生的advisor,因此傳入學生的id
def findAllAdvisor(idURL):
advList = list()
soup = readPage(idURL) # 打開這個學生的頁面,advisor在該學生的頁面中
divs = soup.findAll('div', {"id": "paddingWrapper"})
if len(divs) > 0:
advisorPras = divs[0].findChildren('p') # 有很多個p
for advisorP in advisorPras:
advisorTag = advisorP.text
if "Advisor" in advisorTag : # 多個advisor都在同一個p標籤下
advisorA = advisorP.findChildren('a')
for advisorInfo in advisorA: # 取每一個advisor的信息
idURL = advisorInfo.attrs['href']
name = advisorInfo.text
sciItem = getSciInfo(idURL)
sciItem.name = name
sciItem.idURL = idURL
advList.append(sciItem)
break
return advList
def findAllStudent(soup):
sciList = list()
trows = soup.findAll('tr') #找到table中的每一行
for trow in trows:
tds = trow.findChildren('td')
if len(tds) <= 0:
continue
else:
idURL = tds[0].findChildren('a')[0].attrs['href']
scientistName = tds[0].text
school = tds[1].text
year = tds[2].text
descendants = tds[3].text
sciItem = Scientst()
sciItem.idURL = idURL
sciItem.name = scientistName
sciItem.year = year
sciItem.num = descendants
#sciItem.country = country # 國家信息應針對每個scientist找一遍
sciItem.school = school
sciList.append(sciItem)
return sciList
def currentPageArticleGetter(soup):
divs = soup.findAll(True, {'class':['r-ent', 'r-list-sep']})
for div in divs:
if div.attrs['class'][0] == "r-list-sep":
break
elif len(div.findChildren('span')) > 0:
getDivInformation(div)
def previousPageArticleGetter(soup, flag):
for link in soup.findAll(True, {'class': 'btn wide'}):
if '上頁' in str(link):
soup = readPage(link.get('href'))
for div in soup.findAll(True, {'class':['r-ent', 'r-list-sep']}):
if div.attrs['class'][0] == "r-list-sep":
break
elif len(div.findChildren('span')) > 0 and str(div.find(True, {'class': 'date'}).text)[1:] in today:
getDivInformation(div)
elif str(div.find(True, {'class': 'date'}).text)[1:] not in today:
flag = 1
return soup, flag
def articleFilter(soup):
flag = 0
currentPageArticleGetter(soup)
while flag == 0:
soup, flag = previousPageArticleGetter(soup, flag)
####################################################################
d = deque() # student隊列
advQueue = deque() # advisor隊列
G = nx.DiGraph()
G.add_node(seedID) # 添加第一個scientist,該scientist的信息需要完善
sciInfo = {}
sciInfo['name'] = ""
sciInfo['year'] = ""
sciInfo['school'] = ""
sciInfo['country'] = ""
sciDict[seedID] = sciInfo
soup = readPage(seedID)
sciList = findAllStudent(soup)
# 添加第一個scientist的advisor信息
advisorList = findAllAdvisor(seedID)
for advisor in advisorList:
advQueue.appendleft(advisor) # advisor入隊列,一般是1到2個advisor
G.add_node(advisor.idURL, name = advisor.name, year = advisor.year, school = advisor.school, num = advisor.num, country = advisor.country)
G.add_edge(advisor.idURL, seedID)
index = 1
errorCount = 0
printstr = ""
# seedID是advisor,目前queue中的每個sci都是seedID的學生,添加邊
for sci in sciList:
d.appendleft(sci)
G.add_node(sci.idURL, name = sci.name, year = sci.year, school = sci.school, num = sci.num, country = sci.country)
index += 1
printstr = sci.idURL + " " + str(index)
print printstr
G.add_edge(seedID, sci.idURL)
# 將學生信息加入圖中
while d:
seedSci = d.pop()
try:
soup = readPage(seedSci.idURL) # 打開一個scientist的頁面
# 獲取學生信息
if seedSci.num == "": # 該scientist沒有學生,但是要取該scientist的國家信息
continue
sciList = findAllStudent(soup)
for sci in sciList:
# 先獲取該scientist的advisor信息
advisorList = findAllAdvisor(sci.idURL)
for advisor in advisorList:
if advisor.idURL == seedSci.idURL: # 如果這個advisor和seedSci是同一個人,則跳過;否則加入隊列,因為有些scientist可能有一個以上的advisor
continue
advQueue.appendleft(advisor) # advisor入隊列,一般是1到2個advisor
G.add_node(advisor.idURL, name = advisor.name, year = advisor.year, school = advisor.school, num = advisor.num, country = advisor.country)
G.add_edge(advisor.idURL, sci.idURL)
country = getCountry(sci.idURL) # 獲取每個scientist的國家信息
sci.country = country
d.appendleft(sci) # 入隊列
G.add_node(sci.idURL, name = sci.name, year = sci.year, school = sci.school, num = sci.num, country = sci.country)
index += 1
printstr = sci.idURL + " " + str(index)
print printstr
G.add_edge(seedSci.idURL, sci.idURL)
except Exception, e:
continue
# 將advisor信息加入圖中
# advisor的信息可能不完整(例如沒有num,沒有school,沒有year等),因此需要重新從頁面中讀取學生信息
while advQueue:
seedSci = advQueue.pop()
try:
soup = readPage(seedSci.idURL) # 打開這個advisor的頁面
sciList = findAllStudent(soup) # 獲取這個advisor所有的學生
for sci in sciList:
if not G.has_node(sci.idURL):
G.add_node(sci.idURL, name = sci.name, year = sci.year, school = sci.school, num = sci.num, country = sci.country)
index += 1
printstr = sci.idURL + " " + str(index)
print printstr
if not G.has_edge(seedSci.idURL, sci.idURL):
G.add_edge(seedSci.idURL, sci.idURL)
except Exception, e:
continue
data = json_graph.node_link_data(G)
filePath = "scientistNetwork_test.txt"
with open(filePath, 'w') as outfile:
json.dump(data, outfile)
print "Finished!"
# pos = nx.random_layout(G)
# nx.draw_networkx(G, pos=pos, width = 0.5, node_size = 15, with_labels = False, alpha = 0.5)
# plt.show()