**
使用python读取wav格式文件
**
- 基本概念
【采样频率】
即取样频率, 指每秒钟取得声音样本的次数。采样频率越高,声音的质量也就越好,声音的还原也就越真实,但同时它占的资源比较多。由于人耳的分辨率很有限,太高的频率并不能分辨出来。
【采样位数 | 量化精度】
即采样值或取样值(就是将采样样本幅度量化)。它是用来衡量声音波动变化的一个参数,也可以说是声卡的分辨率。它的数值越大,分辨率也就越高,所发出声音的能力越强。
每个采样数据记录的是振幅, 采样精度取决于采样位数的大小:
1 字节(也就是8bit) 只能记录 256 个数, 也就是只能将振幅划分成 256 个等级;
2 字节(也就是16bit) 可以细到 65536 个数, 这已是 CD 标准了;
4 字节(也就是32bit) 能把振幅细分到 4294967296 个等级, 实在是没必要了.
【通道数】
处理的音频主要为单通道和双通道。
即声音的通道的数目。常有单声道和立体声之分,单声道的声音只能使用一个喇叭发声(有的也处理成两个喇叭输出同一个声道的声音),立体声可以使两个喇叭都发声(一般左右声道有分工) ,更能感受到空间效果,当然还有更多的通道数。
- 相关方法
- 读取方法
import wave
import numpy as np
import pylab as plt
#打开wav文件 ,open返回一个的是一个Wave_read类的实例,通过调用它的方法读取WAV文件的格式和数据。
f = wave.open(r"/usr/local/java/wav_audio/car_20_si464.wav", "rb")
#读取格式信息
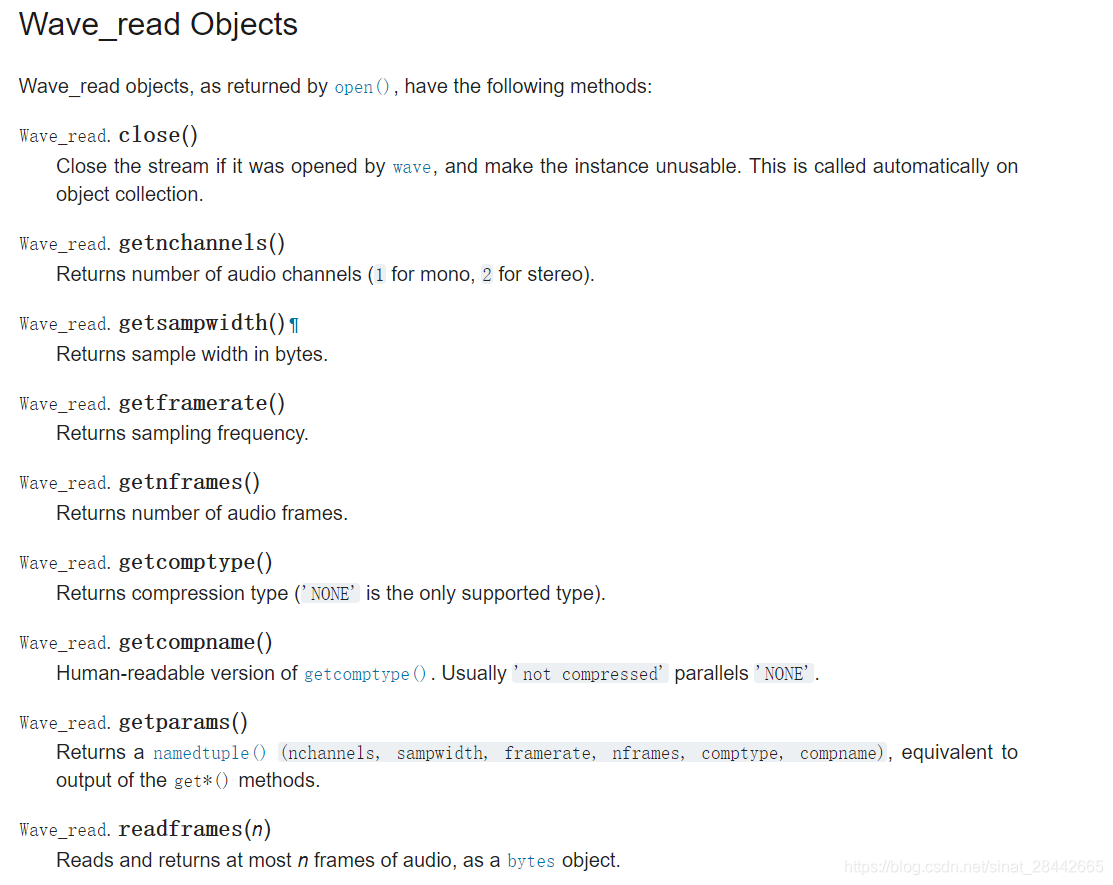
#一次性返回所有的WAV文件的格式信息,它返回的是一个组元(tuple):声道数, 量化位数(byte单位), 采样频率, 采样点数, 压缩类型, 压缩类型的描述。wave模块只支持非压缩的数据,因此可以忽略最后两个信息
params = f.getparams()
nchannels, sampwidth, framerate, nframes = params[:4]
#读取波形数据
#读取声音数据,传递一个参数指定需要读取的长度(以取样点为单位)
str_data = f.readframes(nframes)
f.close()
#将波形数据转换成数组
#需要根据声道数和量化单位,将读取的二进制数据转换为一个可以计算的数组
wave_data = np.frombuffer(str_data,dtype = np.int8)
#将wave_data数组改为2列,行数自动匹配。在修改shape的属性时,需使得数组的总长度不变。
wave_data.shape = -1,2
#转置数据
wave_data = wave_data.T
#通过取样点数和取样频率计算出每个取样的时间。
time=np.arange(0,nframes)/framerate
#print(params)
plt.figure(1)
plt.subplot(2,1,1)
#time 也是一个数组,与wave_data[0]或wave_data[1]配对形成系列点坐标
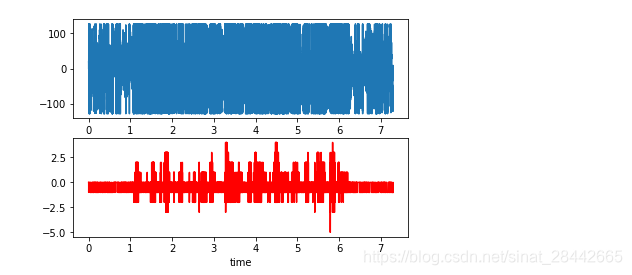
plt.plot(time,wave_data[0])
plt.subplot(2,1,2)
plt.plot(time,wave_data[1],c="r")
plt.xlabel("time")
plt.show()
备注:
该代码中主要注意问题:
wave_data = np.fromstring(str_data,dtype = np.int8)
fromstring 被替换为 frombuffer
np.int8 需要根据音频的量化精度8bit 、16bit 来确定转化为int8 或者int16
此处为个人理解,有不对的地方,还望指正,多谢!
效果截图: